Algorithm Analysis
Introduction
It is important to be able to measure, or at least make educated statements about, the space and time complexity of an algorithm. This will allow you to compare the merits of two alternative approaches to a problem you need to solve, and also to determine whether a proposed solution will meet required resource constraints before you invest money and time coding.
Analysis is done before coding. Profiling (a.k.a. benchmarking) is done after the code is written.

Measuring Time
The absolute running time of an algorithm cannot be predicted, since this depends on the programming language used to implement the algorithm, the computer the program runs on, other programs running at the same time, the quality of the operating system, and many other factors. We need a machine-independent notion of an algorithm’s running time.
The current state-of-the-art in analysis is finding a measure of an algorithm’s relative running time, as a function of how many items there are in the input, i.e., the number of symbols required to reasonably encode the input, which we call $n$. The $n$ could be:
- The number of items in a container
- The length of a string or file
- The degree of a polynomial
- The number of digits (or bits) in an integer
The first three only make sense when each of the elements (items, characters, coefficients/exponents) have a bounded-size. For example: if all items are 64-bit integers, then the number of items can be used for $n$, but if numeric values are unbounded, you have to count bits!
This is so important it is worth restatingIf your collection contains numbers that are fixed in size, like Java’s
ints ordoubles, then the number of items is a reasonable input measure. But for unbounded values, like Java’sBigIntegerorBigDecimal, then the numbers themselves are collections and the number of bits in the number becomes part of the problem input size.
We count the number of abstract operations as a function of $n$.
Abstract operations are also called steps.
Example: Printing each element of an array
for (var i = 0; i < a.length; i++) {
System.out.println(a[i]);
}
Here $n = a.\mathtt{length}$ (provided we know that all of the items in the array have a fixed size, which is often the case). The abstract operation of interest here is the print. We print $n$ times. The algorithm has $n$ steps. So we say $\boxed{T(n) = n}$.
What about the other operations?Frankly, the prints are such big heavy operations that the increments and comparisons in the for-loop just don’t really contribute anything substantial, so yeah, we really do ignore them.
Example: Printing every other element of an array
for (var i = 0; i < a.length; i += 2) {
System.out.println(a[i]);
}
Again we are assuming we live in a world in which $n = a.\mathtt{length}$. And again the abstract operation is the print. We can see that $\boxed{T(n) = \frac{n}{2}}$. This can also be written $\boxed{T(n) = \tfrac{1}{2}n}$.
Example: Getting the last element of an array
if (a.length > 0) {
return a[a.length - 1];
} else {
throw new NoSuchElementException();
}
One step, no matter how big the array is! Here $n = a\mathtt{.length}$, and $\boxed{T(n) = 1}$. This is the best you can get. So good.
Example: Finding the index of a given value in an array
for (var i = 0; i < a.length; i++) {
if (a[i] == x) {
return Optional.of(i);
}
}
return Optional.empty();
Here we need to introduce the $B$ (best-case) and $W$ (worst-case) functions: $\boxed{B(n) = 1}$ and $\boxed{W(n) = n}$. (What about the average case? It’s often difficult and sometimes impossible to compute an average case. You have to know something about the expected distributions of items.)
Example: Printing a Multiplication Table
For the next few examples, let’s assume $n$ has been given to us.
for (var i = 0; i < n; i++) {
for (var j = 0; j < n; j++) {
System.out.printf("%8d", i * j);
}
System.out.println();
}
The outer loop is executed $n$ times. Inside this loop, we have $n+1$ prints ($n$ prints for the numbers and one for the println). So $\boxed{T(n) = n(n+1)}$, which we can also write $\boxed{T(n) = n^2+n}$. The latter expression looks good: we printed $n^2$ numbers and $n$ newlines.
Example: Printing a Triangle
Let’s count:
for (var i = 0; i < n; i++) {
for (var j = 0; j < i; j++) {
System.out.print("*");
}
System.out.println();
}
The first time through the loop ($i=0$), we print one newline. The second time ($i=1$), we do two prints (one star and one newline). The third time ($i=3$) we perform three print operations.
So in total, we print $1 + 2 + 3 + \cdots + n$ times, or $\sum_{i=1}^{n} i$. Perhaps you once learned how to make closed forms for sums like these. In our case, this is $\boxed{T(n) = \frac{n(n+1)}{2}}$, or perhaps better $\boxed{T(n)=\tfrac{1}{2}n^2+\tfrac{1}{2}n}$.
Example: Halving
If we keep halving a number, we don’t go through an entire range. In fact, we finish really quickly:
for (var i = n - 1; i >= 1; i = i / 2) {
System.out.println(i);
}
This is $\boxed{T(n) = \lceil \log_2 n \rceil}$. Halving leads to $\log_2$’s in the complexity functions.
By the way, it is traditional in this line of analysis to take base-2 as the default. So when we write $\log n$, we mean $\log_2 n$.
We also get the same logarithmic behavior not by halving, but by successively doubling a gap:
for (var i = 1; i < n; i = i * 2) {
System.out.println(i);
}
Same complexity as before.
Example: An Interesting Nested Loop
for (var i = 1; i <= n; i *= 2) {
for (var j = 0; j < n; j++) {
count++;
}
}
Here the outer loop is done $\log n$ times and the inner loop is done $n$ times, so $\boxed{T(n) = n \log n}$.
Example: Binary Search
LOGS IN REAL LIFE!
Given a sorted list, you can find a value in it by comparing the value against the middle value of the list. If the list is empty, you did not find it. If the value is equal to the middle value, you found it! If the value is smaller than the middle value of the list, you can search the first have and never ever consider the second half. If larger, then you can search the second half without ever considering the first half.
Let’s find the 71. Start in the middle. The middle element is bigger so we search the right half. We continue as follows:
10 12 15 21 28 29 30 31 35 38 39 41 43 45 48 51 52 55 57 58 71 73 79 80 81 82 88 89 90 91 92 93 95 10 12 15 21 28 29 30 31 35 38 39 41 43 45 48 51 52 55 57 58 71 73 79 80 81 82 88 89 90 91 92 93 95 10 12 15 21 28 29 30 31 35 38 39 41 43 45 48 51 52 55 57 58 71 73 79 80 81 82 88 89 90 91 92 93 95 10 12 15 21 28 29 30 31 35 38 39 41 43 45 48 51 52 55 57 58 71 73 79 80 81 82 88 89 90 91 92 93 95 10 12 15 21 28 29 30 31 35 38 39 41 43 45 48 51 52 55 57 58 71 73 79 80 81 82 88 89 90 91 92 93 95
Looks like we found it.
We are halving our search space each time. And we do this at most $\log_2$ times. Well it does get tricky because we aren’t exactly halving the list, but in broad strokes that’s perfectly reasonable. We are, after all, counting abstract operations.
By the way, you might get lucky and the value you are looking for is right in the middle. This means we have $\boxed{B(n) = 1}$ and $\boxed{W(n) = \log n}$. (See, we’re now starting to use the fact that 2 is the default base in computer science.)
Example: Enumerating Subsets
Logs are really cool. If you had one billion elements in your input, you need only 30 steps to solve your problem. If your input was all the atoms in the observable universe, you need less than 300 steps.
Now let’s flip things around. What if your algorithm required a billion steps to solve a problem of size 30, or over a nonillion steps for inputs of size 100? This is what happens when $T(n) = 2^n$
The classic example of this is: given a set of $n$ elements, there are $2^n$ subsets. If you had to list each one:
WOULD SOMEONE IN CLASS LIKE TO WRITE THIS?
Then you would be computing all $2^n$ subsets, and for each of these you print each of the $n$ elements, so we have $\boxed{T(n)=n 2^n}$
You might encounter the need for subset generation irl when encountering a problem for which there is essentially no better approach than to try all possible subsets of the input to see which one “works.”
Example: Enumerating Permutations
Worse than exponential is factorial. Given a set of $n$ elements, there are $n!$ permutations. If you had to list each permutation:
WOULD SOMEONE IN CLASS LIKE TO WRITE THIS?
Then you would be computing $n!$ permutations, and for each of these you print each of the $n$ elements, so we have $\boxed{T(n)=n \cdot n!}$
You might encounter the need for permutation generation irl when encountering a problem for which there is essentially no better approach than to try all possible arrangements of the input to see which one “works.”
IMPORTANT: Developing IntuitionThe most important thing in your study of these time complexity functions or to get a sense of what each of these functions really mean. Here are crucial things you need to make sure you are starting to understand:
- When $T(n)=n$, we touch every element in the input
- When $T(n)=\log n$, we don’t have to touch every element, we rapidly narrow down the search space, generally by halving
- When $T(n)=1$, we do a single operation and the input size has no effect
And there are more to come.
Example: Multiplying two square matrices
We now return to consideration of input sizes.
for (var i = 0; i < n; i++) {
for (var j = 0; j < n; j++) {
double sum = 0;
for (var k = 0; k < n; k++) {
sum += a[i][k] * b[k][j];
}
c[i][j] = sum;
}
}
Three nested loops, each done $n$ times. So $\boxed{T(n) = n^3}$.
While this is definitely the right function in terms of $n$, it might not be a fair measure of the complexity relative to the size of the input. Here $n$ is the width of the matrices, not the actual number of elements in the input. The input size is the number of entries in the two matrices. If we say that the width of the matrices is $n$, then the input size is actually $2n^2$.
So to get things all correct here, we want $n$ to be the number of matrix entries. If the matrices are square, the matrix width $w$ is $\sqrt{\tfrac{1}{2}n}$, or $(0.5n)^{0.5}$ and the number of abstract operations to multiply the matrices is $w^3 = ((0.5n)^{0.5})^3$ $=$ $(0.5n)^{1.5}$ $\approx$ $0.353553n^{1.5}$
That said, you will sometimes see people using the width for $n$. 🤷♀️
Example: Addition
Here’s another case where you should, in practice, be careful with the input size.
x + y
If $x$ and $y$ are primitive int values that each fit in a word of memory, any computer can add them in one step: $\boxed{T(n) = 1}$. But if these are BigInteger values, then what matters is how many digits (or bits) there are in each value. Since we just have to add the digits in each place and propagate carries, we get $\boxed{T(n) = n}$.
Time Complexity Classes
Time to get real academic.
We can group complexity functions by their “growth rates” (something we’ll formalize in a minute). For example:
| Class | $T(n)$ | Description |
|---|---|---|
| Constant | $1$ | Fixed number of steps, regardless of input size |
| Logarithmic | $\log n$ | Number of steps proportional to log of input size |
| Polynomial | $n^k$, $k \geq 1$ | Number of steps a polynomial of input size |
| Exponential | $c^n$, $c > 1$ | Number of steps exponential of input size |
Those are four useful families to be sure, but we can define lots more:
| Class | $T(n)$ | Description |
|---|---|---|
| Constant | $1$ | Doing a single task at most a fixed number of times. Example: retrieving the first element in a list. |
| Inverse Ackermann | $\alpha(n)$ | |
| Iterated Log | $\log^{*} n$ | |
| Loglogarithmic | $\log \log n$ | |
| Logarithmic | $\log n$ | Breaking down a large problem by cutting its size by some fraction. Example: Binary Search. |
| Polylogarithmic | $(\log n)^c$, $c>1$ | |
| Fractional Power | $n^c$, $0<c<1$ | |
| Linear | $n$ | "Touches" each element in the input. Example: printing a list. |
| N-log-star-n | $n \log^{*} n$ | |
| Linearithmic | $n \log n$ | Breaking up a large problem into smaller problems, solving them independently, and combining the solutions. Example: Mergesort. |
| Quadratic | $n^2$ | "Touches" all pairs of input items. Example: Insertion Sort. |
| Cubic | $n^3$ | |
| Polynomial | $n^c$, $c\geq 1$ | |
| Quasipolynomial | $n^{\log n}$ | |
| Subexponential | $2^{n^\varepsilon}$, $0<\varepsilon<1$ | |
| Exponential | $c^n$, $c>1$ | Often arises in brute-force search where you are looking for subsets of a collection of items that satisfy a condition. |
| Factorial | $n!$ | Often arises in brute-force search where you are looking for permutations of a collection of items that satisfy a condition. |
| N-to-the-n | $n^n$ | |
| Double Exponential | $2^{2^n}$ | |
| Ackerman | $A(n)$ | |
| Runs Forever | $\infty$ |
Comparison
To get a feel for the complexity classes consider a computer that performed one million abstract operations per second:
| $T(n)$ | 10 | 20 | 50 | 100 | 1000 | 1000000 |
|---|---|---|---|---|---|---|
| 1 | 1 μs | 1 μs | 1 μs | 1 μs | 1 μs | 1 μs |
| $\log n$ | 3.32 μs | 4.32 μs | 5.64 μs | 6.64 μs | 9.97 μs | 19.9 μs |
| $n$ | 10 μs | 20 μs | 50 μs | 100 μs | 1 msec | 1 second |
| $n \log n$ | 33.2 μs | 86.4 μs | 282 μs | 664 μs | 9.97 msec | 19.9 seconds |
| $n^2$ | 100 μs | 400 μs | 2.5 msec | 10 msec | 1 second | 11.57 days |
| $1000 n^2$ | 100 msec | 400 msec | 2.5 seconds | 10 seconds | 16.7 minutes | 31.7 years |
| $n^3$ | 1 msec | 8 msec | 125 msec | 1 second | 16.7 minutes | 317 centuries |
| $n^{\log n}$ | 2.1 ms | 420 ms | 1.08 hours | 224 days | 2.5×107 Ga | 1.23×1097 Ga |
| $1.01^n$ | 1.10 μs | 1.22 μs | 1.64 μs | 2.7 μs | 20.9 ms | 7.49×104298 Ga |
| $0.000001 \times 2^n$ | 1.02 ns | 1.05 msec | 18.8 minutes | 40.2 Ga | 3.40×10272 Ga | 3.14×10301001 Ga |
| $2^n$ | 1.02 ms | 1.05 seconds | 35.7 years | 4.02×107 Ga | 3.40×10278 Ga | 3.14×10301007 Ga |
| $n!$ | 3.63 seconds | 771 centuries | 9.64×1041 Ga | 2.96×10135 Ga | 1.28×102545 Ga | — |
| $n^n$ | 2.78 hours | 3323 Ga | 2.81×1062 Ga | 3.17×10177 Ga | 3.17×102977 Ga | — |
| $2^{2^n}$ | 5.70×10285 Ga | 2.14×10315630 Ga | — | — | — | — |
By the way, Ga is a gigayear, or one billion years.
There is something. Compare the $2^n$ row with the $0.000001\cdot 2^n$ row. The latter represents something running one million times faster than the former, but still, even for an input of size 50, requires a run time in the thousands of centuries.
Asymptotic Analysis
Since we are really measuring growth rates, we usually ignore:
- all but the “largest” term, and
- any constant multipliers
so for example
- $\lambda n . 0.4n^5 + 3n^3 + 253$ behaves asymptotically like $n^5$
- $\lambda n . 6.22 n \log n + \frac{n}{7}$ behaves asymptotically like $n \log n$
The justification for doing this is:
- The difference between $6n$ and $3n$ isn’t meaningful when looking at algorithms abstractly, since getting a computer that is twice as fast makes the former behave exactly like the latter. The underlying speed of the computer never matters in abstract analysis. Only the algorithm structure itself matters.
- The difference between $2n$ and $2n+8$ is insignificant as $n$ gets larger and larger.
- If you are comparing the growth rates of, say, $\lambda n . n^3$ and $\lambda n . k n^2$, the former will always eventually overtake the latter no matter how big you make $k$. A leading constant can never make a function of a lower rank asymptotically worse than one from a higher rank.
How can we formalize this? That is, how do we formalize things like “the set of all quadratic functions” or the “set of all linear functions” or “the set of all logarithmic functions”?
Big-O: Asymptotic Upper Bounds
A function $f$ is in $O(g)$ whenever there exist constants $c$ and $N$ such that for every $n > N$, $f(n)$ is bounded above by a constant times $g(n)$. Formally:
$$ O(g) =_{def} \{ f \mid \exists c\,N . \forall n > N . |f(n)| \leq c|g(n)| \} $$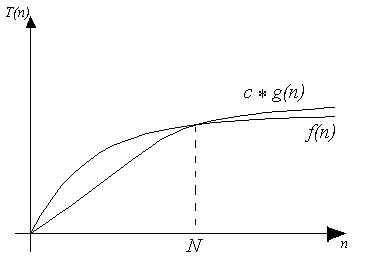
This means that $O(g)$ is the set of all functions for which $g$ is an asymptotic upper bound of $f$.
Examples
- $\lambda n . 0.4 n^5 + 3n^3 + 253 \in O(\lambda n . n^5)$
- $\lambda n . 6.22n \log n + \frac{n}{7} \in O(\lambda n . n \log n)$
Notation
By convention, people usually drop the lambdas when writing expressions involving Big-O, so you will see things like $O(n^2)$.
Does this really let us throw away constant factors and small terms?
Well let’s see why we should be able to, but only argue with one special case. (You can do the formal proof on your own.) Let’s show that $7n^4 + 2n^2 + n + 20 \in O(n^4)$. We have to choose $c$ and $N$. Let’s choose $c=30$ and $N=1$. So since $n \geq 1$: $$ \begin{eqnarray} |7n^4 + 2n^2 + n + 20| & \leq & 7n^4 + 2n^2 + n + 20 \\ & \leq & 7n^4 + 2n^4 + n^4 + 20n^4 \\ & \leq & 30n^4 \end{eqnarray} $$
Too much technical detail? Want to review what this is all about? Here’s a video:
Is Big-O Useful?
- Big-O notation is really only most useful for large n.
The suppression
of low-order terms and leading constants is misleading for small n. Be
careful of functions such as
- $n^2 + 1000n$
- $0.0001 n^5 + 10^6 n^2$
- $10^{-4}2^n + 10^{5}n^3$
- Large constants on the more significant terms signify overhead,
for example when comparing
- $8n \log n$ and $0.01n^2$
- Sedgewick writes "[Big-O analysis] must be considered the very first step in a progressive process of refining the analysis of an algorithm to reveal more details about its properties."
- Big-O is only an upperbound; it is not a tight upperbound. If an algorithm is in $O(n^2)$ it is also in $O(n^3)$, $O(n^{100})$, and $O(2^n)$. So it’s not really right to say that all complexity functions in $O(2^n)$ are terrible, because that set properly includes the set $O(1)$.
Big-Ω: Asymptotic Lower Bounds
There is a Big-$\Omega$ notation for lower bounds.
A function $f$ is in $\Omega(g)$ whenever there exist constants $c$ and $N$ such that for every $n > N$, $f(n)$ is bounded below by a constant times $g(n)$.
$$ \Omega(g) =_{def} \{ f \mid \exists c\,N . \forall n > N . |f(n)| \geq c|g(n)| \} $$Lower bounds are useful because they say that an algorithm requires at least so much time. For example, you can say that printing an array is $O(2^n)$ because $2^n$ really is an upper bound, it’s just not a very tight one! But saying printing an array is $\Omega(n)$ means it requires at least linear time which is more accurate. Of course just about everything is $\Omega(1)$.
Big-$\Theta$
When the lower and upper bounds are the same, we can use Big-Theta notation.
$$\Theta(g) =_{def} \{ f \mid \exists c_1\,c_2\,N. \forall n > N . c_{1} |g(n)| \leq |f(n)| \leq c_2 |g(n)| \}$$Example: printing each element of an array is $\Theta(n)$. Now that’s useful!
Most complexity functions that arise in practice are in Big-Theta of something. An example of a function that isn’t in Big-$\Theta$ of anything is $\lambda n . n^2 \cos n$.
Less-Common Complexity Functions
There are also little-oh and little-omega. $$\omicron(g) =_{def} \{ f \mid \lim_{x\to\infty} \frac{f(x)}{g(x)} = 0 \}$$ $$\omega(g) =_{def} \{ f \mid \lim_{x\to\infty} \frac{f(x)}{g(x)} = \infty \}$$
There’s also the Soft-O:
$$\tilde{O}(g) =_{def} O(\lambda n.\,g(n) (\log{g(n)})^k)$$Since a log of something to a power is bounded above by that something to a power, we have
$$\tilde{O}(g) \subseteq O(\lambda n.\,g(n)^{1+\varepsilon})$$Determining Asymptotic Complexity
Normally you can just look at a code fragment and immediately "see" that it is $\Theta(1)$, $\Theta(\log n)$, $\Theta(n)$, $\Theta(n \log n)$, or whatever. But when you can’t tell by inspection, you can write code to count operations for given input sizes, obtaining $T(n)$. Then you "guess" different values of f for which $T \in \Theta(f)$. To do this, generate values of $\frac{T(n)}{f(n)}$ for lots of different $f$s and $n$s, looking for the $f$ for which the ratio is nearly constant. Example:
import java.util.Arrays;
/**
* An application class that illustrates how to do an empirical analysis for
* determining time complexity.
*/
public class PrimeTimer {
/**
* A method that computes all the primes up to n, and returns the number of
* "primitive operations" performed by the algorithm.
*/
public static long computePrimes(int n) {
var sieve = new boolean[n];
Arrays.fill(sieve, true);
sieve[0] = sieve[1] = false;
var ticks = 0L;
for (var i = 2; i * i < sieve.length; i++) {
ticks++;
if (sieve[i]) {
ticks++;
for (var j = i + i; j < sieve.length; j += i) {
ticks++;
sieve[j] = false;
}
}
}
return ticks;
}
/**
* Runs the computePrimes() methods several times and displays the ratio of the
* number of primitive operations to n, n*log2(log2(n)), n*log2(n), and n*n, for
* each run. The idea is that if the ratio is nearly constant for any one of the
* expressions, that expression is probably the asymptotic time complexity.
*/
public static void main(String[] args) {
System.out.println(" n T(n)/n T(n)/nloglogn"
+ " T(n)/nlogn T(n)/n^2");
for (var n = 100000000; true; n += 10000000) {
var time = (double) computePrimes(n);
var log2n = Math.log(n) / Math.log(2.0);
var log2log2n = Math.log(log2n) / Math.log(2.0);
System.out.printf("%9d%15.9f%15.9f%15.9f%18.12f%n", n, time / n,
time / (n * log2log2n), time / (n * log2n),
time / ((double) n * n));
}
}
}
$ javac algorithms/PrimeTimer.java && java edu.lmu.cs.algorithms.PrimeTimer
n T(n)/n T(n)/nloglogn T(n)/nlogn T(n)/n^2
100000000 2.483153670 0.524755438 0.093437967 0.000000024832
110000000 2.488421536 0.525042572 0.093154203 0.000000022622
120000000 2.492800475 0.525216963 0.092881654 0.000000020773
130000000 2.496912269 0.525397614 0.092636275 0.000000019207
140000000 2.500607893 0.525543667 0.092406844 0.000000017861
150000000 2.504261540 0.525726296 0.092202718 0.000000016695
160000000 2.508113469 0.525989754 0.092029052 0.000000015676
170000000 2.511378312 0.526164370 0.091854066 0.000000014773
180000000 2.514174300 0.526271114 0.091679818 0.000000013968
190000000 2.517111653 0.526434419 0.091526593 0.000000013248
200000000 2.519476410 0.526502103 0.091366731 0.000000012597
210000000 2.521918771 0.526607744 0.091222446 0.000000012009
220000000 2.524643468 0.526791900 0.091099845 0.000000011476
230000000 2.526841665 0.526883963 0.090968655 0.000000010986
240000000 2.529254646 0.527037032 0.090854692 0.000000010539
250000000 2.531615772 0.527194102 0.090747527 0.000000010126
260000000 2.533554869 0.527276931 0.090633206 0.000000009744
270000000 2.535273511 0.527326521 0.090518378 0.000000009390
280000000 2.537081721 0.527406431 0.090413568 0.000000009061
290000000 2.538856217 0.527490156 0.090313866 0.000000008755
300000000 2.540369853 0.527529768 0.090210757 0.000000008468
.
.
.
580000000 2.573933419 0.529233035 0.088416447 0.000000004438
590000000 2.574801915 0.529278658 0.088371416 0.000000004364
600000000 2.575498323 0.529291236 0.088321815 0.000000004292
610000000 2.576229731 0.529313262 0.088274708 0.000000004223
620000000 2.576874421 0.529319651 0.088225880 0.000000004156
630000000 2.577634338 0.529351816 0.088182205 0.000000004091
640000000 2.578348789 0.529376678 0.088138140 0.000000004029
650000000 2.579215052 0.529434671 0.088100389 0.000000003968
660000000 2.579956808 0.529469006 0.088059472 0.000000003909
670000000 2.580654654 0.529496175 0.088018114 0.000000003852
680000000 2.581385994 0.529532005 0.087978922 0.000000003796
690000000 2.582226029 0.529591860 0.087944424 0.000000003742
700000000 2.582908279 0.529621034 0.087905512 0.000000003690
710000000 2.583473030 0.529627754 0.087863538 0.000000003639
.
.
.
What we’re seeing here is that the ratio $\frac{T(n)}{n}$ is increasing, so the complexity is probably more than linear. The ratios $\frac{T(n)}{n \log n}$ and $\frac{T(n)}{n^2}$ are decreasing so those functions are probably upper bounds. But $\frac{T(n)}{n \log{\log{n}}}$ is also increasing, but the rate of increase seems to be slowing and who knows, might even converge. We could bet that the complexity $\in \Theta(n \log{\log{n}})$, but we should really do a formal proof.
The Effects of Increasing Input Size
Suppressing leading constant factors hides implementation dependent details such as the speed of the computer which runs the algorithm. Still, you can some observations even without the constant factors.
| For an algorithm of complexity | If the input size doubles, then the running time |
|---|---|
| $1$ | stays the same |
| $\log n$ | increases by a constant |
| $n$ | doubles |
| $n^2$ | quadruples |
| $n^3$ | increases eight fold |
| $2^n$ | is left as an exercise for the reader |
The Effects of a Faster Computer
Getting a faster computer allows to solve larger problem sets in a fixed amount of time, but for exponential time algorithms the improvement is pitifully small.
| For an algorithm of complexity | If you can solve a problem of this size on your 100MHz PC | Then on a 500MHz PC you can solve a problem set of this size | And on a supercomputer one thousand times faster than your PC you can solve a problem set of this size |
|---|---|---|---|
| $n$ | 100 | 500 | 100000 |
| $n^2$ | 100 | 223 | 3162 |
| $n^3$ | 100 | 170 | 1000 |
| $2^n$ | 100 | 102 | 109 |
More generally,
| $T(n)$ | On Present Computer | On a computer 100 times faster | On a computer 1000 times faster | On a computer one BILLION times faster |
|---|---|---|---|---|
| $n$ | N | 100N | 1000N | 1000000000N |
| $n^2$ | N | 10N | 31.6N | 31623N |
| $n^3$ | N | 4.64N | 10N | 1000N |
| $n^5$ | N | 2.5N | 3.9N | 63N |
| $2^n$ | N | N + 6.64 | N + 9.97 | N + 30 |
| $3^n$ | N | N + 4.19 | N + 6.3 | N + 19 |
What if we had a computer so fast it could do ONE TRILLION operations per second?
| $T(n)$ | 20 | 40 | 50 | 60 | 70 | 80 |
|---|---|---|---|---|---|---|
| $n^5$ | 3.2 μs | 102 μs | 313 μs | 778 μs | 1.68 msec | 3.28 msec |
| $2^n$ | 1.05 msec | 1.1 seconds | 18.8 minutes | 13.3 days | 37.4 years | 383 centuries |
| $3^n$ | 3.5 msec | 4.7 months | 227 centuries |
1.3 × 107 centuries | 7.93 × 1011 centuries | 4.68 × 1016 centuries |
As you can see, the gap between polynomial and exponential time is hugely significant. We can solve fairly large problem instances of high-order polynomial time algorithms on decent computers rather quickly, but for exponential time algorithms, we can network together thousands of the world’s fastest supercomputers and still be unable to deal with problem set sizes of over a few dozen. So the following terms have been used to characterize problems:
| Polynomial-time Algorithms | Exponential-time Algorithms |
|---|---|
| Good | Bad |
| Easy | Hard |
| Tractable | Intractable |
Further Study
Here are some things not studied here that you will definitely want to pick up on later:
- Other functions for complexity measures: $\log \log n$, $n^{\frac{3}{2}}$, $(\log n)^k$, $n^{\log n}$, $A(m,n)$, $\alpha(m,n)$, $2^{n}/n$, $n^{2}2^{n}$, ...
- Algorithms whose input size is quantified by more than one variable, as in graphs where $n$ = the number of nodes and $e$ = the number of edges and we find complexity measures such as $\Theta(e)$, $\Theta(n^2)$, $\Theta(n \log e)$, $\Theta(n^2 \log e)$, ...
- Space Complexity
- Formalized complexity classes: DLOG, NLOG, P, NP, PSPACE, and more (Don’t miss the Complexity Zoo)
- Complexity measures for parallel, concurrent and distributed algorithms
- Pessimal algorithms and simplexity analysis
- The Complexity of Songs
Summary
We’ve covered:
- Why we measure relative, not absolute, time
- The idea of abstract operations
- Choosing $n$, the input size
- Several examples of determining $T(n)$
- The common (and some not-so-common) complexity classes
- Asymptotic Analysis ($O$, $\Theta$, $\Omega$)
- The effects of increasing input size
- The effects of a faster computer