C++
Overview
C++, the language:
- has been around under different names since 1983, and finally became an international standard in 1998 (ISO 14882) with updates in 2003, 2007, 2011, 2014, 2017, and 2020;
- is mostly a superset of C, but with a few significant incompatibilities;
- is primarily a systems language in which programmers must manage resources themselves, but provides features to make these tasks easier than one might think.
The Official Standard costs money, but if you are looking for an amazing online reference, this one is great.
Hello, World
Our obligatory first program:
#include <iostream>
int main() {
std::cout << "Hello, World\n";
}
To compile, just enter:
$ g++ -std=c++2a hello.cpp
This produces a.exe on Windows systems and a.out on most other systems. While developing small programs and running through your edit-and-run cycle, use (on non-Windows shells):
$ g++ -std=c++2a hello.cpp && ./a.out Hello, World
Example Programs
Let’s get a feel for what C++ programs “look like.” There are a lot of concepts illustrated in the three examples below, so there’s no need to follow every little detail; however, there are plenty of explanatory comments to help get you warmed up. (You wouldn’t use comments like these in production code; they are simply here to help you make sense of C++ as you learn the language.) We’ll cover the language more systematically after the examples.
This program prompts you for an integer then displays it with roman numerals:
// A program that illustrates how you might generate roman numerals.
// Overly commented for teaching purposes.
// It's common in C++ to use many libraries.
#include <iostream>
#include <string>
#include <vector>
#include <utility>
#include <stdexcept>
// Means we don't have to write std::vector, std::out_of_range, etc.
using namespace std;
// Function accepts a single int parameter and returns a string
string to_roman(int n) {
// out_of_range is one of the many exception type from the standard library
if (n <= 0) {
throw out_of_range("Romans don't have negatives");
} else if (n > 1E6) {
throw out_of_range("Number is too big to bother with");
}
// Vectors are contiguous-in-memory sequences that can grow and shrink at run
// time. We use them here because they are ordered and we need to check each
// component in order. Dictionaries are not ordered, so we use a vector of
// pairs. Note how there is no type just called "pair" in C++. The type
// pair<int, string> is different from pair<bool, bool> for example.
vector<pair<int, string>> mapping = {
{1000, "M"}, {900, "CM"}, {500, "D"}, {400, "CD"}, {100, "C"}, {90, "XC"},
{50, "L"}, {40, "XL"}, {10, "X"}, {9, "IX"}, {5, "V"}, {4, "IV"}, {1, "I"}
};
string numeral; // initialized to empty string
for (auto p: mapping) { // auto nicer than pair<int, string>
while (n >= p.first) {
numeral += p.second; // Yes, strings are mutable and += concats
n -= p.first;
}
}
return numeral;
}
// main is very special. After initializing global variables, main gets called.
// The return value of main is the process exit code for the operating system
// that runs the program. Weirdly, if you don't return anything C++ will return
// 0 from main. It does NOT do this for other functions, just for main.
int main() {
int n;
// cin is the standard input stream and cout is the standard output stream.
// << "puts" to a stream and >> "gets" from a stream.
cout << "Enter an integer:\n";
cin >> n;
try {
cout << n << " is " << to_roman(n) << '\n';
} catch (out_of_range e) {
cout << "unprocessable: " << e.what() << '\n';
return -1;
}
}
Compile and run:
$ g++ -std=c++2a roman.cpp && ./a.out Enter an integer: 9489 9489 is MMMMMMMMMCDLXXXIX
Let’s print some prime numbers:
// This program displays all the prime numbers up to and including 1000,
// using the famous algorithm of Erathostenes. Overly commented for teaching
// purposes.
#include <iostream>
#include <iomanip>
#include <vector>
using namespace std;
// The sieve is an array of 1001 bool values, indexed from 0 to 1000, all
// initialized to the value true.
vector<bool> sieve(1001, true);
// Writes the value false in each slot of the vector corresponding to
// a composite number. First, 0 and 1 are composite by definition. Then
// for each value starting with 2, if the value is still thought to be
// prime, we write false in each slot corresponding to its multiples.
// Note the parameter is marked with a & so that it is an alias for its
// argument; after all, we **want** to mutate the argument vector!
void check_off_composites(vector<bool>& s) {
s[0] = false;
s[1] = false;
for (auto i = 2; i * i < s.size(); i++) {
if (s[i]) {
for (auto j = i + i; j < s.size(); j += i) {
s[j] = false;
}
}
}
}
// Writes out all the values which correspond to positions in a vector
// containing the value true. Each value is written to standard output in
// a field of 8 characters. The parameter is marked with a & because if
// we didn't, a copy of the argument would be passed in, and a copy is
// expensive. However, we don't want to mutate the argument, so we mark
// the parameter const.
void display_true_indices(const vector<bool>& s) {
for (auto i = 0; i < s.size(); i++) {
if (s[i]) {
// Writes the number right-justified in a width of 5 cells
cout << setw(5) << i;
}
}
cout << '\n';
}
int main() {
check_off_composites(sieve);
display_true_indices(sieve);
}
$ g++ -std=c++2a primes.cpp && ./a.out 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223 227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479 487 491 499 503 509 521 523 541 547 557 563 569 571 577 587 593 599 601 607 613 617 619 631 641 643 647 653 659 661 673 677 683 691 701 709 719 727 733 739 743 751 757 761 769 773 787 797 809 811 821 823 827 829 839 853 857 859 863 877 881 883 887 907 911 919 929 937 941 947 953 967 971 977 983 991 997
Here’s the useful map class from the Standard Library:
// This program asks the user how to say some primary colors in Spanish
// then checks the user's answers to see if they are correct. Overly
// commented for teaching purposes.
#include <iostream>
#include <string>
#include <map>
using namespace std;
// We need a dictionary to store the word mappings. The English word will
// be the key and the Spanish word will be the value. As usual, you see a lot
// of braces in C++ initializers.
map<string, string> dictionary = {
{"blue", "azul"}, {"red", "rojo"}, {"green", "verde"}, {"brown", "marrón"}
};
// Asks the question and writes whether the answer was correct or not.
// Unfortunately, we only accept perfect exact answers in lowercase.
// Because C++ strings really just sequences of bytes, that may or may not
// but UTF-8, though they should be, you can't do fancy string processing
// like unicode normalization and collation without a big fancy library like
// ICU (https://stackoverflow.com/q/313970/831878). Since we are just learning
// C++, we're just going to punt here, and learn about strings later.
void test_user(string english_word) {
string answer;
cout << "How do you say " << english_word << " in Spanish? (lowercase)\n";
cin >> answer;
cout << "\"" << answer << "\" is ";
if (answer == dictionary[english_word]) {
cout << "correct\n";
} else {
cout << "is wrong; it's " << dictionary[english_word] << "\n";
}
}
int main() {
// During iteration, use an alias so we don't copy the key-value pair.
// It's also marked const as a way to say "we're not mutating it tho."
for (const auto& pair: dictionary) {
test_user(pair.first);
}
}
$ g++ -std=c++2a colors.cpp && ./a.out How do you say blue in Spanish? azul "azul" is correct How do you say green in Spanish? berde "berde" is is wrong; it's verde How do you say red in Spanish? rojo "rojo" is correct How do you say brown in Spanish? no sé "no sé" is is wrong; it's marrón
Types
Let’s start getting into details. Roughly speaking the type system of C++ has the following types and type formers in the core language:
| Types in the Core Language | |||
|---|---|---|---|
| Built-in | bool, char, unsigned char, signed char, wchar_t, char16_t, char32_t, short int, signed short int, unsigned short int, short, signed short, unsigned short, int, signed int, unsigned int, long int, signed long int, unsigned long int, long, signed long, unsigned long, float, double, long double | ||
| Type formers |
enum
* (raw pointer)
[ ] (array)
( ) (function)
[](){} (lambda function)
union
struct
class
| ||
More information on the fundamental types.
The standard library has a module called <cstdint> which contains a bunch of type abbreviations for integer types of known sizes (e.g., int32_t, uint64_t, and so on, if they exist in the implementation as they actually are not required). There are also a number of modules in the standard library defining dozens of types including string, vector, map, and on and on.
Basic Types
Nothing much surprising here, save for a few C++ syntax quirks to learn by example:
#include <cassert>
int main() {
bool young = (1 == 2) || true && false;
char c = '%'; // Old initialization syntax
char d('#'); // Modern initialization syntax
char e {'$'}; // Hypermodern initialization syntax
int x = 50 + int(c); // Type conversion
long y = 999999999999999999;
double z(353.13411);
short q; // Initializer not required
char16_t thorn = u'Þ'; // u prefix for char16_t
char16_t infinity = u'∞';
char32_t winky = U'😉'; // U prefix for char32_t
assert(young == false);
assert(c == '%' && d == '#');
assert(q == 0); // If no initializer, zero value is used
assert(double(x) == 87);
// Characters interchangeable with their integer codepoints
assert(thorn == 0xde && infinity == 0x221e && winky == 0x1f609);
}
The sizes of the types, other than for char, which is defined to be represented in one byte, are not guaranteed. On a typical machine you may see:
| Type | Size in Bytes | Range | Size guaranteed? |
|---|---|---|---|
| signed char | 1 | -128..127 | Yes |
| unsigned char | 1 | 0..255 | Yes |
| char | 1 | -128..127 | Yes |
| short | 2 | -32768..32767 | No |
| unsigned short | 2 | 0..65535 | No |
| int | 4 | -2147483648..2147483647 | No |
| unsigned int | 4 | 0..4294967295 | No |
| long | 8 | -9223372036854775808..9223372036854775807 | No |
| unsigned long | 8 | 0..18446744073709551615 | No |
| long long | 8 | -9223372036854775808..9223372036854775807 | No |
| unsigned long long | 8 | 0..18446744073709551615 | No |
Later, in the section on macros, we’ll see how you can query the sizes and the value ranges for your C++ implementation.
Structs
Structs are C++’s way of making objects with properties. You generally don’t make these on the fly! Instead, you use the struct keyword to define a type. Then you make objects of that type. Like so:
// Type definition
struct Point { double x; double y; }
// Object definition
Point p { 2, 8 };
We’ll go over the following example in class. Note that there is a lot to see here. First, there’s the syntax of the struct type declaration, then the syntax to create struct objects of the struct type. And member access via the dot notation. But the super important thing to learn here is this: structs, like bools and numbers, have value semantics, meaning that on assignment, passing to functions, and returning from functions, copies are made!
#include <cassert>
struct Point {
double x;
double y;
};
void demo_struct_assignment_is_a_copy() {
Point p {5, 8}; // Allocate whole struct here in stack
Point q; // Allocated as {0, 0}
q = p; // Assignment makes a COPY
q.x = 34; // So if we change a field of q...
assert(p.x == 5); // ...nothing changed in p
}
void some_function(Point p, double dx, double dy) {
p.x += dx; // p is a local variable whose fields were...
p.y += dy; // ...copied, so these change the local only
}
void demo_structs_are_passed_by_value() {
Point my_point {13, 55};
some_function(my_point, 10, 20); // Because a copy is made on passing...
assert(my_point.x == 13); // ...local point is unchanged
}
int main() {
demo_struct_assignment_is_a_copy();
demo_structs_are_passed_by_value();
}
Remember this!
The fact that copies of structs are made in C++ is a huge difference from JavaScript, Python, Java, and many other mainstream languages. It’s a big deal and worth remembering.
Are there ways to prevent these copies? Yep, you can use references or pointers.
References
References are strange beasts. Basically a reference is an alias. A reference is not a new object; rather, it’s just another name for an existing object. Therefore, you can use it to write a function to modify its argument (if you are into that kind of thing 😨), or pass a (possibly massive) struct without making an expensive copy.
We will walk through this example in class, in detail:
#include <cassert>
void demo_simple_references() {
int x; // Typical variable
int& y = x; // x and y alias the exact same memory
y = 100; // So this "changes x also"
assert(x == 100); // And here's the proof
x = 5; // Works the "other way around" of course
assert(y == 5); // No real magic, x and y are one
}
void f(int x, int& y) {
x = 100; // arg was copied to x, so arg is safe
y = 200; // y aliases it arg, so arg will change
}
void demo_reference_parameter_changes_its_argument() {
int a = 1, b = 2;
f(a, b);
assert(a == 1); // Unchanged, copy of a was passed
assert(b == 200); // Changed, b and the parameter are one
}
// References matter a LOT in the world of huge objects
struct Thing { int x; double y[1000000]; int z[5000]; };
void g(const Thing& thing) { // Reference parameter avoids the copy
assert(thing.y[500] == 0);
}
void demo_pass_a_huge_struct_by_reference() {
Thing t; // Tons of memory allocated here
g(t); // No copy made, yay
}
int main() {
demo_simple_references();
demo_reference_parameter_changes_its_argument();
demo_pass_a_huge_struct_by_reference();
}
References come in two flavors, & and &&. The latter is for rvalues only; the former will take either lvalues or rvalues. If overloaded, the rvalue-only one takes precedence for rvalues:
#include <cassert>
// f has only the lvalue version defined
int f(const int& x) { return 10; }
// g had both lvalue and rvalue versions defined
int g(const int& x) { return 20; }
int g(const int&& x) { return 30; }
// h has only the rvalue version defined
int h(const int&& x) { return 40; }
int main() {
int x = 42;
assert(f(x) == 10); // ok, x is an lvalue
assert(f(42) == 10); // ok, rvalue can be passed to &
assert(g(x) == 20); // ok, lvalue prefers &
assert(g(42) == 30); // ok, rvalue prefers &&
// assert(h(x) == 40); // won't compile, cannot pass lvalue to &&
assert(h(42) == 40); // ok, 42 is an rvalue
}
To summarize:
If a function has only a&version defined, then both l-values and r-values are passed to it. If only a&&version is defined, only r-values can be passed and passing an l-value is a compile-time error.
Wut was that all about? Hang in there. We’ll see what the big deal is soon.
Pointers
While references are aliases, pointers are objects that “point to” other objects. You can make a pointer to an existing object, or create a new object on the fly!
int x = 89;
int& r = x; // r is a REFERENCE, simply aliasing x
int* p1 = &x; // p1 is a POINTER to the existing object x
int* p2 = new int {55}; // p2 is a POINTER to a new, dynamically allocated object
// Since we invoked new, we better invoke delete later!
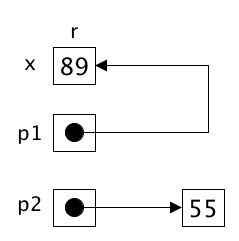
The difference between p1 and p2 above turns out to be important. To understand why, you must master the concept of static storage, stack storage, and heap storage.
- Static Storage is where the global variables (and some complex literals) go.
- Stack Storage is where the stack frames go.
- When a function is called, a new stack frame is allocated to hold the parameters, the local variables, the return address, and any other necessary bookkeeping data.
- At call time, the arguments are evaluated and copied to the parameters.
- When a function returns, the stack frame goes away. (Frames are not retained the way they are in languages with closures.)
- Heap Storage is where dynamically allocated data goes. In C++, if you allocate, you must deallocate. There is no automatic garbage collector. However you can use smart pointers and destructors to help you.
Okay enough blabbing. We’ll go over this example, featuring the built-in “raw” pointers, in class in excruciating detail. We’ll make all the important pictures on the board (so don’t expect to figure everything out from the notes below—class can be pretty useful).
#include <iostream>
#include <cassert>
using namespace std;
void demo_pointer_basics() {
int x = 10;
int* p = &x; // p "points to" x
*p = 7; // this changes x
assert(x == 7); // we say *p and x are aliases of each other
p = nullptr; // p pointes nowhere, *p will probably crash!
p = new int; // allocate memory at run time
*p = 12; // write to allocated memory
int* q = p; // p and q point to same place
*q = 10; // changes *p, too
assert(p == q && *p == 10);
q = new int {20}; // allocate and initialize at same time
assert(p != q && *q == 20); // p and q no longer point to same place
*q = 10;
assert(p != q && *p == *q); // obviously p was not affected
delete p; // the pointer vars were local, must clean up
delete q;
// If we didn't free up p and q we would have a MEMORY LEAK
// If you access *p and *q after deletion, you are using a DANGLING POINTER
}
void f(int a, int* b, int* c) {
a = 101; // does not affect the argument
*b = 102; // this change can be seen through the argument
c = &a; // no visible effect at all from the outside
}
void demo_pointer_arguments() {
int x = 1;
int y = 2;
int* p = new int {50};
f(x, &y, p);
assert(x == 1); // unchanged
assert(y == 102); // visible change
assert(*p == 50); // neither p nor *p affected
}
int* pointer_disaster() {
// Horrible C or C++ coding here: returning a pointer to a local (NOOOOO!)
int x = 8;
int* p = &x;
return p;
}
void demo_pointer_disaster() {
int* z = pointer_disaster(); // Shudder, awful, ...
cout << *z << '\n'; // this might be 8, but you NEVER KNOW
demo_pointer_arguments(); // overwrites pointer_disaster stack frame! Yow!
cout << *z << '\n'; // almost certainly not 8
}
void demo_pointer_to_struct() {
struct Point {double x; double y;};
Point* p = new Point {5, 8};
assert((*p).x == 5); // technically okay but ugly
assert(p->x == 5); // use this beautiful operator instead
delete p; // Important! *p is on the heap!
Point q {1, 2};
assert(q.x == 1 && q.y == 2); // No need to delete! q on stack, not heap
}
int main() {
demo_pointer_basics();
demo_pointer_arguments();
demo_pointer_disaster();
demo_pointer_to_struct();
}
Here’s a handy picture for what we’ve seen so far:
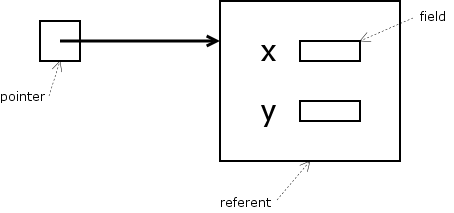
| If the pointer is called | Then the referent is called | and the field is called |
|---|---|---|
p | *p | (*p).x or p->x
|
| If the referent is called | Then the pointer is called | and the field is called |
|---|---|---|
s | &s | s.x
|
Okay so we’ve just touched the surface. But were you paying attention to that business with new and delete? You have to use these properly. You have to manage your own memory.
Is this stuff important?
Heck yeah. Managing your own memory is, yes, a really big deal. Consider this headline: Microsoft says 70% of all security bugs are memory safety issues.
Wow, right?
Declarators
When you declare entities in C++, you have to specify their type. Weirdly, you do not say “I’m declaring x with type T“; instead you give declarators, which are pretty hideous in hindsight, though some people love them. Examples are best for these:
int x, *y, z[5], *r[7], (*s)[7], ***q, a(int), *b(int), (*c)(int), **d[5][9];
These mean:
xis an int.*yis an int, thereforeyis a pointer to an int.z[i]for some i is an int, thereforezis an array of 5 ints.*r[i]is an int, soris an array of 7 pointers to ints.(*s)[i]is an int, sosis a pointer to an array of 7 ints.***qis an int, soqis a pointer to a pointer to a pointer to an int.a(i)is an int, soais a function taking in an int and returning an int.*b(i)is an int, sobis a function taking in an int and returning a pointer to an int.(*c)(i)is an int, socis a pointer to a function taking in an int and returning an int.**d[i][j]is an int, sodis an array of 5 arrays of 9 arrays of pointers to pointers to ints.
double (*f(int (*)(int, int[]), int)) (int, ...);
Constructors and Methods
Okay, back to structs. Functions inside of a struct are called methods. Methods that are not marked static are called instance methods. Within an instance method, the expression this is a pointer to the object on which the method is called. In addition to methods, structs can have constructors, which create objects of the struct type. Initialization of the struct's fields are done with a special syntax between the parameter list and the constructor body. We’ll dissect this one in class...and note some classic C++ features:
#include <cassert>
#include <cmath>
using namespace std;
struct Vector2D {
double i = 0.0;
double j = 0.0;
Vector2D() {} // same as Vector2D(): x(0), y(0) {} bc 0.0 is the default double
Vector2D(double i, double j): i(i), j(j) {}
Vector2D operator+(const Vector2D& v) { return Vector2D {this->i+v.i, this->j+v.j}; }
bool operator==(const Vector2D& v) { return this->i == v.i && this->j == v.j; }
double magnitude() { return hypot(this->i, this->j); }
static Vector2D ZERO;
};
// Static members have to be defined outside the class.
Vector2D Vector2D::ZERO(0, 0);
int main() {
Vector2D u; // u initialized to <0, 0>
Vector2D v(3, 5); // v initialized as <3, 5>
Vector2D w(v); // w is also <3, 5>, a COPY of v
assert(u.i == 0 && u.j == 0);
assert(u == Vector2D::ZERO);
assert(v == w);
v.i = 10;
assert(w.i == 3);
assert(!(v == w));
}
Operators
Did you notice in the last example how we customized the operators + and == to work on our own new type? How cool is that?
Here are the C++ operators from highest to lowest precedence. Note that some, but not all, can be customized.
| Prec | Operator | Description | Fixity | Assoc | Customizable? |
|---|---|---|---|---|---|
| Highest | :: | scope qualifier | Infix | L | No |
++ -- | increment / decrement | Postfix | — | Yes | |
() | function call | Yes | |||
[] | subscript | Yes | |||
. | member | Infix | L | No | |
-> | member of pointee | Yes | |||
++ -- | increment / decrement | Prefix | — | Yes | |
~ ! | bitwise negation / logical negation | Yes | |||
+ - | identity / unary negation | Yes | |||
& * | pointer-to / pointee | Yes | |||
new delete delete[] | allocation / deallocation | Yes | |||
sizeof | number of bytes in a type or expression | No | |||
(type) | old-style type-casting | No | |||
.* | pointer-to-member | Infix | L | No | |
->* | pointer-to-member | Yes | |||
* / % | multiply, divide, modulo | Infix | L | Yes | |
+ - | addition, subtraction | Infix | L | Yes | |
<< >> | left shift, right shift | Infix | L | Yes | |
< > <= >= | less-than / greater-than / less-or-equal-to / greater-or-equal-to | Infix | L | Yes | |
== != | equals / not-equals | Infix | L | Yes | |
& | bitwise AND | Infix | L | Yes | |
^ | bitwise XOR | Infix | L | Yes | |
| | bitwise OR | Infix | L | Yes | |
&& | logical AND | Infix | L | Yes | |
|| | logical OR | Infix | L | Yes | |
= *= /= %= += -= | assignment | Infix | R | Yes | |
?: | conditional | Infix | R | No | |
| Lowest | , | comma | Infix | L | Yes |
Note that you cannot define your own operators. You are limited to the ones that are built-in. You cannot change the precedence, associativity, or fixity. All you can do is define the behavior of certain operators for your new types.
It’s hard to exactly fit the conditional operator in the table. The middle expression is parsed as if it were parenthesized; in other words, you can still have a comma expression in there and things will work.
Overloading
If two functions with the same name and in the same scope have different enough signatures, the compiler will figure out which one to call at compile-time. If they aren’t different enough, the compiler will tell you the call is ambiguous and the program will not compile.
#include <iostream>
using namespace std;
int f(int x) { return x + 1; }
int f(string s) { return s[0] * 2; }
int main() {
cout << f(8) << " " << f("dog") << "\n";
}
Classes
It turns out the members of a struct (data members, constructors, and methods), are subject to access controls: they can be public, private, or protected. The only difference between a struct and a class in C++ is that the initial visibility of members in a class is private and for a struct, it’s public. Yep, that’s it. So these two things are totally equivalent:
class Counter {
int value;
public:
int next() { return ++this->value; }
};
struct Counter {
private:
int value;
public:
int next() { return ++this->value; }
};
In practice, though, most C++ programmers would use structs to bundle up data (passive data), but use a class when their objects are supposed to do fancy things (active objects). Technically, it doesn’t matter, but use this distinction to express your intent. Your fellow C++ programmers will appreciate you.
Templates
C++ is a statically-typed language meaning that we can tell the type of nearly every expression just by looking at the code, and not having to run it. This has some nice benefits:
- We can prove some things about the code without running it
- We can catch errors at compile time that would be nasty to debug at run time
- Editors can be smarter, with better type-ahead suggestions
It also has some interesting consequences. For example, the type “list of strings” is a different type from “list of integer”. And yet all the list operations need to be written just once, for any type! The way this is handled is to make a class template, parameterized by the type of list elements. Here’s a trivial example:
#include <cassert>
template <typename T, typename U, typename V>
struct Triple {
T first;
U second;
V third;
Triple(T x, U y, V z): first(x), second(y), third(z) {}
};
int main() {
Triple<int, int, bool> t1(8, 5, true);
Triple<double, char, unsigned long> t2(5.0, '#', 123456789012345);
assert(t1.second == 5);
assert(t2.third == 123456789012345);
}
The template by itself is not actually real code! it has to be instantiated to make a real class. In our case, there is no class called Triple! The actual classes are Triple<int, int, bool> and Triple<double, char, unsigned long> and these are created when needed.
array class in the standard library for a sneak peak.
Pointers as Members
Okay so moving on.... OH WAIT WAIT WAIT WAIT WAIT WAIT WAIT WAIT. Structs have value semantics, so...what if a member of a struct is a pointer? At least three huge problems surface that we need to be aware of:
- If the struct goes away (because, say, its enclosing function ends), we have to remember to deallocate its pointer member’s referents otherwise we’d have a memory leak!
- When the struct is copied (via initialization, argument passing, function return, or assignment), then by default, only the pointer (address), not the referent, is copied. This is called a shallow copy and may result in unintended sharing of state!. We must either (1) prohibit copying and assignment, or (2) cause copying and assignment to (magically) make copies of the referents behind the scenes!
- If we do arrange for copying to happen automatically, we might introduce efficiency problems! Returning a value and immediately assigning it, for example, would generate an extra copy. So would swapping.
The Rule of Five
Now the good news (Good news HAH you say because you are lucky and are programming in Rust 😁), yes the good news is that C++ provides some “hooks” for you to tap into to make value semantics happen magically. That is, it provides, in every struct or class:
- The destructor, which fires whenever the object goes out of scope or is otherwise deleted.
- The copy constructor, which fires whenever an object is being defined and initialized with an object of the same struct/class.
- The move constructor, which fires whenever an object is being defined and initialized with an object of the same struct/class, and the source object is known to never be used again.
- The copy assignment operator, which fires whenever an object is being assigned to from an object of the same struct/class.
- The move assignment operator, which fires whenever an object is being assigned to from an object of the same struct/class, and the source object is known to never be used again.
The only way to really get your head around all this, at least to begin with, is to see an example. Before we do this, let’s get this move vs. copy thing out of the way:
Move vs. Copy
- Copy
- When copying source to target, new resources are created by copying all of the source’s internal resources; these new resources become those of the target. The source is unchanged.
- Move
- When moving source to target, the target can simply pilfer the resources of the source, leaving the source empty. This is done by just setting the pointers inside target to the resources owned by source, then unhooking source’s pointers. Moves are faster because nothing new is created! (IRL moves are common: money is moved between accounts, batteries are moved between devices, physical things that are gifted or borrowed are moved between people.)
Okay, so remember: Your job as a C++ programmer is to make structs (and classes) that appear to behave like they have value semantics. This means that if you making a struct/class with pointer members, you have to override these five hooks to hide the fact that your objects are internally represented with pointers.
Here’s our example to study in class:
#include <cassert>
#include <iostream>
// This script is for exploration and study; here are some trackers that help.
int destructors_called = 0;
int copy_constructors_called = 0;
int move_constructors_called = 0;
enum Color {RED, GREEN, BLUE};
// A box has a color, and optionally, some contents. Since the box may be empty,
// we represent the contents by storing a pointer in the box representation. A
// null pointer indicates an empty box.
template<typename T>
struct Box {
private:
Color color;
T* content;
public:
// Constructors
Box(Color color = RED): color(color), content(nullptr) {}
Box(Color color, T data): color(color), content(new T(data)) {}
// Copy constructor - note how it makes a new content object. Called when
// initializing with another box, passing by value, or returning.
Box(const Box& other): color(other.color), content(new T(*other.content)) {
copy_constructors_called++;
}
// Move constructor - steals ownership of the resource from the other box
Box(Box&& other): color(other.color), content(other.content) {
other.content = nullptr;
move_constructors_called++;
}
// Destructor: automatically called when a box's lifetime ends. This could
// be when a box is a local variable and its enclosing function ends, or the
// box is in dynamic memory that is being deallocated.
~Box() {
destructors_called++;
delete content;
}
// Copy assignment operator. Assignment differs from construction because in
// assignment, an object already exists, which we have to clean up first.
Box& operator=(const Box& other) {
if (&other == this) return *this;
delete content; // Avoid memory leak
color = other.color;
content = other.content ? new T(*other.content) : nullptr;
return *this;
}
// Move assignment operator.
Box& operator=(Box&& other) {
if (&other == this) return *this;
delete content; // Avoid memory leak
color = other.color;
content = other.content;
other.content = nullptr;
return *this;
}
// Since we are creating a box that has value semantics, here’s an equality
// operator that works “by value”
bool operator==(const Box& other) {
return color == other.color && (
(content == nullptr && other.content == nullptr) ||
(content && other.content && *content == *other.content)
);
}
Color get_color() {return color;}
bool is_empty() {return content == nullptr;}
T get_content(T default_value) {return content ? *content : default_value;}
void set_content(T data) {if (content) *content = data; else content = new T(data);}
void remove_content() {content = nullptr;}
};
void demo_destructors_called() {
Box<double> b1;
Box<double> b2(GREEN);
Box<double> b3(RED, 23.0);
// Three destructors automatically called here, no memory leaks
}
void demo_copy_constructor_on_initialization() {
Box<double> b4(GREEN, 55.0); // local, defined in stack frame
Box<double> b5(b4); // initializes b5 with copy of b4
b5.set_content(88.0); // This copy should not affect the original
assert(b4.get_content(0) == 55.0); // Oh good
}
Box<int> f(Box<int> b) {
assert(copy_constructors_called == 2); // Copy constructor called when passing in
b.set_content(20);
return b;
}
void demo_constructors_on_calls_and_returns() {
Box<int> b6(GREEN, 925.0);
assert(copy_constructors_called == 1); // Just the one from before
Box<int> b7 = f(b6); // Move constructor on the return
assert(copy_constructors_called == 2);
assert(move_constructors_called == 1);
assert(b7.get_content(0) == 20);
}
int main() {
Box<double> b0(BLUE, 1.0); // Just a regular costructor
assert(copy_constructors_called == 0); // We didn't copy
assert(destructors_called == 0); // And it lives as long as main does
demo_destructors_called(); // This function will create 3 local boxes
assert(copy_constructors_called == 0); // without making any copies
assert(destructors_called == 3); // They all got destroyed at end of function
demo_copy_constructor_on_initialization();
assert(copy_constructors_called == 1);
assert(destructors_called == 5);
demo_constructors_on_calls_and_returns();
}
Just Saying No To Copies
Sometimes, instead of copying, you want to prohibit copying. In this case, you would mark both the copy costructor and the assignment operator deleted:
#include <cassert>
enum Color {RED, GREEN, BLUE};
template<typename T>
struct Box {
private:
Color color;
T* content;
public:
Box(Color color): color(color), content(nullptr) {}
Box(Color color, T data): color(color), content(new T(data)) {}
~Box() { delete content; }
Box(const Box&) = delete;
Box& operator=(const Box&) = delete;
Color get_color() {return color;}
bool is_empty() {return content == nullptr;}
T get_or_default(T default_value) {return content ? *content : default_value;}
void add_or_replace_content(T data) {if (content) *content = data; else content = new T(data);}
void remove_content() {content = nullptr;}
};
int main() {
Box<double> box1(GREEN, 21.0);
Box<double> box2(BLUE);
// Box<double> box3(box1); // ------> Will not compile, constructor deleted
// box1 = box2; // ------> Will not compile, assignment operator is deleted
}
More about Moves and Copies
So when do we move and when do we copy? The compiler knows! If it detects that the source is not going to be used (read from or written to) anymore, it will pick the move. The most common cases for this are:
- When the source is temporary.
- When the source is being returned from a function and what is being returned is a local variable or (normal, value) parameter of the function.
- When the source is a thrown object and the catch is in a different scope.
In each of these cases, the compiler needs to check you didn't actually bind the temporary, parameter, return value, or exception to some variable with a larger scope.
Smart Pointers
It’s a hell of a lot of work to track pointers in structs ourselves. So error prone, too! We might forget to delete or override one or more of the copy constructors, move constructors, or assignment operator! We might even forget the destructor and leak memory all over the place. Shouldn’t a resource be able to deallocate itself when it’s unreachable?
Yep. There are two kinds of smart pointers:, unique_ptr and shared_ptr.
- unique_ptr
- When a unique pointer can’t be referenced anymore, its associated referent will be deallocated. Only one unique_ptr can point to a resource at a time, so it is a compile-time error to copy a unique_ptr. They can be moved, though.
- shared_ptr
- When the “last” shared_ptr referencing a resource can no longer be accessed, the resource will be deallocated.
#include <cassert>
#include <memory>
using namespace std;
int destructors_called = 0;
struct Box {
~Box() { destructors_called++; }
};
void unique_pointer_demo() {
unique_ptr<Box> p(new Box);
// unique_ptr<Box> q(p); // ------> Compile-time error,
} // no unique_ptr copy constructor
void shared_pointer_demo() {
shared_ptr<Box> p(new Box);
shared_ptr<Box> q(p); // q & p both reference first box
if (true) {
shared_ptr<Box> r(new Box); // second box
shared_ptr<Box> s(q); // now three pointers to first box
} // second box deallocated here
assert(destructors_called == 2); // but irst box Not deleted yet
}
int main() {
unique_pointer_demo();
assert(destructors_called == 1);
shared_pointer_demo();
assert(destructors_called == 3);
}
Arrays
It takes some effort to learn exactly what is meant by an array in C++. The term is messy because C++ inherited this array thing from C, then provided fancier classes in its standard library.
C-style Arrays
C++ inherited “raw arrays” from the C language, along with all the ugly baggage, in particular that weirdness where if arr is a variable that stores a raw array, then we can treat arr as a pointer to the array’s first element, oh and that pointer arithmetic stuff. Need a refresher? We’ll go through this in class:
// Illustration of arrays. NOTE: Arrays in C++ are low-level objects and
// should only be used in low-level code, such as when implementing useful
// data structures or which maps to the hardware. They are tricky and do not
// behave like the other types. But you have to learn about them as everyone
// uses them and you have to read other people's code, and even write some
// low-level code yourself. In general, you will use vector and valarray
// from the standard library for application-level code.
#include <cassert>
#include <algorithm> // for copy and fill
int a[10]; // an array of 10 ints (global)
typedef int triple[3]; // a type declaration, NOT an object
triple t1, t2; // two more global arrays, each {0,0,0}
triple ones = {1, 1, 1}; // global array, explicitly initialized
void demo_local_arrays() {
// Space for a and b allocated in the stack frame
int a[50];
int b[20][10];
assert(b[2][5] == 0);
// At the end of this function a and b are automatically gone
}
void demo_dynamically_allocated_arrays() {
int* a = new int[5]{2, 3, 5, 7, 11};
assert(a[3] == 7); // Surprise!! (*a)[2] is actually wrong!
assert(*a == 2); // So arrays are like...pointers?
assert(*(a + 3) == 7); // Pointer arithmetic, amazing!
assert(*(3 + a) == 7); // And it is commutative, too
assert(3[a] == 7); // Surprised?
delete[] a; // Must do this to free up the 'new' memory
}
void demo_global_and_local_arrays_are_like_pointers_too() {
a[7] = 20;
assert(a[7] == 20);
assert(*(a + 7) == 20);
assert(*(7 + a) == 20);
assert(7[a] == 20);
bool b[] = {true, false, false, true};
assert(*(b + 2) == false);
}
void demo_array_assignment() {
// Arrays are not assignable
triple a = {10, 20, 30};
triple b = {1, 2, 3};
// a = b; ---> Compiler error: "array type is not assignable"
// But playing with pointers can get you into trouble
int* p = a;
p[2] = 100;
assert(a[2] == 100); // Well, ugh, perhaps.
const triple c = {1, 2, 3};
// p = c; ---> Compiler error: assigning to 'int *' from incompatible type 'const triple'
// There is a way to make an array copy though, using the copy function,
// however, this only works if you know the array's length. You better
// know the length because this will not be checked for you.
std::copy(b, b + 3, a);
assert(a[0] == 1 && a[1] == 2 && a[2] == 3);
}
// Hmmm, what do you think this does?
void move(triple t, int dx, int dy, int dz) {
t[0] += dx;
t[1] += dy;
t[2] += dz;
}
void demo_arrays_act_like_pointers_when_passed() {
triple c = {1, 2, 3};
move(c, 100, 100, 100);
assert(c[0] == 101 && c[1] == 102 && c[2] == 103);
// Why did c change even though the first parameter to move was not a
// reference parameter? Because the array name is actually treated
// as a pointer to the first element of the array!
// Here's something interesting:
std::fill(a, a + 10, 100);
move(a, 10, 10, 10);
assert(a[0] == 110 && a[1] == 110 && a[2] == 110);
move(&a[7], 10, 20, 30);
assert(a[7] == 110 && a[8] == 120 && a[9] == 130);
}
int main() {
// Show that globals are initialized to zero-values
assert(a[9] == 0);
assert(ones[1] == 1);
demo_local_arrays();
demo_dynamically_allocated_arrays();
demo_global_and_local_arrays_are_like_pointers_too();
demo_array_assignment();
demo_arrays_act_like_pointers_when_passed();
}
Pay attention to the part where if you allocate an array dynamically, you need to deallocate it with delete[], not simply delete.
Arrays in the Standard Library
It’s super important to understand the raw arrays in order to feel close to the machine. In practice, you will more often use sequence classes from the Standard Library that are built on top of the raw arrays. All of these classes represent efficiently indexable mutable sequences that occupy contiguous memory blocks:
- array: fixed-sized arrays that cannot grow and shrink. Size is part of its type.
- vector: arrays that can change in size. As you add and remove elements, the storage may have to be reallocated and moved, but the implementation should do so in a way to make all operations take amortized constant time.
- valarray: An array of values designed for mathetmatical operations, which can even be parallelized. You don’t add or remove elements, but you can call an explicit
resizeoperation.
#include <cassert>
#include <array>
#include <vector>
#include <valarray>
#include <iostream>
using namespace std;
void demo_arrays() {
array<int, 2> a = { 5, 8 };
array<int, 2> b = { 5, 9 };
array<int, 5> c = { 1, 2, 55, 2, 8 };
assert(b[1] == 9);
assert(a < b && b >= a && a != b); // comparison of same-sized arrays
b.fill(2); // 2 2
assert(b[0] == 2 && b[1] == 2);
b = a; // assignment is a copy
assert(&a != &b && a == b); // prove that it's a copy
}
void demo_vectors() {
vector<double> v = { 3.0, 5.0, 8.0 };
v.push_back(13.0); // 3 5 8 13
assert(v.size() == 4);
assert(v[2] == 8.0);
assert(v.front() == 3.0);
assert(v.back() == 13.0);
v.insert(v.begin() + 2, 144.0); // 3 5 144 8 13
v.pop_back(); // 3 5 144 8
vector<double> w = {3.0, 5.0, 144.0, 8.0};
assert(&v != &w); // do not point to same place
assert(v == w); // equality is by value
w.pop_back(); // 3 5 144
v = w; // assignment COPIES VALUES
assert(v.size() == 3); // copied three elements over
v.clear(); // blow away v
assert(v.size() == 0); // nothing left in v
assert(v.empty()); // another way to say that
assert(w.size() == 3); // show that w not affected, yay!
}
void demo_valarrays() {
valarray<int> a; // empty array
valarray<int> b(5); // 0 0 0 0 0
valarray<int> c(9, 5); // 9 9 9 9 9
int primes[] = {2, 3, 5, 7, 11, 13};
valarray<int> d(primes, 5); // 2 3 5 7 11
valarray<int> e = d * 3; // 6 9 15 21 33
e += c; // 15 18 24 30 42
assert(e.size() == 5);
assert(e.sum() == 129);
e.shift(2); // 24 30 42 15 18
e.shift(-1); // 18 24 30 42 15
assert(e.max() == 42);
e[4] = -2; // 18 24 30 -2 15
assert(e.max() == 30);
b = -e * d - c; // -39 -63 -129 -219 13
cout << e[1] << "\n";
assert(b.max()-b.min() == 232);
b.resize(3, 10); // 10 10 10
assert(b.size() == 3 && b.sum() == 30);
}
int main() {
demo_arrays();
demo_vectors();
demo_valarrays();
}
Strings
In a managed language, you would think strings would be really hard. Well yeah, they are, at the basic level....
C-style Strings
As in C, byte arrays terminated with a zero-byte are called strings. Annoyingly, because arrays act like pointers these things have reference semantics. Ouch. You can also get “strings” of other character types: they are raw arrays terminated by the correct zero. Just the basics:
// Illustration of the C-style strings in C++.
#include <cassert>
#include <cstring>
#include <iostream>
#include <iomanip>
using namespace std;
void inspect_8(const char* s) {
cout << '\n' << s << "\nUTF-8: ";
while (*s) {
cout << ' ' << hex << setfill('0') << setw(2) << (unsigned)(uint8_t)(*s++);
}
cout << "\n";
}
void inspect_16(const char16_t* s) {
cout << "UTF-16: ";
while (*s) {
cout << ' ' << hex << setfill('0') << setw(4) << (unsigned)(uint16_t)(*s++);
}
cout << "\n";
}
void inspect_32(const char32_t* s) {
cout << "UTF-32: ";
while (*s) {
cout << ' ' << hex << setfill('0') << setw(8) << (unsigned)(uint32_t)(*s++);
}
cout << "\n";
}
void demo_the_basic_string_as_byte_array() {
char just_a_char_array[3] = {'d', 'o', 'g'};
char actually_a_string[4] = {'d', 'o', 'g', (char)0};
char this_is_also_a_string[4] = {'d', 'o', 'g', '\0'};
char s[4] = "dog";
// String literals are arrays with the zero at the end
assert(s[0] == 'd' && s[1] == 'o' && s[2] == 'g' && s[3] == char(0));
// The string takes up one byte per character + one for the zero
assert(sizeof s == 4);
// strlen does not count the zero
assert(strlen(s) == 3);
}
void demo_char_stars_are_utf8() {
const char* bad = "a\xf1o"; // DISASTER! Code point of ñ is F1 but...
assert(strlen(bad) == 3);
inspect_8(bad); // ...Prints wrong because invalid UTF-8
const char* correct = "año"; // C++ knows what to do
assert(strlen(correct) == 4); // Because ñ is encoded as C3 B1
assert(correct[0] == (char)0x61); // 'a'
assert(correct[1] == (char)0xc3); // First byte of 2-byte encoding of ñ
assert(correct[2] == (char)0xb1); // Second byte of 2-byte encoding of ñ
assert(correct[3] == (char)0x6f); // 'o'
inspect_8(correct); // Prints beautifully!
}
void show_strings_as_different_sizes() {
inspect_8("año");
inspect_16(u"año");
inspect_32(U"año");
inspect_8("kōpa`a");
inspect_16(u"kōpa`a");
inspect_32(U"kōpa`a");
inspect_8("привет");
inspect_16(u"привет");
inspect_32(U"привет");
inspect_8("世界");
inspect_16(u"世界");
inspect_32(U"世界");
inspect_8("🐕🍱");
inspect_16(u"🐕🍱");
inspect_32(U"🐕🍱");
inspect_8("🇦🇽🏃🏽♀️");
inspect_16(u"🇦🇽🏃🏽♀️");
inspect_32(U"🇦🇽🏃🏽♀️");
}
int main() {
demo_the_basic_string_as_byte_array();
demo_char_stars_are_utf8();
show_strings_as_different_sizes();
}
Strings in the Standard Library
But good news, the standard library has a string type. It has value semantics and manages its own memory. Good times:
#include <cassert>
#include <string>
#include <iostream>
using namespace std;
void demo_the_basics() {
string s1 = "Hello", s2("Goodbye"), s3, s4(s2, 4, 3);
assert(s4 == "bye");
s3 = s1; // Assignment
s3[1] = 'u'; // Strings are...mutable?
assert(s3 == "Hullo"); // Yep, prove that they are mutable
assert(s1 == "Hello"); // Prove that assignment was a copy
assert(s2.length() == 7); // Show the length method
string s5 = s1 + ',' + " then " + s2; // + is concatentation
assert(s5 == "Hello, then Goodbye");
s5.replace(5, 6, " and"); // At pos 5, delete 6 chars, insert " and"
assert(s5 == "Hello and Goodbye");
assert(s1 > s2); // Lexicographic compare FTW
}
void demo_additional_functionality() {
string s = "abcdefghij";
assert(s.front() == 'a');
assert(s.back() == 'j');
assert(s.at(5) == 'f');
assert(s[5] == 'f');
s.insert(5, "OOO");
assert(s == "abcdeOOOfghij");
s.push_back('k');
s.erase(5, 3);
assert(s == "abcdefghijk");
s.pop_back();
s += "ZZZ";
assert(s == "abcdefghijZZZ");
assert(s.find('Z') == 10);
assert(s.rfind('Z') == 12);
}
void demo_lengths() {
string s1 = "José is a 🏄🏽 from 🇲🇽";
u16string s2 = u"José is a 🏄🏽 from 🇲🇽";
u32string s3 = U"José is a 🏄🏽 from 🇲🇽";
assert(s1.length() == 33 && s2.length() == 24 && s3.length() == 20);
}
int main() {
demo_the_basics();
demo_additional_functionality();
demo_lengths();
}
Note you’ll probably use strings from the standard library most of the time. HOWEVER, you will see the dangerous raw strings from time to time, especially if you use command line arguments.
Command Line Arguments
Now that you’ve seen those horrible, unsafe C-style strings, you’re ready for command line arguments! When your C++ program is loaded into memory by the operating system, the program startup code arranges to call main with (at least) two arguments. The first, argc is the number of tokens passed to your program (including the program name); the second argv is a C-style arrays, whose values are C-style strings of each of the tokens. Example:
#include <iostream>
int main(int argc, char** argv) {
std::cout << "Number of args, including command: " << argc << '\n';
for (int i = 0; i < argc; i++) {
std::cout << "argv[" << i << "] is " << argv[i] << '\n';
}
}
$ g++ -std=c++2a args.cpp && ./a.out drake 'lady gaga' beyoncé Number of args, including command: 4 argv[0] is ./a.out argv[1] is drake argv[2] is lady gaga argv[3] is beyoncé
Files
C++ has a rather interesting approach to stream processing. Here’s a little example to get you acquainted; you’ll want to consult a reference for more details.
// This program displays the average of a bunch of floating point numbers.
// If no commandline arguments are given, it prompts the user for a file
// name and averages the numbers from that file. If exactly one command line
// argument is given, it takes the argument to be a file name and averages
// the numbers in that file. If more than one command line argument is
// given, it assumes they are all numbers and displays the average of them.
//
// Files of numbers must contain ONLY numbers (and whitespace), if any other
// character appears the program will fail with an error message. When
// averaging command line arguments, each argument must be a legal floating
// point number without trailing whitespace.
//
// The program returns 0 on success, and -1 on failure.
#include <fstream>
#include <iostream>
#include <string>
#include <sstream>
using namespace std;
// Returns the average of the numbers in the file named by filename. Assumes
// the file contains ONLY numbers (and whitespace). If it finds any other
// characters it throws an exception.
double average_from_file(string filename) {
// Open the file if you can. If you can't, throw a string stating that
// the file that could not be opened.
ifstream file;
file.open(filename.c_str());
if (!file) {
throw string("File '" + filename + "' not found");
}
// Accumulate the sum and count the values throughout the file.
// Immediately throw if any problems are found.
double sum = 0.0;
int number_of_values = 0;
double value;
while (true) {
file >> value; // get the next float value
if (file.bad()) { // always check for trashed files
throw string("Corrupted file");
}
if (file.fail()) { // couldn't read a float
if (file.eof()) { // if it's because you're at eof
break; // ... that's actually fine
}
throw string("Garbage in file");
}
sum += value;
number_of_values++;
}
// Return the answer if you can compute it, otherwise throw.
if (number_of_values == 0) {
throw string("Nothing to average");
}
return sum / number_of_values;
// Note there is no need to explicitly close the ifstream in C++ because of
// something called RAII. The destructor for f will automatically be called
// at the end of this function, and the destructor closes the stream.
}
// Computes the average of the C-strings in positions 1 .. argc-1 in the array
// argv interpreted as floats.
double average_of_command_line_arguments(int argc, char** argv) {
double sum = 0.0;
for (auto i = 1; i < argc; i++) {
istringstream argument(argv[i]);
double value;
argument >> value;
// Ensure it is a legal float without trailing characters.
if (argument.bad() || argument.fail() || !argument.eof()) {
throw string("Non-numeric command line argument ") + argv[i];
}
sum += value;
}
return sum / (argc - 1);
}
// The main function interprets the command line, defers to one of the helper
// routines to compute the average, then displays either the average or any
// error messages that were thrown.
int main(int argc, char** argv) {
double average;
try {
if (argc == 1) {
string filename;
cout << "What file do you want to average the values in? ";
cin >> filename;
average = average_from_file(filename);
} else if (argc == 2) {
average = average_from_file(argv[1]);
} else {
average = average_of_command_line_arguments(argc, argv);
}
cout << "The average is " << average << '\n';
} catch (string s) {
cerr << "Error: " << s << "\n";
return -1;
}
}
Memory Layout
C++ will let you get the address of just about anything. How? Well pointers are actually addresses, so yeah, they print as integers 😱:
#include <iostream>
using namespace std;
double global;
struct Point3D {
double x;
double y;
double z;
};
int main() {
double d;
bool b1, b2;
Point3D p1;
Point3D* p2 = &p1;
Point3D p3;
Point3D* p4 = new Point3D;
int a[10];
int z[5];
cout << "global is at " << &global << "\n";
cout << "A string literal was placed at " << &"hello" << "\n";
cout << "d is at " << &d << "\n";
cout << "b1 is at " << &b1 << "\n";
cout << "b2 is at " << &b2 << "\n";
cout << "p1 is at " << &p1 << "\n";
cout << "The fields of p1 are at " << &p1.x << ", " << &p1.y << ", " << &p1.z << "\n";
cout << "p2 is at " << &p2 << "\n";
cout << "*p2 is at " << &(*p2) << " which should be the same as " << p2 << "\n";
cout << "p3 is at " << &p3 << "\n";
cout << "p4 is at " << &p4 << "\n";
cout << "*p4 is at " << &(*p4) << " which should be the same as " << p4 << "\n";
cout << "a is at " << &a << "\n";
cout << "z is at " << &z << "\n";
}
This program produces different results depending on the underlying operating system and system state. Here’s a run from my machine:
$ g++ -std=c++2a addresses.cpp && ./a.out global is at 0x1069710e8 A string literal was placed at 0x106970ed8 d is at 0x7ffee9290838 b1 is at 0x7ffee9290837 b2 is at 0x7ffee9290836 p1 is at 0x7ffee9290818 The fields of p1 are at 0x7ffee9290818, 0x7ffee9290820, 0x7ffee9290828 p2 is at 0x7ffee9290810 *p2 is at 0x7ffee9290818 which should be the same as 0x7ffee9290818 p3 is at 0x7ffee92907f8 p4 is at 0x7ffee92907f0 *p4 is at 0x7f8130402890 which should be the same as 0x7f8130402890 a is at 0x7ffee9290860 z is at 0x7ffee9290840
A picture might help:
******** STATIC ********
| |
+-----+-----+-----+-----+-----+-----+-----+-----+
106970ed8 | 'h' | 'e' | 'l' | 'l' | 'o' | 00 | |
+-----+-----+-----+-----+-----+-----+-----+-----+
| |
. . .
| |
+-----+-----+-----+-----+-----+-----+-----+-----+
1069710e8 | global |
+-----+-----+-----+-----+-----+-----+-----+-----+
| |
******** HEAP ********
| |
+-----+-----+-----+-----+-----+-----+-----+-----+
7f8130402890 | *p4 (a.k.a p4->x) |
+-----+-----+-----+-----+-----+-----+-----+-----+
7f8130402898 | p4->y |
+-----+-----+-----+-----+-----+-----+-----+-----+
7f81304028A0 | p4->z |
+-----+-----+-----+-----+-----+-----+-----+-----+
| |
******** STACK ********
| |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee92907f0 | p4 |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee92907f8 | p3.x |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290800 | p3.y |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290808 | p3.z |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290810 | p2 |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290818 | p1.x |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290820 | p1.y |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290828 | p1.z |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290830 | [6 bytes padding] | b2 | b1 |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290838 | d |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290840 | z[0] | z[1] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290848 | z[2] | z[3] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290850 | z[4] | [4 bytes padding] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290858 | [8 bytes padding] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290860 | a[0] | a[1] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290868 | a[2] | a[3] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290870 | a[4] | a[5] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290878 | a[6] | a[7] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290880 | a[8] | a[9] |
+-----+-----+-----+-----+-----+-----+-----+-----+
7ffee9290888 | |
If you know a little bit about hardware, you may have heard of alignment. Do you see how alignment is maintained with padding above? You’ll also see padding in an array of structs, where each struct has a size that is not a multiple of the underlying hardware’s alignment preference.
sizeof operator. See if you figure out if it is sensitive to alignment and padding.
Functions
Functions are values in C++. You can use (1) regular functions, (2) function objects, and (3) lambdas.
Defined Functions as Values
#include <cassert>
int square(int x) { return x * x; }
int times_two(int x) { return x * 2; }
typedef int fun(int);
int twice(fun f, int x) { // we could also say twice(int f(int), x)
return f(f(x));
}
int main() {
assert(twice(square, 3) == 81); // note how we say square, not square()
assert(twice(times_two, 10) == 40);
}
Function Objects
Any object of a class overloading operator() is called a function object and is callable:
#include <cassert>
class Line {
double m;
double b;
public:
Line(double slope, double intercept): m(slope), b(intercept) {}
double operator()(double x) { return m * x + b; }
};
int main() {
Line line1(5, 3);
Line line2(-2, 8);
assert(line1(3) == 18 && line1(-2) == -7);
assert(line2(3) == 2 && line2(-2) == 12);
}
Lambdas
A lambda is essentially an anonymous function. You need to be explicit about the entities you capture from the outer scope. A quick example first:
#include <cassert>
auto do_nothing = [](){};
auto times_two = [](auto x){return x * 2;};
double square(double x) {return x * x;}
auto compose = [](auto f, auto g) {
return [f, g](double x){return f(g(x));};
};
int main() {
do_nothing();
assert(times_two(21) == 42);
auto square_then_times_two = compose(times_two, square);
auto times_two_then_square = compose(square, times_two);
assert(square_then_times_two(10) == 200);
assert(times_two_then_square(10) == 400);
}
:Lambda expressions (in their basic form) look like this:
[ capture ]( parameters ) -> type { body }
[ capture ]( parameters ) { body }
The capture clause can be [] to capture nothing, [=] to capture everything by copy, [&] to capture everything by reference. You can also specify exactly what to capture, e.g., [x, &y] to capture x by copy and y by reference.
There’s more to it, but this will do for now.
Standard Library Algorithms
Function objects are commonly used in algorithms such as for_each, count, count_if, find, find_if, and so on. Unlike many other OO languages, C++ does not define these functions as methods within collection types. Instead the <algorithm> library contains very general algorithms, including those that iterate over sequences.
The for_each function (seen in the following example) takes a "start", an "end", and a function to apply at each item between the start (inclusive) and end (exclusive). Plain old C-style strings are sequences, with the start being the string itself, and the end being, well one character past the end of the string.
#include <iostream>
#include <algorithm>
#include <cctype>
using namespace std;
int main(int argc, char** argv) {
if (argc != 2) {
cerr << "This program requires exactly one command line argument\n";
return -1;
}
char* word = argv[1];
auto is_lower_char = [](char c){ return islower(c); };
int lowercase_count = count_if(word, word + strlen(word), is_lower_char);
cout << lowercase_count << " lowercase letters in: " << word << endl;
}
Most of the container classes from the standard library have begin and end methods:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
vector<int> v {5, -8, 1, 2, 34, 55, 13};
transform(v.begin(), v.end(), v.begin(), [](int x){ return x * x; });
for (auto x: v) {
cout << x << '\n';
}
}
Here is a small sampling of the standard algorithms:
| for_each(first, last, f) | Executes f(x) for each x in [first, last) |
| any_of(first, last, p) | Whether p(x) for some x in [first, last) |
| all_of(first, last, p) | Whether p(x) for all x in [first, last) |
| count(first, last, x) | Number of times x appears in [first, last) |
| count_if(first, last, p) | Number of items x in [first, last) for which p(x) is true |
| find_if(first, last, p) | Find the first element in [first, last) for which p(x) is true |
| fill(first, last, x) | Fills [first, last) with x |
| transform(first, last, dest, f) | Writes f(x) for each x in [first, last) to the destination starting at dest |
| swap(x, y) | Swaps x and y |
| reverse(first, last) | Reverses the elements in [first, last) |
| shuffle(first, last, urbg) | Shuffles [first, last) according to the given uniform random bit generator (you can find some of these elsewhere in the standard library) |
| partition(first, last, p) | Reorders [first, last) so that all elements x for which p(x) is true precede the elements y for which p(y) is false (Relative order is not preserved) |
| sort(first, last, comp) | Sorts [first, last) using comparator comp |
| clamp(x, lo, hi) | Clamps x to the range [lo, hi] |
| . . . | . . . |
You know what? There are about EIGHTY of these! Check out the complete reference.
Containers
The standard library for C++ contains a whole bunch of template classes for containers, including:
| array | static contiguous array, fixed size |
| vector | dynamic contiguous array, variable size |
| deque | double-ended queue |
| forward_list | singly-linked list |
| list | doubly-linked list |
| set | collection of unique keys, sorted by key |
| map | collection of key-value pairs, keys are unique, sorted by key |
| multiset | collection of keys, sorted by key |
| multimap | collection of key-value pairs, sorted by key |
| unordered_set | collection of unique keys, hashed by key |
| unordered_map | collection of key-value pairs, keys are unique, hashed by key |
| unordered_multiset | collection of keys, hashed by key |
| unordered_multimap | collection of key-value pairs, hashed by key |
| stack | adapts a container to function as a stack |
| queue | adapts a container to function as a queue |
| priority_queue | adapts a container to function as a priority_queue |
Here’s a function showing some containers and algorithms in action:
vector<pair<string, int>> sorted_word_counts(list<string> words) {
map<string, int> counts;
for (string word : words) {
counts[word]++;
}
auto value_descending = [](auto x, auto y) { return y.second < x.second; };
vector<pair<string, int>> pairs(counts.begin(), counts.end());
sort(pairs.begin(), pairs.end(), value_descending);
return pairs;
}
Class Inheritance
Here’s a pretty standard example. A lot is going on, so we’ll go over it in class. One good thing to know: the C++ uses the terms base class and derived class instead of superclass and subclass.
#include <sstream>
#include <string>
#include <cassert>
using namespace std;
class Animal {
protected:
string name;
virtual string sound() = 0;
public:
Animal(string name): name(name) {}
string speak() {
return (stringstream() << name << " says " << sound()).str();
}
};
class Cow: public Animal {
protected:
string sound() override {
return "moooo";
}
public:
Cow(string name): Animal(name) {}
};
class Horse: public Animal {
protected:
string sound() override {
return "neigh";
}
public:
Horse(string name): Animal(name) {}
};
class Sheep: public Animal {
protected:
string sound() override {
return "baaaa";
}
public:
Sheep(string name): Animal(name) {}
};
int main(int, char**) {
Animal* h = new Horse("CJ");
assert(h->speak() == "CJ says neigh");
Animal* c = new Cow("Bessie");
assert(c->speak() == "Bessie says moooo");
assert((new Sheep("Little Lamb"))->speak() == "Little Lamb says baaaa");
}
Macros
Macros are evaluated during a preprocessing phase, before the program is even compiled. While they have quite a few uses, we’ll just look at how to use them for lazy evaluation:
#include <cassert>
int f_calls = 0;
int g_calls = 0;
int f() {
f_calls++;
return 1;
}
int g() {
g_calls++;
return 2;
}
template <class T> bool if_then_else(bool x, T y, T z) {
return x ? y : z;
}
#define IF_THEN_ELSE(x, y, z) ((x)?(y):(z))
int main() {
if_then_else(true, f(), g());
if_then_else(false, f(), g());
assert(f_calls == 2 && g_calls == 2);
IF_THEN_ELSE(true, f(), g());
assert(f_calls == 3 && g_calls == 2);
IF_THEN_ELSE(false, f(), g());
assert(f_calls == 3 && g_calls == 3);
}
Note macros are like templates! They are not really code. They only cause code to be created when they are instantiated.
Here’s a macro that gets information about C++ numeric types on the current platform:
#include <cstdint>
#include <climits>
#include <cassert>
#include <iostream>
using namespace std;
#define show_type_range(t, min, max)\
cout << #t << " (" << sizeof(t) << " bytes): " << min << ".." << max << '\n';
int main() {
show_type_range(signed char, SCHAR_MIN, SCHAR_MAX)
show_type_range(unsigned char, 0, UCHAR_MAX)
show_type_range(char, CHAR_MIN, CHAR_MAX)
show_type_range(short, SHRT_MIN, SHRT_MAX)
show_type_range(unsigned short, 0, USHRT_MAX)
show_type_range(int, INT_MIN, INT_MAX)
show_type_range(unsigned int, 0, UINT_MAX)
show_type_range(long, LONG_MIN, LONG_MAX)
show_type_range(unsigned long, 0, ULONG_MAX)
show_type_range(long long, LLONG_MIN, LLONG_MAX)
show_type_range(unsigned long long, 0, ULLONG_MAX)
show_type_range(int8_t, INT8_MIN, INT8_MAX)
show_type_range(uint8_t, 0, UINT8_MAX)
show_type_range(int16_t, INT16_MIN, INT16_MAX)
show_type_range(uint16_t, 0, UINT16_MAX)
show_type_range(int32_t, INT32_MIN, INT32_MAX)
show_type_range(uint32_t, 0, UINT32_MAX)
show_type_range(int64_t, INT64_MIN, INT64_MAX)
show_type_range(uint64_t, 0, UINT64_MAX)
show_type_range(intmax_t, INTMAX_MIN, INTMAX_MAX)
show_type_range(uintmax_t, 0, UINTMAX_MAX)
}
On my MacBook Pro, I got:
$ g++ -std=c++2a numerictypes.cpp && ./a.out signed char (1 bytes): -128..127 unsigned char (1 bytes): 0..255 char (1 bytes): -128..127 short (2 bytes): -32768..32767 unsigned short (2 bytes): 0..65535 int (4 bytes): -2147483648..2147483647 unsigned int (4 bytes): 0..4294967295 long (8 bytes): -9223372036854775808..9223372036854775807 unsigned long (8 bytes): 0..18446744073709551615 long long (8 bytes): -9223372036854775808..9223372036854775807 unsigned long long (8 bytes): 0..18446744073709551615 int8_t (1 bytes): -128..127 uint8_t (1 bytes): 0..255 int16_t (2 bytes): -32768..32767 uint16_t (2 bytes): 0..65535 int32_t (4 bytes): -2147483648..2147483647 uint32_t (4 bytes): 0..4294967295 int64_t (8 bytes): -9223372036854775808..9223372036854775807 uint64_t (8 bytes): 0..18446744073709551615 intmax_t (8 bytes): -9223372036854775808..9223372036854775807 uintmax_t (8 bytes): 0..18446744073709551615
Standard Library Headers
One nice thing about C++: it’s standard library is massive. There are modules for coroutines, utilities, strings, containers, iterators, ranges, algorithms, numerics, input/output, localization, regular expressions, atomics, threads, filesystem interfacing, dynamic memory management, error handling, and more.
Miscellaneous Technical Stuff
Here are some things that are impossible to cover in detail in a short page of notes, but that are important to know. For the following topics, there’s just barely enough to get you started.
Initialization
Interested in a topic that gets C++ experts all excited? (I saved it until near the end because it is crazy.)
Initialization is a big topic in C++. To fully understand it, you have to study the reference manual. And probably study it a long time. As a programmer, you can try to stay sane by always providing initial values in your definitional declarations, e.g.,
Point p {5, 8};
int x = 200;
Stack<std::string> s(100);
Player* p = new Player(name, max_health, category);
If you do not specify an initial value (e.g., int x;, new Player()), then you will need to be very keenly aware of (among others!):
While you’d have to see the official language standard for full details, remember these big picture ideas:
- Zero initialization “makes all the bits zero.”
- Zero initialization (generally) applies to variables with static or thread-local storage duration (and this happens before other initializations).
- Default initialization is generally done by calling default constructors.
- For variables of simple types like numbers and pointers that have automatic storage duration, the default initialization initializes these values to indeterminate values.
C++ Program Structure
Good to know:
- A C++ program resides in a set of files.
- Each file is a sequence of top-level declarations which can be (1) type declarations, (2) object declarations, (3) function declarations, (4) namespace declarations, or (5) directives.
- Entities need to be declared before they are used. That’s why the
#includedirective is so important. - When compiling a program made up of several files, be careful that you don’t link in old compiled code. Use a program development environment that manages your project automatically.
Example:
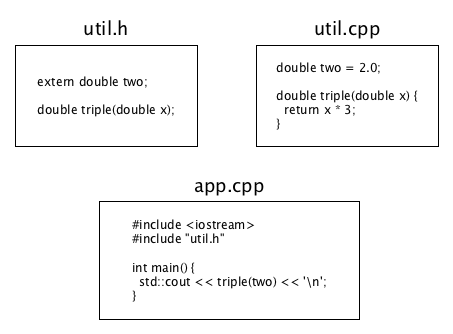
To run:
$ g++ -std=c++2a util.cpp app.cpp && ./a.out 6
#ifdef, #ifndef, and #endif. Find an example of their use, and explain why they were needed.
Declarations and Definitions
A C++ program resides in a set of files. Each file is a sequence of top-level declarations. A declaration introduces a name into a program. A declaration can be definitional or non-definitional. A definition actually creates a thing. Here are examples of definitional declarations:
// Examples of C++ declarations that are ALSO definitions.
#include <cassert>
// Object declarations + definitions
int x = 100;
int y;
// Function declaration + definition
double triple(double x) {
return x * 3;
}
// Type declaration + definition
struct Point {
double x;
double y;
};
// Namespace declaration + definition
namespace Example {
int x = 200;
Point p {3, 5};
Point q;
}
int main() {
assert(x == 100 && y == 0 && Example::x == 200);
assert(triple(2.5) == 7.5);
assert(Example::p.x == 3 && Example::p.y == 5);
assert(Example::q.x == 0 && Example::q.y == 0);
}
There are only five kinds of non-definitional declarations: which can be (1) type declarations, (2) object declarations, (3) function declarations, (4) namespace declarations, or (5) directives.
| Declaration | Example | Explanation |
|---|---|---|
| Incomplete Class | class Dog; | This says a class called Dog exists, and you can use it to declare variables of type Dog* for instance. The class has to be eventually defined somewhere else in the program, of course.
|
| External Variable | extern int x; | This says a variable x is defined elsewhere. You can start using it now though. It must be eventually defined and available at run time. There can only be one global variable named x. If it is used in multiple compilation units, all but one must have an extern declaration.
|
| Function Prototype | double mag(Vector v); | This specifies how the function mag is called and what it returns. It has to be defined elsewhere, of course.
|
| Typedef | typedef struct {
double x;
double y;
} point; | Simply means that the word point is an abbreviation for the type expression.
|
| Static Data Member | class C {
static int x;
}; | Somewhat surprisingly, the static x member must be defined outside of the class.
|
Entities need to be declared before they are used. (That’s why the #include directive is so important). Every top level name must have exactly one definition, so you can’t duplicate a global variable definition, and you can’t declare something extern in one file and forget to supply it in another file when the program is linked.
Identifiers have:
- Scope (where in source code text its binding is visible)
- block
- function
- prototype
- file
- class
- Storage Duration (how long it lives)
- static
- automatic
- thread
- dynamic
- Linkage
- external
- internal
- none
Details here.
The scope resolution operator (::)
Learn about this things this operator does by an example:
#include <iostream>
using namespace std;
int x = 1;
namespace N {
int x = 2;
};
struct C {
int x = 3;
void f() {
int x = 4;
cout << x << this->x << C::x << N::x << ::x << "\n";
}
};
int main() {
C().f();
}
Things We Did Not Cover
C++ is a massive language. This introduction skipped a lot. A whole lot. Things not covered include, but are not limited to:
- The operators
.*, and->* explicitmutable- Writing your own type conversion
- Private class derivation
- Virtual vs. pure virtual function
- Why destructors should be virtual
- declaring bodies inside the class vs. outside
- Details of access controls
- Variadic templates
- Defaulted functions
- Thread-local storage
- decltype
- static_cast, dynamic_cast, etc.
- Execution policies for parallel execution
- Hundreds of other things, no doubt
More Information
Here are some fine sources for more information: