Introduction to Concurrency
Motivation
The real world contains actors that execute independently of, but communicate with, each other. In modeling the world, these concurrent executions have to be composed and coordinated. Here are some examples:
- Railway Networks (note shared sections of track)
- Gardening (people rake, sweep, mow, plant, etc.)
- Machines in a factory (activities must be serialized)
- Banking systems
- Travel reservation systems
- Multiplayer games
- Well coordinated teams or societies (Awesome example)
- Your daily routines (are you good at multitasking?)
- The brain — the mind, really — as shown in Minsky’s Society of Mind
When we build concurrent systems in software, we write each of the independent activities as separate programs or subprograms. The operating system, or underlying programming language, or both, provides mechanisms and services to handle the coordination and communication. In the case of concurrent programs, we have two forms:
- Multiprogramming, which is simply running a lot of applications concurrently. The operating system multiplexes their execution on available processors. For example on one laptop you can simultaneously be:
- downloading a file
- listening to streaming audio
- streaming a movie
- having a clock running
- chatting
- analyzing data from some weird experiment
- printing something
- running a simulation
- typing in a text editor
- running a web server, sendmail, and other daemons
- Pipes, which are a way to connect the output of one program to the input of another. For example, you can run a command that sorts a file and then removes duplicates, and then formats the output for printing:
$ sort | uniq | format | print
Again, these programs don't know about each other, but they are coordinated by the operating system to run concurrently. If they had to know about each other, they would have been almost impossible to write.Exercise: Read about the Unix pipeline and the Unix philosophy. What are the key ideas? How do they relate to concurrency?
In addition to distinct programs, we may also write single programs that have multiple internal actors (each of which are conceptually different), such as:
- Simulation programs, in which each actor is a separate entity in the simulation (e.g., a flock of birds, a herd of cattle, a group of people)
- High volume servers, in which multiple clients are serviced at the same time (either truly in parallel on different computers or with interleaved execution) to give the appearance of responsiveness
The big idea is that the actors are independent entities, with agency.
Concurrency is about independent activitiesThe key concept here is independence. The various actors, or tasks, have their own independent behavior. A concurrent system is structured around these independent actors and tasks, and their communication and coordination.
Whether the activities happen simultaneously or not is a different question. If they do, that’s parallelism. Concurrency is the broad, overarching topic. Things like parallelism, distribution, and asynchronicity are subtopics.
A different kind of concurrency occurs not between separate conceptual tasks, but within an individual task. A single task can be broken down into parts that can be executed concurrently, often on parallel hardware:
- The expression $(ab+cd^2)(g+fh)$ can be evaluated in four clocks:
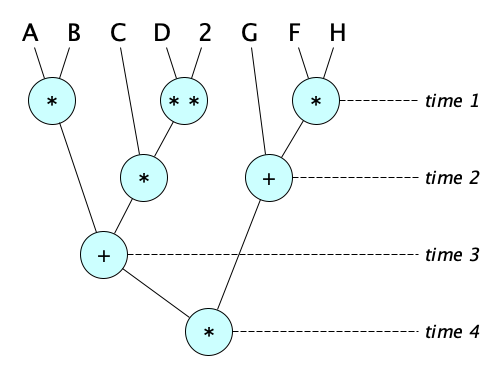
- Mergesort
- Quicksort
- Operating on independent slices of an array
-- Each of the K processors or execution units can work on the -- loop body for a specific value for I, so the entire loop can -- be executed in ceil(N/K) "steps". for I in 1..N loop D[I] := A[I] + B[I] * C[I] end loop - Computing primes (can divide each candidate in parallel)
- Checking equality of leaf sequences in trees
- Computing $n \choose k$ (view as a tree to see the parallelism)
- Video processing jobs
- Machine learning jobs
Because problem decomposition into similar subtasks is so amenable to execution on multiple cores or computers, it is this kind of concurrency that is often most associated with parallelism. Here’s a short video with a good explainer on the differences between concurrency and parallelism:
And, finally, here are some hardware examples of concurrency:
- A single processor can have multiple execution pipelines (but only one set of registers)
- A processor can have multiple cores (multicore)
- A computer can have multiple processors
- A network can have multiple computers (e.g. clusters, grids)
- An internet has multiple networks
Why Study Concurrency?
Because reasons.
- Modeling. Real world systems are naturally concurrent, and we do often care about modeling the real world.
- Usefulness. Concurrency is useful in multicore, multiprocessor and distributed computer systems, leading to:
- Increased performance for compute-bound tasks
- Increased throughput for I/O-bound tasks (such as responsive user interfaces)
- Better resource utilization (e.g., CPU, memory, network)
- Increased reliability (fault tolerance)
- Better designs for specialized processors (graphics, communication, encryption, machine learning, etc.)
- Necessity. Some applications, like email, are inherently distributed; we cannot write them, or even think about them, in any other way.
- Superior Program Structure. We can write code for the different tasks and let some separate engine schedule the tasks. It is not the application programmer's job to worry about the scheduling.
Example: It's nice when writing code to mine data, analyze telemetry, write massive files to disk, or produce frames for a movie, to not have to chunk up your code and shove in checks for the keyboard and mouse and other devices.Example: When writing a word processor, it's a lot simpler to write separate tasks for
- reading keystrokes and collecting characters into words
- collecting words to fill a line
- hyphenating where necessary
- adding spacing to justify with right margin
- inserting page breaks where necessary
- checking spelling
- saving (periodically)
Challenges
Concurrent programs are much harder to write than nonconcurrent programs. A nonconcurrent program has only one line of execution. A concurrent program has more than one. Why is this significant? Consider two separate processes: $P_1$ with instruction sequence $[A,B,C]$ and $P_2$ with sequence $[x,y]$. Then we have to consider 10 interleavings:
[A B C x y] [A B x C y] [A B x y C] [A x B C y] [A x B y C] [A x y B C] [x A B C y] [x A B y C] [x A y B C] [x y A B C]
The number of interleavings for two line, one with $m$ instructions and one with $n$ instructions is $m+n \choose n$ — which you probably know is $\frac{(n+m)!}{n!m!}$.
To show a concurrent program correct, we have to show it correct for all possible interleavings of the separate lines of execution.
If a program is supposed to terminate, there are two kinds of correctness criteria:
- Partial Correctness
- If the preconditions hold and the program terminates, then the postconditions will hold.
- Total Correctness
- If the preconditions hold, then the program will terminate and the postconditions will hold.
Again, for concurrent programs, these definitions must hold for all possible interleaved execution sequences.
For programs that are not expected to terminate, we have to write correctness criteria in terms of properties that must always hold (safety properties) and those that must eventually hold (liveness properties). Both are important: a program that does nothing is safe: it never screws up.
Safety
Here's an example of how some interleavings can produce correct results and others produce incorrect results. First consider two line:
| Line 1 | Line 2 |
|---|---|
| Transfer \$50 from account $A$ to account $B$ | Deposit \$100 to account $B$ |
Instructions:
|
Instructions:
|
Suppose account $A$ initially has \$500 and $B$ has \$700. We expect, after the transfer and the deposit, for $A$ to have \$450 and $B$ to have \$850. But consider the interleaving $[A B x C D E y F z]$:
| Instruction | Account A value | Account B value | Value in R0 | Value in R2 |
|---|---|---|---|---|
| — | 500 | 700 | — | — |
| A | 500 | |||
| B | 450 | |||
| x | 700 | |||
| C | 450 | |||
| D | 700 | |||
| E | 750 | |||
| y | 800 | |||
| F | 750 | |||
| z | 800 |
Disaster! The program is incorrect, as the postconditions failed to hold. In particular, $50 completely disappeared. Here’s the technical cause: there was contention for a shared resource. Line-2 wiped out Line-1's transfer.
Does this kind of thing happen a lot? Oh yeah. And it even has a name.
Race Conditions
A race condition (a.k.a. race hazard, or just race) is a property of concurrent code in which the result depends on the relative timing of events in the lines of execution. If all of the possible results are okay, the race condition is benign.
Races are almost always caused by lines “stepping on each other” and are addressed by ensuring we don’t have any problematic interleaving. In this particular example, we need to define a (safety) property that multiple lines will never update the same account at the same time. We can restrict ourselves to only safe interleavings by identifying sequences of statements that must be done all-at-once.
Critical Regions
In terms of the interleaved instruction sequence model, we avoid races by chunking subsequences into a single atomic instruction.
- $[ABC\quad DEF\quad xyz]$
- $[ABC\quad xyz\quad DEF]$
- $[xyz\quad ABC\quad DEF]$
loop
x += dx;
y += dy;
...
end loop
and the rendering line works like this:
loop
clear();
drawBackground();
drawShipAt(x, y);
swapBuffers();
...
end loop
you can easily imagine drawShipAt getting executed after $x$ is adjusted but before $y$ is adjusted, drawing the ship at a position it was never supposed to be at. We have to do both updates in a critical region.
We can enforce critical regions by either (1) adopting a model called cooperative multitasking where lines of execution mark exactly those points where they may yield to other lines, (2) implement a locking strategy, or (3) adopt something called software transactional memory.
Locking is by far the most common, and looks something like this:
// ...
doNonCriticalStuff
ENTRY_PROTOCOL
doCriticalRegion
EXIT_PROTOCOL
doNonCriticalStuff
// ...
where:
ENTRY_PROTOCOLwaits for the conditions to be safe to enter the critical region (conceptually: acquires a lock)doCriticalRegionis code that must be executed in mutual exclusionEXIT_PROTOCOLinform others you are done with your critical section, so they know they can try to enter their critical section if they're currently waiting (conceptually: releases a lock)doNonCriticalStuffis code that can be executed in parallel with the non-critical code of other execution lines
If used properly, locks do prevent race conditions, but introduce complexities of their own. This greatly adds to the difficulty of writing safe concurrent code.
Deadlock
Two lines are deadlocked if each is blocked waiting for an event that only the other blocked line can generate.
Livelock
Livelock occurs when no progress is made because each line tries to enter its critical section, then times out, then tries again, then times out, and so on, forever.
Starvation
A line is starved when it is prevented from entering its critical section because the other lines conspire (or appear to be conspiring) to lock it out.
Failure in the Absence of Contention
A (poorly designed) system is said to fail in the absence of contention when a line can't enter its critical section unless another line is waiting to enter its critical section.
Reliability
What if a line is interrupted, is suspended, or crashes inside its critical section? Shudder. In the middle of the critical section, the system may be in an inconsistent state (remember the example of updating a ship's coordinates?). Not only that, if the line is holding a lock and dies, then no other line waiting on that lock can proceed! Critical sections have to be treated as transactions and must always be allowed to finish.
Developers must ensure critical regions are very short and always terminate.
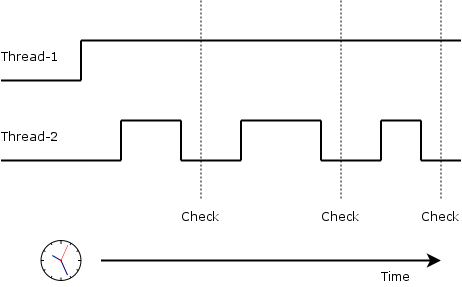
Liveness
Liveness is the property of a system that says that certain properties must eventually hold. That is, live systems show that things are progressing without starvation. Liveness properties include:
- Weak Fairness
- If a line continually makes a request it will eventually be granted.
- Strong Fairness
- If a line makes a request infinitely often it will eventually be granted.
It is possible to be weakly fair but not strongly fair:
Here are a couple strategies that a scheduler can use to help achieve fairness:
- Linear Waiting
- If a line makes a request, it will be granted before any other line is granted a request more than once.
- FIFO
- If a line makes a request it will be granted before any other line making a later request.
Definitions
Now that we have a taste how complex concurrency can be, we know it’s really important to have a concise and accurate vocabulary to help organize this vast field. Here are some concrete terms that are really, really important to understand (and distinguish from each other).
The first three terms are three you really need to be careful with, as they are often confused with each other:
- Program
- The actual source code for a process or processes. Programs are static entities.
- Process
- A unit of program execution as seen by an operating system. Processes tend to act like they are the only thing running. A process has its own address space, file handles, security attributes, threads, etc. The operating system prevents processes from messing with each other. Processes are dynamic entities.
- Thread
- A sequential flow of control within a process. A process can contain one or more threads. Threads have their own program counter and register values, but they share the memory space and other resources of the process.
Here are ways that software is executed:
- Multiprogramming / Multiprocessing
- Concurrent execution of several programs on one computer.
- Multithreading
- Execution of a single program with multiple threads.
These are important abstractions:
- Parallelism
- Truly simultaneous execution or evaluation of things.
- Concurrency
- The coordination and management of independent lines of execution. These executions can be truly parallel or simply be managed by interleaving. They can communicate via shared memory or message passing. (Rob Pike's definition: “the composition of independently executing computations”)
- Distribution
- Concurrency in which all communication is via message passing (useful because shared memory communication doesn’t scale to thousands of processors).
The activity that people do is:
- Concurrent Programming
- Solving a single problem by breaking it down into concurrently executing processes or threads.
Concurrent programming requires use to look at:
- Shared Resource
- An entity used by more than one thread but one that should only be operated on by one thread at a time.
- Synchronization
- The act of threads agreeing to coordinate their behavior in order to solve a problem correctly. (This usually means that thread $A$ will block and wait until thread $B$ performs some operation.)
Synchronization is hard because of things we wish to avoid:
- Deadlock
- Two threads are blocked, waiting for each other to release a resource that they need. So neither can proceed.
- Starvation
- A thread is waiting for a resource that is always given to other threads.
- Livelock
- Two threads are waiting for each other to release a resource. They keep trying to resolve their impasse, but never succeed.
- Race Condition
- Two threads are trying to access a shared resource at the same time. The result is dependent on the order of execution.
When crafting concurrent programs we strive for:
- Safety
- Nothing bad happens.
- Liveness
- Something good eventually happens.
- Correctness
- Nothing bad happens and something good eventually happens.
- Efficiency
- There is no waste of computing resources.
- Fault Tolerance
- The system can continue to operate even if some of its parts fail.
Theories
Definitions are a good start, but there is so much more to learn. Good theories can help.
Theories (organized bodies of knowledge with predictive powers) help us understand the state of the art and enable growth. People have created a number of process algebras and process calculi to describe concurrent systems mathematically.
Concurrent System Design
To design an effective concurrent system, one must know various architectural strategies, various paradigms to carry out concurrent execution, and be able to frame the various design challenges.
Architecture
There are three high-level approaches to modeling concurrent systems:
Distributed
Multiple independent processes with no shared memory, communicating only via message passing.
Multi-
Threaded
Multiple threads share memory, so require locks. Generally, a single process can have multiple threads.
Event
Queue
Only a single thread exists! A single loop reads from the event queue and invokes the handlers.
Naturally, in a large enough system, some mixing can occur.
The “threads vs. events” issue is a big one. Which is better? Or when is one better than the other, if ever? Read this neutral analysis of both styles.
Paradigms
When we move from thinking about high-level conceptual architecture of systems down to doing actual programming, various programming paradigms are helpful to consider. Each comes with its own set of variations and challenges.
There are, perhaps, five major paradigms:
- THREADS (shared memory)
- Library vs. Language-intrinsic
- Explicit start/stop vs. structured concurrency
- Thread pools
- Thread-local storage
- Compute-bound vs. I/O-bound
- Platform vs Virtual
- Synchronization
- Programmer must explicitly synchronize
- For a resource: locks, mutexes, semaphores
- For a desirable state of a resource: condition variables
- To wait on other threads: barriers, latches, exchangers, phasers
- Resources automatically protect themselves
- Monitors, protected objects
- Atomic variables
- Software transactional memory
- Programmer must explicitly synchronize
- DISTRIBUTION (share-nothing, message passing only)
- Naming the receiver (e.g., Erlang) vs. Naming the channel (e.g., Go)
- Remote procedure calls (RPC)
- Must sender and receiver both be ready or are things asymmetric?
- Message queues (what happens if they are full?)
- If my receiver is not ready, should I (1) block indefinitely, (2) block with a timeout, (3) abandon and do other things?
- If no one has sent me anything, should I (1) block indefinitely, (2) block with a timeout, (3) abandon and do other things?
- COROUTINES (“cooperative multitasking” within one real thread)
- Explicit vs implicit yield and resume
- ASYNCHRONICITY (caller does not wait for callee to finish)
- Fire-and-forget
- Callbacks
- Promises (a.k.a. futures)
- Async-await
- PARALLELISM (truly simultaneous execution of subtasks)
- Multicore vs Cluster
- Hardware (e.g., vector processing), GPU, TPU
- Data parallelism
- Task parallelism
- Pipeline parallelism
- Map-reduce in “Big Data” applications
Requirements
Naturally, concurrent programming is harder than sequential programming because concurrent programming is about writing a bunch of communicating sequential programs. As we saw earlier, concurrent systems come with several problems that don’t exist in sequential programs. In designing a concurrent system, these challenges must be addressed, and handled as system requirements, such as:
- Lines must synchronize when necessary to avoid destroying the integrity of shared resources.
- The system must not be prone to race conditions, deadlock, and starvation.
- The system must exhibit safety and liveness.
- The system must have proofs of partial correctness and total correctness.
- The processes must be partitioned into threads, and partitioned amongst each other onto processors so that everything runs efficiently.
- The system must recover if one of the nodes in a distributed system fails.
- If the systems is a single-threaded event-based systems, each chunk of code (responses to events) must always run quickly and leave everything in a consistent state.
Areas of Study
There are quite a few areas one can focus on when studying concurrency. We’ve selected a small number and provided a brief introduction to each.
Granularity
Systems can be classified by “where” the concurrency is expressed or implemented, and how fine-grained or coarse-grained the tasks are.
Instruction Level
Most processors have several execution units and can execute several instructions at the same time. Good compilers can reorder instructions to maximize instruction throughput. Often the processor itself can do this.
inc ebx
inc ecx
inc edx
mov esi,[x]
mov eax,[ebx]
would be executed as follows:
Step U-pipe V-pipe
┌─────┬────────────────────┬────────────────────┐
│ 0 │ inc ebx │ inc ecx │
│ 1 │ inc edx │ mov esi, [x] │
│ 2 │ mov eax, [ebx] │ │
└─────┴────────────────────┴────────────────────┘
Modern processors often have way more than two pipes. They even parallelize execution of micro-steps of instructions within the same pipe.
In addition, some instructions are designed to be explicitly parallel. An example class of instructions are the SIMD instructions. Wikipedia even has a summary of SIMD instructions for the x86 architecture.
Statement Level
Many programming languages have syntactic forms to express that statements should execute in sequence or in parallel. Common notations:
| Pascal-style | Occam-style | Algebraic |
|---|---|---|
begin
A;
cobegin
B;
C;
coend
D;
cobegin
E;
F;
G;
coend
end
|
SEQ
a
PAR
b
c
d
PAR
e
f
g
|
a ; b || c ; d ; e || f || g |
Procedure Level
Many languages have a thread type (or class) and a means to run a function on a thread. These things might also be called tasks. Alternatively there might be a library call to spawn a thread and execute a function on the thread.
Program Level
The operating system runs processes concurrently. This is called multiprocessing or even multiprogramming. You get this for free.
What’s interesting is that you aren’t restricted to launching new processes via the command line, task manager, or clicking on a desktop icon. Many programming languages give you the ability to spawn processes from your own programs. This requires care, because you can get it wrong:
// WARNING: MAJOR INJECTION VULNERABILITY Runtime.getRuntime().exec(commandline);
# WARNING: MAJOR INJECTION VULNERABILITY subprocess.run(commandline, shell=True)
Always look for mechanisms whereby the commands are built safely from tokens.
execve and fork. Can it be done safely?Scheduling
Generally you will have $M$ processors and $N$ threads. If $M < N$ you need a scheduler to interleave execution. The scheduler gives processor time to each thread, according to some scheduling policy, which is hopefully pretty fair. It will take into account priorities and things like whether certain lines have made I/O or other blocking requests.
Communication
The threads of control must communicate with each other. The two main ways to communicate:
- Shared Memory (Indirect)
- Message Passing (Direct)
Synchronization
The term synchronization refers to threads each getting to some point in their execution where they can communicate with each other. Here “communication” can be a signal, a notification, message passing, or similar action. There are often mechanisms for threads to wait for other threads to finish initializing or to finish execution (the latter is almost always called join). But you’ll also see fancy synchronization devices such as:
| Device | Description |
|---|---|
| Barriers | Multiple threads wait until all threads have reached a certain point. When they do, they all get to proceed together. |
| Countdown Latches | One thread waits until a counter reaches 0. Frequently used when the one thread has to wait for $N$ other threads to do something (perhaps finish). Each of the threads decrement the counter, and when it reaches 0, the latch is open and the waiting thread can proceed. |
| Condition Variables | One thread waits until another thread signals it. Typical condition variables names are NOT_EMPTY and NOT_FULL. |
| Exchangers | Here’s how the Java documentation describes them: “A synchronization point at which threads can pair and swap elements within pairs. Each thread presents some object on entry to the exchange method, matches with a partner thread, and receives its partner's object on return. An Exchanger may be viewed as a bidirectional form of a SynchronousQueue. Exchangers may be useful in applications such as genetic algorithms and pipeline designs.” |
Synchronization is often used when threads have to agree with each other not to trample on shared mutable resources, but to agree on mutually exclusive access to such data.
Mutual Exclusion
What is meant by threads “trampling over each other”? Here is the overused classic example: two threads $A$ and $B$ are trying to make a $100 deposit. They both execute the sequence:
- Move the current value of the account into a register
- Add 100 to the register
- Write the value of the register back into memory
If $A$ executes its first statement and then $B$ executes its first statement before $A$ finishes its third statement, one of the deposits gets lost. Oh no!
There are dozens of programming paradigms to make sure threads can synchronize properly to avoid these problems. There are two main approaches. The code to define this critical region might use explicit acquisition and release of locks:
lock := Lock.acquire()
register := read_balance()
register += 100
write_balance(register)
release(lock)
or the synchronization may be implicit, relying on the structure of the code to automatically acquire and the beginning of the block and automatically releasing at the end:
critical_section {
register := read_balance()
register += 100
write_balance(register)
}
Allowing exclusive write access to shared resources by one thread at a time is known as mutual exclusion and people have created a variety of devices for achieving it.
| Device | Description |
|---|---|
| (Explicit) Locks | Simplest synchronization device. A thread explicitly issues calls to acquire a lock and to release it. If a thread tries to acquire a lock that is already held, it blocks until the lock is released. The programmer must be careful not to forget to release a lock when done with it. |
| Semaphores | Generalization of locks. A semaphore can be acquired by multiple threads at once. |
| Monitors | Higher-level synchronization device. A monitor is an instance of a class with methods that are automatically synchronized. Only one thread can execute a method at a time. Also known as a protected object or thread-safe object. |
| Message Passing | Threads communicate by sending messages to each other. |
| Atomic Variables | Special variables that can be read and written atomically. |
| Software Transactional Memory | Threads can execute transactions that are atomic. |
Avoiding Locking and Blocking
Locking may be required for correctness, but may impact performance. In addition to asking yourself “how do I keep the critical sections as small as possible?” you can also ask “are there any critical sections here at all?”. Sometimes you may find that:
- Data you think needs to be shared actually should not be, and each thread should have its own copy of a variable. This is known as Thread-Local Storage.
- The fascinating world of non-blocking algorithms covers a variety of techniques that allow threads to operate on shared data without locking (provided certain conditions are met, of course). You’ll find lock-free algorithms, wait-free algorithms, and obstruction-free algorithms.
Temporal Constraints
If a system has temporal constraints, such as “this operation must complete in 5 milliseconds” it is called a real-time system. Real-time constraints are common in embedded systems.
Language Integration
Some languages build concurrency support with keywords and language-defined constructs; others keep the language itself small and get all concurrency support from external libraries.
| Library or O.S. based | Language-Intrinsic |
|---|---|
.
.
.
int t1, t2;
.
.
.
t1 = createThread(myFunction);
.
.
.
start(t1);
// now t1 runs in parallel
// with the function that
// called start().
// Termination is
// asynchronous, though
// joining can be done with
// a library call.
|
procedure P is . . . task T; . . . begin -- T activated implicitly here . . . -- T and P execute in parallel . . end P; -- T and P terminate together |
|
Advantages:
|
Advantages:
|
As time allows, browse some of these language-specific overviews: Java • Ada • Python • Swift • Clojure • Julia • Rust • Kotlin • Go • Erlang • Elixir • Haskell (also see this book chapter) • Scala.
Programming Paradigms and Patterns
What kind of patterns can you adopt that will help you to produce reliable concurrent code? There are too many to mention here, but here are some things to think about:
- Traditional threads
- Coroutines
- Actors
- Event-driven programming
- Full distribution (share-nothing)
- Async code with callbacks, promises (a.k.a. futures), or async-await
- Reactive programming
- Actors
- What Rich Hickey is doing with time in Clojure
More Topics
There are many more topics in concurrent programming, including:
- Fault-Tolerance
- Scale
- Reliability
- Security
- Performance
- Resource Management
Regarding fault-tolerance, you might like to read about Erlang.
Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- What is the biggest idea in OOP, according to Alan Kay? (Hint: it is not objects, classes, inheritance, encapsulation, or polymorphism.) Messaging
- How does observing the real world motivate our study of concurrency? The real world is full of concurrent activities, and we want to model these activities in our software.
- What are some real-world examples of concurrent systems? Daily routines, the brain, societies, economies, games, railway networks, gardening teams.
- What are some examples of concurrency at the software level? Multiprogramming, simulation programs, high volume servers, pipes, and concurrent tasks in applications like word processors.
- What are some examples of concurrency at the hardware level? Single processors with multiple execution pipelines, multicore processors, multiprocessor computers, networks with multiple computers, and the internet itself.
- What is the big idea in concurrency? Independence of activities. Concurrency is about structuring systems around independent tasks that communicate and coordinate with each other.
- What are some algorithms that benefit from being broken down into parallel subcomputations? Mergesort, quicksort, summing a list, operating on independent slices of an array, computing primes, checking equality of leaf sequences in trees, computing binomial coefficients, video processing jobs, and machine learning jobs.
- What is the difference between concurrency and parallelism? Concurrency is about managing independent tasks that may or may not run simultaneously, while parallelism specifically refers to truly simultaneous execution of tasks (on multicore or multicomputer systems).
- Why is the study of concurrency useful? Concurrency is useful for modeling real-world systems, improving performance in multicore and distributed systems, increasing throughput for I/O-bound tasks, enhancing resource utilization, and enabling better designs for specialized processors.
- What kinds of independent tasks does a word processor do? Reading keystrokes, collecting characters into words, hyphenating, adding spacing for justification, inserting page breaks, checking spelling, and saving documents periodically.
- Given two threads with $m$ and $n$ atomic instructions each, how many possible interleavings are there of the two threads? ${m+n \choose n}$
- What is the difference between partial and total correctness? Partial correctness ensures that if a program terminates, it produces the correct result; total correctness ensures that the program always terminates and produces the correct result.
- What are safety and liveness? Safety ensures that nothing bad happens (e.g., no data corruption), while liveness ensures that something good eventually happens (e.g., a thread eventually completes its task).
- What is required for a concurrent program to be correct? A concurrent program is correct if it ensures safety (nothing bad happens) and liveness (something good eventually happens).
- What is a race condition? A scenario in which multiple threads write to a shared resource at the same time and the result is dependent on the order of execution.
- What is a critical region? A critical region is a section of code that accesses shared resources and must be executed by only one thread at a time.
- What is deadlock? Deadlock is a situation where two or more threads are blocked, each waiting for the other to release a resource, preventing any of them from proceeding.
- What is starvation? Starvation is a situation where a thread is perpetually denied access to a resource it needs because other threads are continuously prioritized over it.
- What is livelock? Livelock is a situation where two or more threads are actively trying to resolve a deadlock but keep changing their states in such a way that they never make progress.
- What is a major concern about threads executing in their critical sections? Reliability. If a thread is interrupted, suspended, or crashes while in its critical section, and the system has no way to detect or recover, the system can be left in an inconsistent state.
- How is a program different from a process? A program is the (static) source code, while a process is an running instance of a program in execution, managed by the operating system.
- From an operating system perspective, what is a thread? A thread is a sequential flow of control within a process, sharing the process's memory space and resources, but having its own program counter and register values.
- What is the difference between multithreading and multiprocessing? Multithreading involves multiple threads within a single process, while multiprocessing involves multiple independent processes running concurrently, possibly on different machines.
- How is parallelism a kind of concurrency? Parallelism is a specific type of concurrency where multiple tasks are executed simultaneously, often on multiple cores or processors.
- How is distribution a kind of concurrency? Distribution is a type of concurrency where all communication between independent processes occurs through message passing, without shared memory.
- If a concurrent system is not fully distributed, what problems must be we attuned to? The synchronization of shared resources.
- Which process algebra is Tony Hoare known for? Communicating Sequential Processes (CSP).
- Which process calculi are Robin Milner known for? First he did the Calculus of Communicating Systems (CCS), then extended it to the π-Calculus.
- What are the three high-level architectural approaches to modeling concurrent systems? Distributed (no shared memory, message passing), Multi-Threaded (multiple threads sharing memory), and Event Queue (single thread processing events from a queue).
- Name five paradigms in concurrent programming. Threads, Distribution, Coroutines, Asynchronous programming, and Parallel programming.
- Are coroutines examples of parallel computing? Absolutely not. They are a form of cooperative multitasking within a single thread, where control is explicitly yielded and resumed.
- What are some different levels of granularity in concurrent programming? Instruction level, statement level, procedure level, and program level.
- What are the two main ways threads communicate? Shared memory (indirect communication) and message passing (direct communication).
- Name at least four synchronization devices: Barriers, countdown latches, condition variables, and exchangers.
- What is the difference between a barrier and a latch? A barrier allows multiple threads to wait until all have reached a certain point before proceeding, while a latch allows one thread to wait until a counter reaches zero, often used for waiting on multiple threads to complete.
- What is the term used to enforce that only one thread can access a shared resource at a time? Mutual exclusion.
- How does a lock work? A lock allows a thread to gain exclusive access to a shared resource. If a thread tries to acquire a lock that is already held by another thread, it will block until the lock is released.
- How does a semaphore work? A semaphore is a synchronization device that allows multiple threads to access a shared resource up to a certain limit. It maintains a count of available resources and blocks threads when the count reaches zero.
- What is a monitor? A monitor is a higher-level synchronization device that encapsulates shared resources and provides methods that are automatically synchronized, allowing only one thread to execute a method at a time.
- What are some three class of non-blocking algorithms? Lock-free algorithms, wait-free algorithms, and obstruction-free algorithms.
- What are systems with temporal constraints such as “this operation must complete in 5 ms” called? Real-time systems.
- What is the difference between library-based concurrency and language-intrinsic concurrency? Library-based concurrency relies on external libraries or operating system features to manage concurrency, while language-intrinsic concurrency provides built-in language constructs for managing concurrent execution.
- Explain the difference between the Erlang-style and the Go-style of process communication. Erlang-style focuses on naming the receiver, where processes send messages to specific named processes. Go-style focuses on naming the channel, where processes communicate through channels that can be shared among multiple goroutines.
Summary
We’ve covered:
- What we mean by concurrency
- Real-world examples (outside of software)
- Architectural choices
- Ways to model processes
- Definitions of some terms
- Why we should study this field
- Granularity, Scheduling, Communication, Synchronization, and more
- Where to find more information