A Compiler for Carlos
Overview
This page describes a compiler for the language Carlos. The idea is to show how a medium-sized Java program is designed and implemented. It's on GitHub.
Getting Started
Before working with the compiler you should read and study the formal definition for the language Carlos.
The compiler is written in Java, so make sure your development box has a JDK (1.6 or higher), and Maven (version 3 or above). You should use a good IDE like Eclipse, too. I've done some stuff in the pom file to make it work nicely in Eclipse.
After you get the source code by cloning or forking the repo, just enter
$ mvn package
in the project root directory. You can then run a mini-Carlos IDE with:
$ java -cp target/carlos-1.0.jar edu.lmu.cs.xlg.carlos.Viewer
Design
If you were writing this compiler from scratch, you would first come up with a list of things you need. This project requires:
- A compiler class with methods to fire up the compiler (both programmatically and from the command line) and provide access to some of its components (to allow standalone syntax checking, semantic analysis, assembly language generation, linking, etc.)
- Scanner and parser classes, but we will generate these from a JavaCC specification file.
- Classes for the programs themselves, that is, their semantic representations: programs, blocks, declarations, variables, statements, expressions and so on.
- A translator from the source to the intermediate (or target) language.
- Resource files, because internationalization is a good thing.
- Unit tests.
- Sample Carlos programs to run the unit tests on.
- A project file, since real Java programmers use Maven.
Architectural Overview
Project setup
We've set up this project the "right way" — the way that most Java projects in the world are arranged these days. The basic idea is that /src contains everything checked into version control, and /src/main contains everything bundled in the released product.
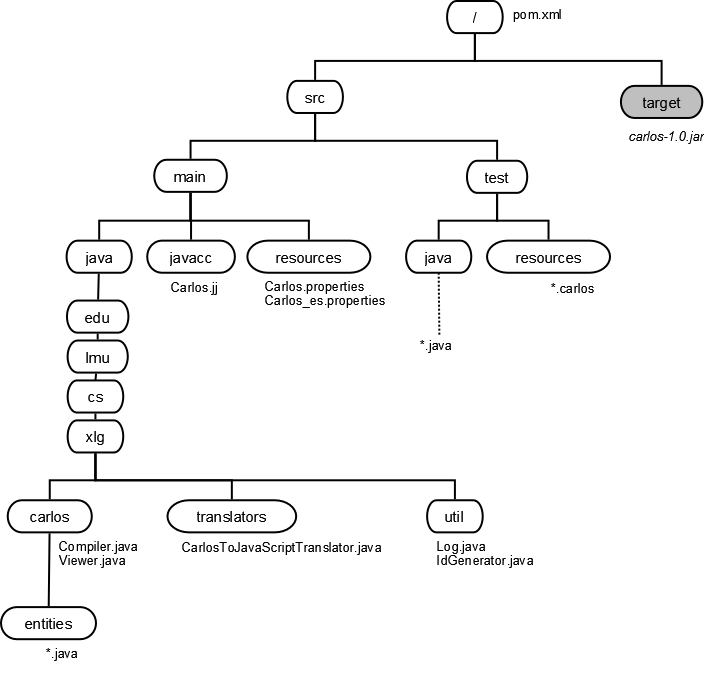
Here is a brief description of each of the directories in the project:
- /
- Contains only the Maven project file and a README and your version control private directories (I have ,git and .gitignore). If you are using Eclipse, you will put the files .project and .classpath there too, those these should not go into version control of course.
- src
- Ancestor directory for all source code that makes up the project.
- src/main
- Ancestor directory for all source code that will be compiled into the distributed product.
- src/main/java
- Ancestor directory for all main java code.
- src/main/java/edu/lmu/cs/xlg/carlos
- Sources for the code specific to the Carlos language and compiler go in this directory tree. The carlos directory itself contains applications such as the command-line based compiler and a graphical code viewer.
- src/main/java/edu/lmu/cs/xlg/carlos/entities
- Classes for all of the syntactically and semantically significant Carlos objects, such as statements, expressions, blocks, types, functions, ... These entities understand their own semantics (meaning they can take care of their own semantic analysis), but they know absolutely nothing regarding what they will be translated into. Translation is fully non-intrusive.
- src/main/java/edu/lmu/cs/xlg/translators
- A package for translations between languages. This compiler has only one, but in theory you could write an infinite number of these.
- src/main/java/edu/lmu/cs/xlg/util
- Classes used by all of the other packages, such as a smart logger and an id generator.
- src/main/javacc
- All javacc scripts go here. We only have one, Carlos.jj
- src/main/resources
- All resource files that need to be present at runtime. This includes properties files (for internationalization).
- src/test
- Ancestor directory for unit tests. Only things under src/main will get compiled and/or placed in the distributed product. Anything under src/test will not.
- src/test/java
- Ancestor directory for unit tests written in Java.
- src/test/resources
- Non-Java files that have to be around when tests run. This includes the dozens of Carlos programs used in testing.
- target
- Ancestor directory that holds all built artifacts. The target directory is never checked into version control. Doing a "clean build" begins with completely deleting this directory and all descendants.
- target/generated-sources
- Holds all the Java files generated from running javacc on the Carlos.jj file.
- target/classes
- Holds all the compiled class files.
The POM
Start by browsing the pom file
Note how the pom contains, for the project:
- Metadata: the project will be identified as xlg.cs.lmu.edu:carlos:1.0
- A dependency on Google Guava
- A dependency of JUnit, for test scope only
- A property indicating that UTF-8 is the source encoding
- The maven compiler plugin with a setting to use Java 1.6 (the default is lower)
- The javacc-maven-plugin so JavaCC will be run properly during maven builds
- The maven shade plugin, so that our jar will be built with its dependencies
- Plugin management info for the JavaCC Maven plugin, without which Eclipse gets very angry
Utility classes and resources
Some code will be useful to all parts of the compiler. For example, we'd like to do some global error counting and logging, and have a consistent way to do internationalization. I have a little logger that can do these things:
Professional software is internationalized, so you'll want resource files. Here's the default resource file (with U.S. English):
There is one for Spanish:
For extra credit, I'll gladly accept versions of this file in other languages.
Syntax Tree Entities
Carlos abstract syntax trees are made up of such things as programs, blocks, variables, types, functions, expressions, statements, and so on. The class hierarchy I came up with for Carlos is:
| Class | Attributes |
|---|---|
| Entity | — |
| Block | statements |
| Program | — |
| Declarable | name |
| Variable | typename, initializer |
| Type | — |
| ArrayType | baseTypeName |
| StructType | fields |
| Function | returnTypeName, parameters, body |
| Statement | — |
| Declaration | declarable |
| IncrementStatement | op, target |
| CallStatement | functionName, args |
| AssignmentStatement | left, right |
| BreakStatement | — |
| ReturnStatement | returnExpression |
| IfStatement | cases |
| WhileStatement | condition, body |
| ClassicForStatement | typeName, index, initial, final, each, body |
| Expression | — |
| Literal | lexeme |
| IntegerLiteral | value |
| RealLiteral | value |
| StringLiteral | vaue |
| CharLiteral | value |
| BooleanLiteral | value |
| NullLiteral | — |
| VariableExpression | — |
| SimpleVariableReference | name |
| CallExpression | functionName, args |
| SubscriptedVariable | array, index |
| DottedVariable | struct, fieldname |
| ArrayAggregate | typename, args |
| StructAggregate | typename, args |
| EmptyArray | typename, bounds |
| PrefixExpression | op, operand |
| PostfixExpression | op, operand |
| InfixExpression | op, left, right |
| StructField | name, typename |
| Case | condition, body |
The "Syntax Portion" of the Entity Classes
We have a class for each entity. There is a field for
each syntactic attribute and the constructor fills in those fields.
The classes are in src/main/java/edu/lmu/cs/xlg/carlos/entities.
The src/main/java
directory will be the base directory for Java compilations, so the
package name for the entity classes will be
edu.lmu.cs.xlg.carlos.entities.
Here is an example
package edu.lmu.cs.xlg.carlos.entities;
/**
* A statement of the form "while e b".
*/
public class WhileStatement extends Statement {
private Expression condition;
private Block body;
public WhileStatement(Expression condition, Block body) {
this.condition = condition;
this.body = body;
}
public Expression getCondition() {
return condition;
}
public Block getBody() {
return body;
}
}
The Abstract Syntax Tree Generator
The Carlos grammar is not LL(k) (the rules for TYPE and VAR have left recursion), so when using JavaCC you'll notice some little tweaks.
The pattern used for parsing functions in the compiler is the one in which all parsing functions return an entity. For example:
Program parseProgram():
{List<Statement> statements = new ArrayList<Statement>(); Statement s;}
{
( s = parseStmt() {statements.add(s);} )+
<EOF>
{return new Program(statements);}
}
There are a couple places where you'll want to change the grammar: since increments and calls can be both expressions and statements, you'll want to split up parsing functions; for example, parseCallExpression and parseCallStatement.
My completed JJ file for Carlos is (please study it):
Semantic Analysis
Semantic analysis modifies the abstract syntax tree by doing things like resolving names (such as type names, variable names and function names) so that nodes can now point to real types and real variables and real functions. It also does things like type checking and argument count checking, logging errors whenever it finds problems.
The way semantic analysis works is by defining analyze() methods for each
entity class. These methods not only do semantic checking and "fill in semantic fields", but
they also (necessarily) invoke the analyze() methods of the nodes they reference.
We end up doing a depth-first traversal through the AST, transforming it into a semantic graph.
The analyze methods all operate with an AnalysisContext object. Here is how
the method is described in the root Entity class:
/** * Performs semantic analysis on this entity, and (necessarily) on its descendants. */ public abstract void analyze(AnalysisContext context);
The AnalysisContext object has four fields: (1) a logger to use, (2) the
current symbol table in effect, (3) the current function you are inside of, which is important
when you are checking return statements, and (4) whether or not you are in a loop, which is
important to check break statements. Here is a part of this class:
public class Entity {
...
public static class AnalysisContext {
private Log log;
private SymbolTable table;
private Function function;
private boolean inLoop;
public static AnalysisContext makeGlobalContext(Log log) ...
public AnalysisContext withTable(SymbolTable table) ...
public AnalysisContext withFunction(Function function) ...
public AnalysisContext withInLoop(boolean inLoop) ...
public Log getLog() ...
public SymbolTable getTable() ...
public Function getFunction() ...
public boolean isInLoop() ...
public Type lookupType(String name) ...
public Variable lookupVariable(String name) ...
public Function lookupFunction(String name, List<Expression> args) ...
public void error(String errorKey, Object... arguments) ...
}
}
Here are some examples of analzye() methods. Sometimes analysis is trivial,
you just analyze your children nodes. This one is from PrintStatement.java:
@Override
public void analyze(AnalysisContext context) {
for (Expression arg : args) {
arg.analyze(context);
}
}
Here's the one from WhileStatement.java. Note it has to analyze both its condition and
its body, but it also checks that its condition has type boolean (using a helper method on the
class Expression). Note that when we analyze the body of the while statement, we
pass in a new context object which is like the original one, but has its inLoop property
set to true.
@Override
public void analyze(AnalysisContext context) {
condition.analyze(context);
condition.assertBoolean("while_statement_condition", context);
body.analyze(context.withInLoop(true));
}
From Variable.java. When we did syntax analysis, we only found a type name. During
semantic analysis, we have to lookup the type that the name maps to. If lookupType
does not find a type, then an error will be logged in the context, and the method will return
Type.ARBITRARY. This special type typechecks cleanly with everything else; it helps
to avoid spurious errors.
@Override
public void analyze(AnalysisContext context) {
type = context.lookupType(typename);
// If an initializer is present, analyze it and check types.
if (initializer != null) {
initializer.analyze(context);
initializer.assertAssignableTo(type, context, "variable_initialization");
}
}
From AssignmentStatement.java:
@Override
public void analyze(AnalysisContext context) {
left.analyze(context);
right.analyze(context);
left.assertWritable(context);
right.assertAssignableTo(left.type, context, "assignment");
}
From BreakStatement.java:
@Override
public void analyze(AnalysisContext context) {
if (!context.isInLoop()) {
context.error("break_not_in_loop");
}
}
And now for one a little more complex. From CallExpression.java:
@Override
public void analyze(AnalysisContext context) {
// Analyze all the arguments
for (Expression a: args) {
a.analyze(context);
}
// Find out which function we're calling
function = context.lookupFunction(functionName, args);
if (function == null) {
// If we can't find the function, just forget it
type = Type.ARBITRARY;
return;
}
// Since called from expression, must have a return type
if (function.getReturnType() == null) {
context.error("void_function_in_expression", functionName);
type = Type.ARBITRARY;
} else {
type = function.getReturnType();
}
}
It's easier to do semantic analysis if you have a good symbol table class. Here's mine:
Front End Testing
Remember that unit testing involves making a non-interactive tester that can run on its own and test for hours. It should never rely on humans to "look at the output to see if each test is okay." Instead write code that processes zillions of inputs and does a lot of assertions. All modern Java systems use the JUnit framework for testing. The Carlos compiler automatically runs junit because the POM is set up to do that.
This tester works by picking up all the files named *.carlos
in the src/test/resources directory and running them through
the front end. Filenames beginning with "synerror" are expected to
have syntax errors. Filenames beginning with "semerror" are expected
to have static semantic errors. All other files are expected to pass
semantic analysis with no errors. The tester counts the number of tests
and the number of failures and gives you a report.
Note that the tester is really only a shell; the tests themselves are only thorough if you write hundreds of little Carlos apps.
Tools
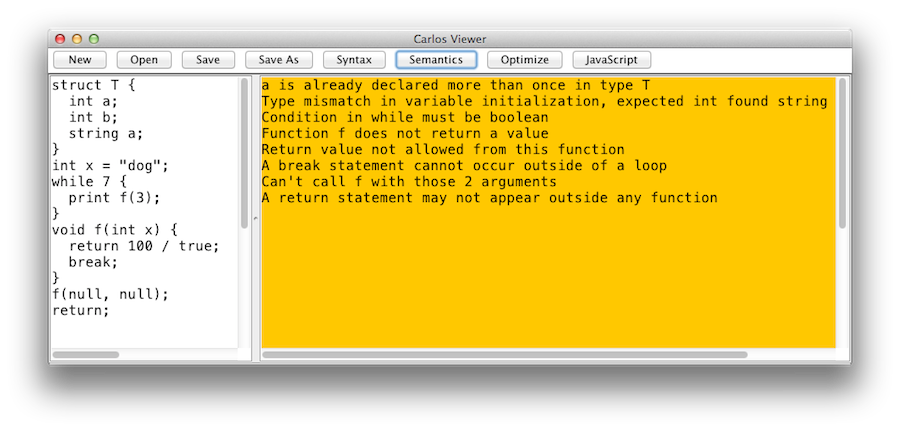
During development, you will find yourself needing to "see" the syntactic and semantic structures output by the compiler. I wrote a very simple, but fairly nice, GUI tool for this:
This is in no way a substitute for the unit tests; it's just a neat learning tool.
To use the tool, start typing a Carlos program into the left pane, then hit one of the four buttons to see (1) its Abstract Syntax Tree, (2) its semantic graph, (3) its optimized semantic graph, and (4) its translation into JavaScript. On success, the output pane will be green.
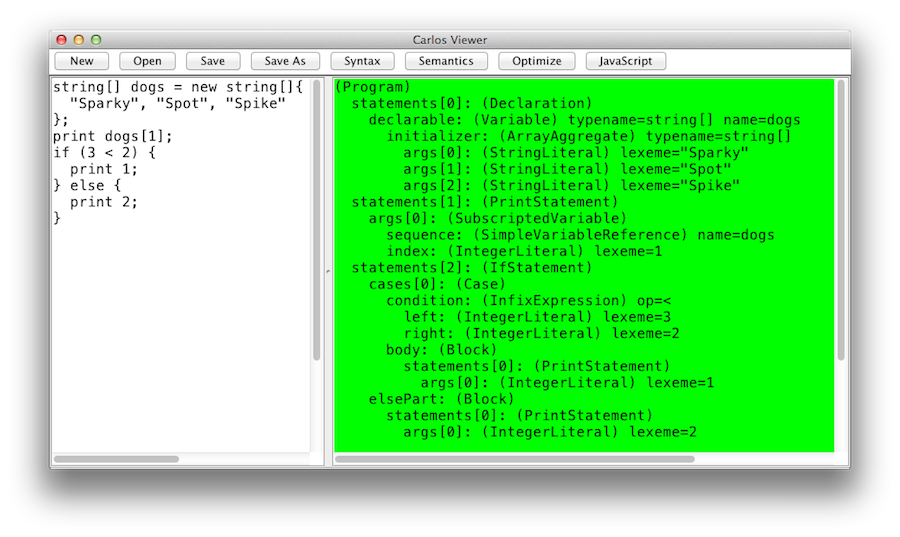
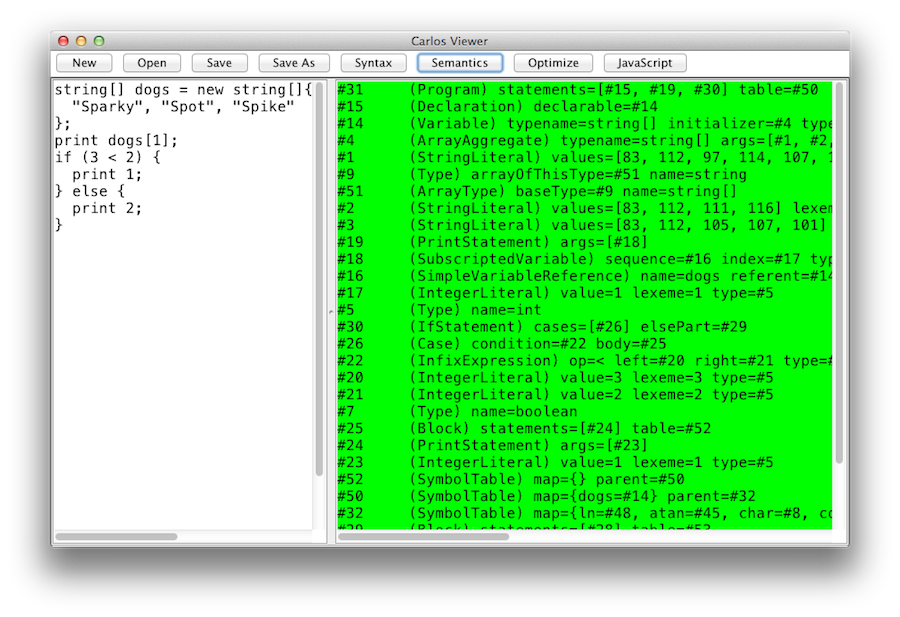
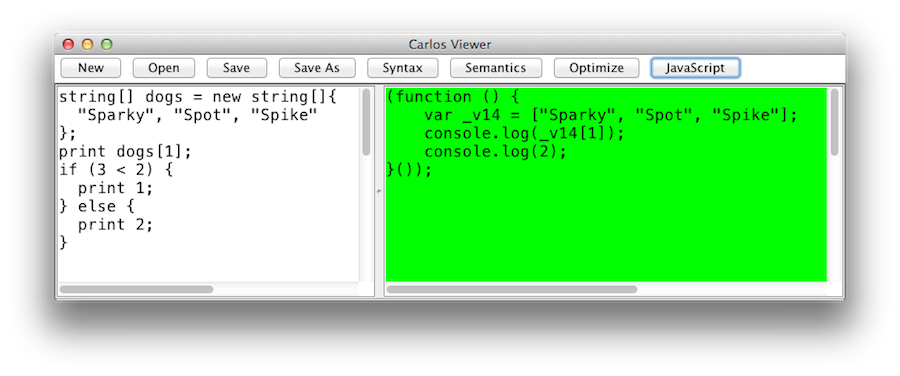
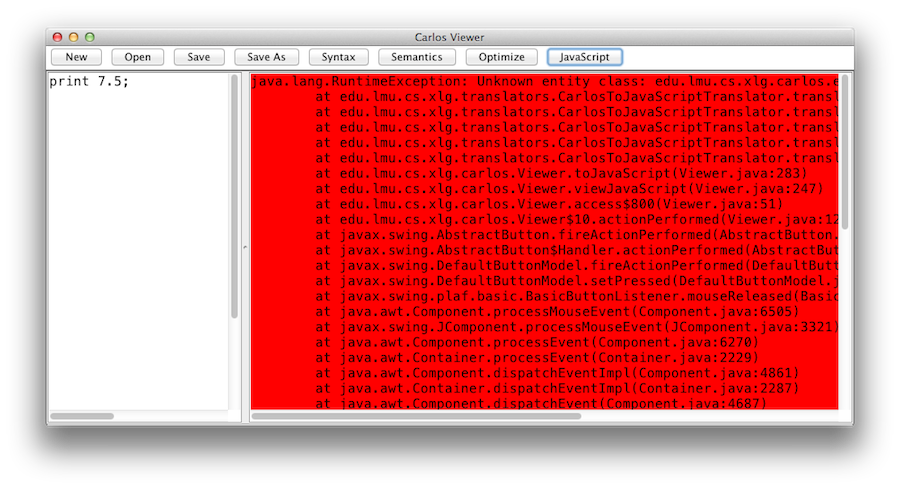
If the compiler itself throws an exception (hey it's a free hackathon-quality app), then the output pane will be red. I don't have any recent screenshots for this case, but here's one that showed up during development:
Code Generation
There's a pretty straightforward translator that walks the semantic graph and outputs JavaScript on the fly:
Optimizations
I've included a handful of simple optimizations. Most of the entity classes have an
optimize() method. The best way to study these is by browsing the code. But
here's one snippet, in case you are interested; it's from the while statement:
@Override
public Statement optimize() {
condition = condition.optimize();
body.optimize();
if (condition.isFalse()) {
return null;
}
return this;
}
Running The Compiler
There are two classes in the compiler with main methods:
- edu.lmu.cs.xlg.carlos.Compiler
- edu.lmu.cs.xlg.carlos.Viewer
Running from the command line.
You can run the compiler from the command line by saying:
java -cp carlos-1.0.jar edu.lmu.cs.xlg.carlos.Compiler
though it would be easier perhaps to wrap this call in a shell
script, something called carlos.bat on Windows, and
just plain carlos everywhere else. For bash, your
script would look like this:
java -cp carlos-1.0.jar edu.lmu.cs.xlg.carlos.Compiler $@
and for Windows
java -cp carlos-1.0.jar edu.lmu.cs.xlg.carlos.Compiler %1 %2
The Carlos compiler accepts several command line arguments:
carlos (display help)
carlos -syn myprogram (produces the syntax tree, to stdout)
carlos -sem myprogram (produces a semantic graph, to stdout)
carlos -opt myprogram (produces an optimized semantic graph, to stdout)
carlos -js myprogram (produces JavaScript in an output file)
To get the compiler to use Spanish, you can invoke (for example)
java -Duser.language=es -cp carlos-1.0.jar edu.lmu.cs.xlg.carlos.Compiler -js myprogram
I'll leave to to you to figure out how to get your script to deal with that.
Here is a program with semantic errors (in the file bad.carlos):
int x; int x; x = y + z;
If we ask the compiler to check syntax only
which shows there are no syntax errors, but:
This one is okay (the file is hello.carlos):
print "Hello";
The compiler produces, in hello.carlos.js:
(function () {
console.log("Hello");
}());
Running from another Java program
Look in the class edu.lmu.cs.xlg.carlos.Compiler — you'll see methods you can call to compile a Carlos program. If you would like to compile Carlos programs as part of a different application, just include carlos.jar and you're good to go.