Database Models
Key-Value Stores
Key-value databases are mappings of keys to values. For example:
| testing | false |
| domain | "lmu.edu" |
| max_content_length | 2097152 |
| commands | ["configure", "make", "make install"] |
| sales:2016:11 | 89432 |
| sales:2016:12 | 91123 |
| sales:2017:01 | 9078 |
| sales:2017:02 | 8819 |
| available_colors | {"blue", "turquoise", "violet", "cyan", "seagreen"} |
| employees_from | {"CA": 293, "NV": 11, "RI": 12, "HI": 17} |
| leaderboard | {marko(872), kat(711), meixian(733), alex(687), sean(599)} |
Keys are generally strings. Values can be numbers, booleans, strings, lists, sets, sorted sets, or hashes.
You generally can’t query on partial keys, e.g., you can’t easily ask for all sales in 2016.
Popular Key-Value Stores:
Document Stores
Document databases are generally made up of collections, each holding documents. Documents are generally free-form (nested) objects. For example, here are some documents in a movies collection:
{
"_id": 4647782, "type": "Feature Film", "status": "Released",
"people": [{"person_id": 42297, "role": "Director", "group": "Director"}],
"countries": ["United States", "Jamaica"],
"titles": [{"main": true, "name": "Still Moving: Patti Smith"}]
}
|
{
"_id": 4647783, "type": "Feature Film", "status": "Released",
"people": [{"person_id": 36075, "role": "Actor", "group": "Cast"}],
"countries": ["Italy"],
"titles": [{"main": true, "name": "Ultimatum"}]
}
|
{
"_id": 4648539, "type": "Feature Film", "status": "Released",
"ratings": [{"source": "MPAA", "value": "PG"}],
"countries": ["United States"],
"box_office": 2071091.0,
"people": [
{"person_id": 38316, "role": "Actor", "group": "Cast"},
{"person_id": 31894, "role": "Actor", "group": "Cast", "credit": "cameo"},
{"person_id": 38193, "role": "Actor", "group": "Cast", "credit": "cameo"},
{"person_id": 40836, "role": "Actor", "group": "Cast"},
{"person_id": 41626, "role": "Director", "group": "Director"},
{"person_id": 32279, "role": "Executive Producer", "group": "Production"},
{"person_id": 34607, "role": "Producer", "group": "Production"},
{"person_id": 34547, "role": "Associate Producer", "group": "Production"},
{"person_id": 41626, "role": "Screenplay", "group": "Writing"},
{"person_id": 34547, "role": "Screenplay", "group": "Writing"},
{"person_id": 39554, "role": "Cinematographer", "group": "Camera, Film, Tape"},
{"person_id": 39954, "role": "Music", "group": "Music"},
{"person_id": 34477, "role": "Music", "group": "Music"},
{"person_id": 44020, "role": "Music Producer", "group": "Music"}
],
"companies": [
{"role": "Studio", "group": "Studio", "company_id": 46232},
{"role": "Domestic Theatrical Distributor", "group": "Distribution", "company_id": 46208},
{"role": "Domestic Video Distributor", "group": "Distribution", "company_id": 45788}
],
"locations": [
"Costa Rica", "South Africa", "Australia", "New Zealand", "Fiji", "Tahiti,
French Polynesia", "Java, Indonesia", "Bali, Indonesia", "Hawaii, USA"
],
"titles": [
{"main": true, "type": "name": "Endless Summer II"},
{"name": "Bruce Brown's The Endless Summer 2"}
]
}
|
Queries might look like
films.find({"ratings.value":"G"}, {titles:{$elemMatch:{main:true}}}).limit(5)
When collections are independent of each other, everything is great. Otherwise, you have to (1) repeat nested objects or (2) use references. Querying across collections is generally not well supported by the native query language; you have to do such things programmatically. If you are doing too many of these joins, you probably don’t want to use a document store!
Popular Document Stores:
Relational Stores
Relational databases are generally made up of tables, each holding rows. Rows represent objects. Unlike document databases, where documents can contain anything, each row in a table has only the properties of that table. We say relational datbases have a fixed schema while document databases have a flexible schema. (Of course, nothing stops you from making a table with columns holding JSON....)
Here is the database we saw earlier:
| Author | ||
|---|---|---|
| id | name | country |
| 1 | J.D. Salinger | USA |
| 2 | F. Scott. Fitzgerald | USA |
| 3 | Jane Austen | UK |
| 4 | Scott Hanselman | USA |
| 5 | Jason N. Gaylord | USA |
| 6 | Pranav Rastogi | India |
| 7 | Todd Miranda | USA |
| 8 | Christian Wenz | USA |
| Book | |
|---|---|
| id | title |
| 1 | The Catcher in the Rye |
| 2 | Nine Stories |
| 3 | Franny and Zooey |
| 4 | The Great Gatsby |
| 5 | Tender id the Night |
| 6 | Pride and Prejudice |
| 7 | Professional ASP.NET 4.5 in C# and VB |
| BookAuthor | |
|---|---|
| bookId | authorId |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 2 |
| 6 | 3 |
| 7 | 4 |
| 7 | 5 |
| 7 | 6 |
| 7 | 7 |
| 7 | 8 |
Expect lots of joins, for example:
select a.name from author a join bookauthor ba on a.id = ba.authorId join book b on b.id = ba.bookId where b.title like 'Professional ASP.NET%';
Popular Relational Stores:
Graph Stores
A graph store just might be the thing to use if you have highly connected data. (In some sense, these are the real “relational” databases). In a graph database, you have nodes (that can have labels and properties) which are connected with relations (which can themselves have labels and properties). You can connect any node to any other.
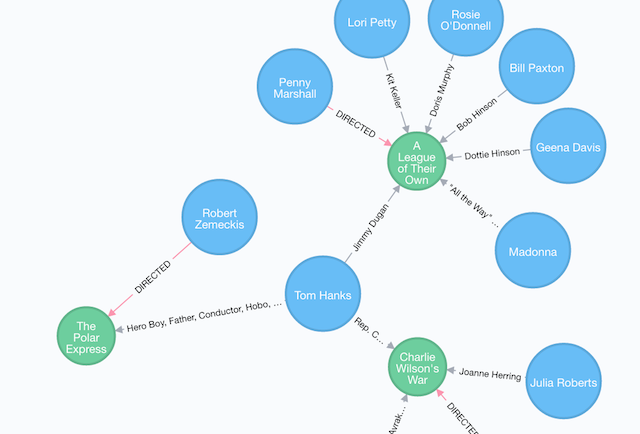
Queries look pretty cool:
match (p)-[a:ACTED_IN]->(:Movie {title: "A League of Their Own"})
return p.name, a.roles
Popular Graph Stores:
Column Stores
These are like relational databases, except they are stored in column groups, not row by row. This makes a difference in terms of what kinds of things you can do efficiently.
Popular Column Stores:
Object Stores
Object databases have been around for a long time. There were books about OODBs back in the 1980s and 1990s, including Kim and Hughes.
Read about them at Wikipedia.
Popular Object Stores:
There are “hybrid” Object-relational databases, which are really relational databases with some object features (generally mostly in the query language...), e.g.,
select b.author.name from book b where b.title = 'The Catcher in the Rye'
Triple Stores
A triple store is optimized for querying triples of the form (subject, predicate, object). Example:
Example
Looks a bit like a subset of a graph database.
Some triple stores can be queried with SPARQL.
Popular Triple Stores: