Software Development
Software Engineering
Software Engineering is concerned with constructing software systems that are:
- Correct, meaning they do exactly what they were intended to do;
- Reliable, meaning they don't crash;
- Robust, meaning they can handle unforeseen or error conditions by logging alerts, cleaning up, and proceeding if possible;
- Predictable, meaning their behavior is never shocking (without good reason);
- Efficient, meaning they do not take too long to run, nor consume more memory or system resources than is reasonable;
- Understandable, meaning that you can look at their source code and tell what they do;
- Reusable, meaning the components from which they are built can function unchanged in other applications;
- Scalable, meaning that new features can be added without excessive restructuring of existing code, and without impacting its run-time performance;
- Maintainable, meaning that bugs can easily be isolated and fixed;
- Appropriate, meaning they do what their users want them to do; and
- Economical, meaning they are produced on-time and under-budget, and are fairly priced.
Software engineering is fundamentally different from other engineering disciplines, argues Jack Reeves in these three excellent essays.
Why Study Software Engineering?
According to Booch, "industrial-strength" software is inherently complex. Steve McConnell calls it a wicked problem. No single person can understand all the subtleties of the design of a large software system. Why?
- Requirements are under- or over-specified, contradictory, too unintelligible, always changing.
- Development process involves too many people, different machines, excessive documentation.
- Software has unlimited flexibility. (A carpenter wouldn't truck in a freshly cut tree and set up a lumber mill on your front lawn to make you a new front door, but many programmers are guilty of writing their own linked-list classes.)
- Discrete systems are hard to characterize (combinatorial explosion in number of states).
To construct complex software we should try to understand the nature of complex systems in general, and see how we deal with them.
Complex Systems
An empirical study of various complex systems (e.g., matter, personal computers, plants and animals, social institutions) reveals:
- Hierarchy: different levels of abstraction are built upon each other.
- Strict separation of concerns between levels.
- Little or no centralization: the high level functionality appears due to a cooperation of agents (so concurrency is fundamental).
- Strong intracomponent linkages (strong cohesion) and weak intercomponent linkages (loose coupling).
- Economy of Expression: similar building blocks in different levels (e.g. cells, transistors, quarks/leptons, people).
- As systems evolve, objects that were once considered complex become the primitive components of the next generation system.
How Humans Deal With Complexity
We manage complexity using abstraction, classification, and hierarchy.
- ABSTRACTION
Recognition of fundamental concepts, structures and behaviors, without concern for implementation details
- CLASSIFICATION
Recognition that every object is an instance of some class
- HIERARCHY
Distillation of essential similarities and differences
- Generalization / Specialization: ("is-a", "kind-of")
- Composition: ("has-a", "integral-part-of")
- Aggregation: ("member-of")
Abstraction
Abstraction is probably the single most important principle in Computer Science. It is the primary way humans deal with complexity, and software systems are humankind's most complex creations. You have to be able to view software components in an abstract way, that is, you have to be able to describe what they do, without relying on describing how they do it.
Examples
- Driving a car: you don't have to know how internal combustion, fuel cells, or batteries work in order to drive.
- Using a microwave: you don't have to know the physics to cook;
- Talking on a phone: you don't have to know how your voice is encoded or how calls are routed to communicate.
- Setting a thermostat: you don't have to know what gets the AC or heater to fire up in order to set a temperature.
- Playing videos: you don't need to know how the content is downloaded, buffered, and turned into frames for viewing.
Primary types of abstraction in programming
- Procedural Abstraction: You call a function with a known interface but you do not know or care how it runs (what code implements it).
- Data Abstraction: You declare objects of a known type, but you do not know or care how those objects are laid out in memory, nor how the operations that manipulate them work.
Examples of Data Abstraction
- Integers can be represented in 1's-complement, 2's-complement, BCD, ...
- There are many different formats for floating point values
- There are different file systems, e.g. NTFS, xfs, e2fs, and zillions more
- Lists can use array or linked structures
Classification
Classification is identifying that a number of objects have similar structure and behavior and giving a name to that class of objects. For example "Dog" is a class and your particular dog is an object of that class.
Hierarchy
Hierarchy is how levels of abstraction are organized.
Is-a (Kind-of) Hierarchy
Shows classes and subclasses. Moving up is called generalization (recognizing that different classes share some similarities), moving down is called specialization (factoring a class into subclasses which are different from each other in some ways).
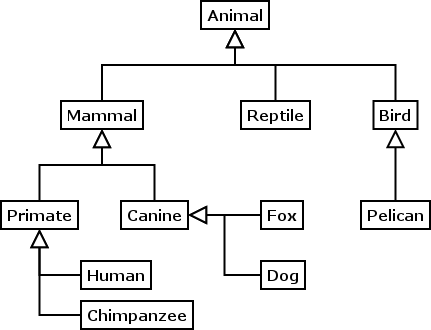
Has-a (Part-of) Hierarchy
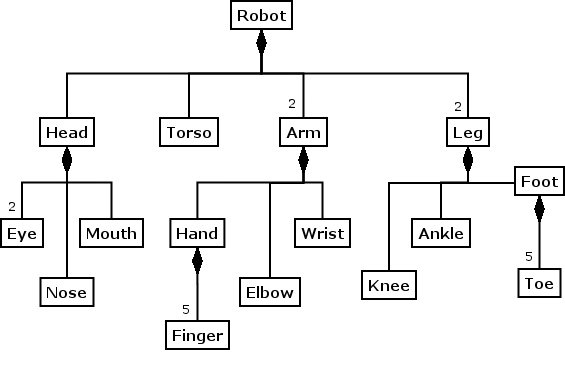
Shows classes in a containment hierarchy. Moving up is called composition (combining parts to form larger objects), moving down is called decomposition (breaking a larger structure down into components). In a composition relationship, contained objects are completely owned by the container: if the containing object goes away, so does the containee.
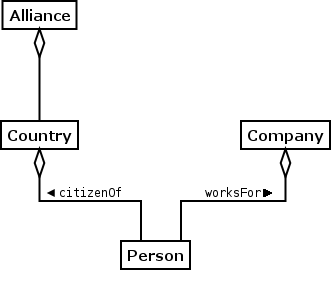
Member-of (Aggregation) Hierarchy
Shows classes related by groups and subgroups. This is very similar to composition except that the members of a group continue to exist even if the group goes away.
Software Development Methodologies
Many software development methodologies, or processes, have been created. Usually they fall into a spectrum from adaptive to plan-driven. Many of the more adaptive are known as agile methods. The most plan-driven method is probably the waterfall model. This is pretty much despised as a way to build software, because it doesn't work. It does work in heavy manufacturing and similar industries, though.
Some methodologies:
- Rational Unified Process (RUP)
- Extreme Programming (XP)
- Scrum
- Agile Unified Process (AUP)
- Open Unified Process (OpenUP)
- DSDM
Boehm and Turner give a great characterization of "home grounds" for adaptive and plan-driven methods (loosely summarized here):
| Adaptive | Plan-driven |
|---|---|
| Goal is to respond quickly to change | Goals include predictability and stability |
| Smaller teams, more senior developers | Larger teams, more juniors |
| Tacit interpersonal knowledge | Explicit documentation |
| User stories | Explicit, formal, detailed, requirements |
| Simple designs | Detailed and extensive designs |
| Culture "thriving on chaos" | Culture "thriving on order" |
Phases, Iterations, and Workflows
Software Development is an incremental and iterative process (waterfall doesn't work for software). You iterate because coding might show part of the design was infeasible, maintenance requires recoding, the customer will change requirements just when the product is about to be shipped, etc.
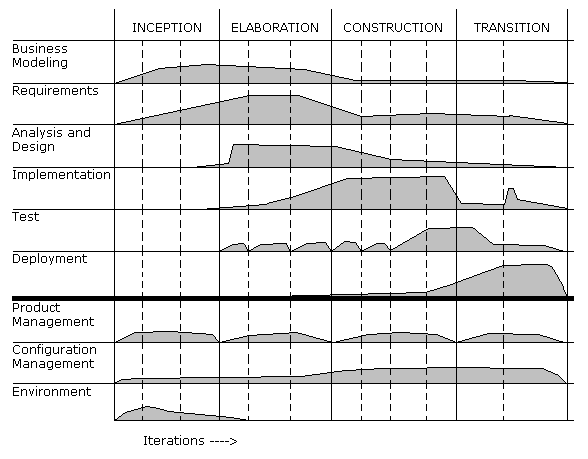
The major elements of a development cycle are phases, iterations and workflows. This diagram shows the four major phases (inception, elaboration, construction and transition). Within each phase you do a number of iterations. An iteration results in the development of a complete, executable subset of the system. The diagram (from the RUP) shows how much effort within a given workflow you put into an iteration.
Current Research
- Physical Distribution
- Concurrency
- Replication
- Security
- Load Balancing
- Fault Tolerance
- Grid Computing
- Data Science (including Analytics)
- Search and Data Mining
- Robotics
Technologies that Help
- Components
- Visual Programming
- Patterns
- Frameworks
- Application Containers
- Aspect Orientation
Producing Efficient Software
An efficient algorithm minimizes cost which is one or more of:
- Time, which is affected by algorithmic issues like the could be number of operations, or physical issues like communication delays between network nodes, between processors, between the CPU and a graphics chip, between the CPU and its cache or memory, etc. (In more technical terms we want to minimize network hops, page faults, context switches, and so on).
- Space, which refers to the amount of memory or disk space required to "hold intermediate results".
- Coding time, which goes way up if you're not experienced or are unaware of existing libraries and solutions that you can adapt.
- Verification and debugging time, which goes up when the code is hard to read or understand)
- System integration effort, which is too high when there are artificially too many little pieces of code written by too many different people.
Caskey's Law of Software Development
"A good system must first and foremost be easy to modify and extend." —Caskey Dickson