Hashtables
Motivation
Can we do better than logarithmic performance for sets and dictionaries? Can we...possibly...get to constant time?
We can’t do better than logarithmic if we have to compare values against each other. So, in much the same way we “improved” upon the comparison-based sorts by using distribution (bucket / radix) techniques, we can apply a similar idea to search.
The Basic Idea
You define a hash function $h$ that maps your keys into integers in the range $0 ... N-1$. Each key $k$ then goes into bucket $h(k)$.
Example
Let:
- the key type be
String, - $N = 11$, and
- $h(s) = s\mathrm{[0]} \times s\mathrm{[s.length-1]} \bmod 11$
Then if we put in the values {"hashtables", "will", "usually", "execute", "constant", "time"} the slots get computed like this:
h("hashtables") = ('h' * 's') % 11 = 3
h("will") = ('w' * 'l') % 11 = 4
h("usually") = ('u' * 'y') % 11 = 0
h("execute") = ('e' * 'e') % 11 = 4
h("constant") = ('c' * 't') % 11 = 0
h("time") = ('t' * 'e') % 11 = 1
Note in general you get collisions, which need to be resolved. There are many collision resolution strategies; one of the most common is just to chain the elements in a linked list. If we did that our hashtable would look like this:
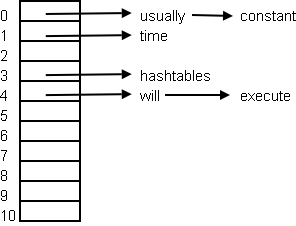
Criteria for Good Hashtables
If every element hashed to the same slot, then the hashtable would have linear, not constant, performance. So you need to be smart about:
- Choosing a hash function that gives a good distribution (clustering is bad), but also doesn’t take to long to compute
- Choosing a good capacity (not so large you waste memory nor too small that lookup requires a ton of linked list navigation)
- Choosing a good strategy for when you should expand or contract the hashtable size
- Choosing a decent collision resolution strategy
Choosing a Good Hash Function
This is hard in general, and is application dependent. It’s also beyond the scope of these notes. Start with Wikipedia’s Hashtable article and then do your own research.
Table Resizing
Hashtables perform pretty well until they get about 70% full (i.e. a load factor of 0.7). After this you often want to make the table bigger and rehash everything. This takes time, but is worth it when you do more lookups then inserts.
Ditto for deletions. You might want to shrink the hashtable if it has been taking up too much memory.
Collision Resolution
Many strategies are known
- Chaining
- Open Addressing
- Linear Probing
- Quadratic Probing
- Double Hashing
- Cuckoo Hashing
- Robin Hood Hashing
- Coalesced Hashing
- Perfect Hashing
- Probabilistic Hashing
Find details in Wikipedia’s Hashtable article.
Hashtables vs. Other Dictionary Implementations
Hashtables are good because:
- The keys do not have to come from an ordered type
- In practice we can set things up for constant-time performance
Hashtables aren’t always the best choice because:
- The difference between best and worst case complexities make it subject to algorithmic complexity attacks
- You can’t easily read things out in a sorted order, assuming there was such an order
- In contexts where bitsets rule, hashtables are overkill
- You can’t really get a good hash function that be can computed quickly, so they’re usually bad for small dictionaries
- Resizing is very, very expensive, and probably can’t be used in most real-time systems.
More
There’s so much more in Wikipedia’s Hashtable article.
Summary
We’ve covered:
- Motivation for hashtables
- The idea of the hash function
- Criteria for good hashtable performance
- Hashtables vs. other representations