How to Write a Compiler
About This Guide
Want to write a compiler? These notes go over the way that I personally like to write compilers, so you’ll find this tutorial very opinionated.
We’ll be discussing compiler writing by using a specific example for a language called Carlos. You can use the guide as a code along and create your own Carlos compiler, or you can use the guide to create a compiler for your own language, substituting your language name, syntax, features, etc. for anything in this guide that is Carlos-specific.
This guide assumes you have a bit of programming experience, so before you start, make sure you have:
- The latest versions of node, npm, and git installed
- Command line skills
- GitHub experience
It doesn’t matter whether you are designing a language yourself or implementing a complier for an existing language, you need to deeply understand the language. You must, in either case:
- Understand the intended audience
- Understand the kinds of applications the language is best suited for
- Understand the syntax and semantics deeply
- Write a bunch of example programs
If you are designing the language yourself:
- Use an interactive language design tool to help you craft a syntax
- Write a language specification
For this guide, I’ve already created and wrote a specification for Carlos. To best follow along:
- Read the Carlos language specification
- Try your hand at writing example Carlos programs
- Seriously, read the Carlos language specification
If you are building your own language, customize the steps above accordingly.
Language design is iterativeYou’re unlikely to get the design perfectly right at first. Writing the compiler will expose some design flaws or implementation difficulties that you did not foresee. Don’t feel bad about changing the language design (perhaps several times) as you implement.
GitHub Setup
GitHub is a great place to do your work! To get started:
- At github.com, perform the New Repository action
- Enter a project name and description
- Leave the Public radio button selected
- Make sure to check Add a README file
- Add the .gitignore file with the Node template
- Choose the MIT license
- Click the Create repository button
The Project Skeleton
Go to your terminal app and:
- Change to the directory where you keep your projects
git clonethe project you just created- Change to the project root folder
You should have these files:
.
├── .gitignore
├── LICENSE
└── README.md
Let’s write some code:
- Open the project in your favorite editor
- Make sure your editor has the Prettier extension installed and that it is set to format on save
- Create a docs folder and add a logo to it
- In the README.md add a link to your logo, write the language name, and add text about your language (who it’s for, some of its features, some example programs, and any other notes about the project that might be helpful to readers)
- Optionally, customize Prettier settings in a new .prettierrc.json file
- Create an examples folder and add a bunch of example programs
The project tree should now look something like this:
.
├── .gitignore
├── LICENSE
├── README.md
├── .prettierrc.json
├── docs
│ └── carlos-logo.png
└── examples
├── hello.carlos
├── fizzbuzz.carlos
└── gcd.carlos
We’ve done a lot, so:
git add .git commit -m 'Basic project setup'git push
We’ll be using Node.js, so let’s perform the standard Node project setup with npm init and bring in third-party modules. I like the Ohm language processing library, c8 for test coverage, and a pretty little module for visualizing program representations called graph-stringify:
npm init -ynpm install ohm-js graph-stringifynpm install c8 --save-dev
This creates package.json, package-lock.json, and node_modules. Next, you will need to make some hand-edits to package.json:
- Update the
testcommand to:c8 node --test test/**/*.js - Add to the top-level the property
"type": "module" - Make any other changes or additions you like, such as adding to the author and description properties.
Here’s what my package.json looks like; yours will be a bit different:
{
"name": "carlos",
"version": "2.0.0",
"description": "A compiler for the Carlos programming language",
"main": "carlos.js",
"type": "module",
"directories": {
"doc": "docs",
"example": "examples",
"test": "test"
},
"scripts": {
"test": "c8 node --test test/**/*.test.js"
},
"repository": {
"type": "git",
"url": "git+https://github.com/rtoal/carlos-lang.git"
},
"keywords": [],
"author": "rtoal",
"license": "MIT",
"bugs": {
"url": "https://github.com/rtoal/carlos-lang/issues"
},
"homepage": "https://github.com/rtoal/carlos-lang#readme",
"dependencies": {
"graph-stringify": "^1.1.0",
"ohm-js": "^17.1.0"
},
"devDependencies": {
"@vitest/coverage-v8": "^3.1.1",
"c8": "^10.1.3"
}
}
Now let’s stub out all the source and test files. I like to use this architecture to start:
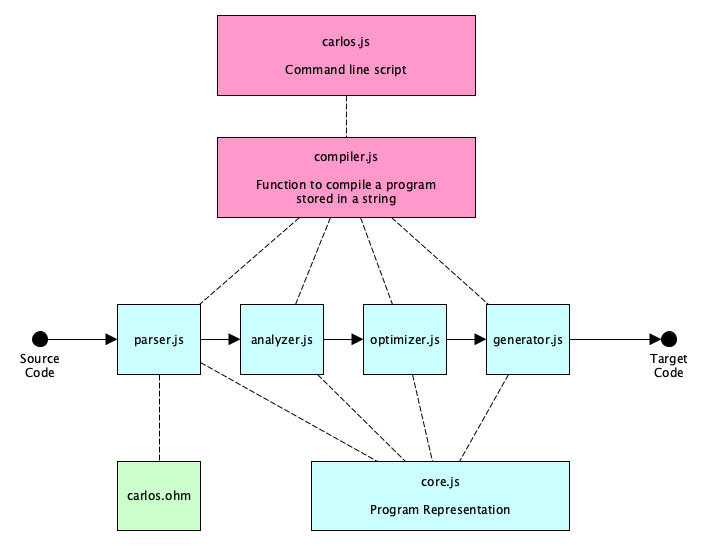
Perform the set up now:
- Create project files to match the structure below. You can do this on the command line (with
mkdirandtouchcommands 💪) or use your IDE’s buttons. (We’re not showing the node_modules folder in this file tree for obvious reasons.). ├── .gitignore ├── LICENSE ├── README.md ├── package.json -- created with npm init ├── package-lock.json -- also auto-generated, just leave it alone ├── .prettierrc.json -- bc we all have our own preferences 🤪 ├── docs │ ├── carlos-logo.png │ └── ... -- eventually will hold a companion website ├── examples │ └── ... -- good to have examples so users can see them ├── src │ ├── carlos.ohm -- nice to have the grammar in its own file │ ├── carlos.js -- to run from command line │ ├── compiler.js -- to allow the compiler to be used as a library │ ├── core.js -- defines the internal program representation │ ├── parser.js -- simple parser that uses Ohm │ ├── analyzer.js -- builds the program rep and checks it │ ├── optimizer.js -- makes it faster, right? │ └── generator.js -- backend: translates to the target language └── test ├── compiler.test.js ├── parser.test.js ├── analyzer.test.js ├── optimizer.test.js └── generator.test.js - Make sure you’ve set up testing properly. Stub out test/compiler.test.js like so:
import { describe, it } from "node:test" import assert from "node:assert/strict" describe("The project setup", () => { it("can at least run tests", () => { assert.deepEqual(1, 1) }) }) - Run
npm test(until all tests pass) - git add, commit, and push
Stub Out The Main Files
Each of the files in the middle row of the diagram will export a single file handling a particular compilation phase. The parser will process the source code to a match object; the analyzer will process the match to a program representation; the optimizer will improve the program representation (hopefully making it faster and smaller); and the generator will process the representation to target code.
Stub parser.js as follows:
export default function parse(sourceCode) { throw new Error("Not implemented") }Stub analyzer.js as follows:
export default function analyze(match) { throw new Error("Not implemented") }Stub optimizer.js as follows:
export default function optimize(program) { throw new Error("Not implemented") }Stub generator.js as follows:
export default function generate(program) { throw new Error("Not implemented") }
We’re going to build the compiler so that we can see the output of the compiler at each step. This will help us while we are developing it, and it might even be convenient for our users. So when running from the command line, we’d like to have these options:
node src/carlos.js examples/gcd.carlos parsed- Prints the result of parsing the program.
node src/carlos.js examples/gcd.carlos analyzed- Prints the result of analyzing the program, namely the internal representation, in as decent a form as we can make it.
node src/carlos.js examples/gcd.carlos optimized- Prints the result of optimizing the program.
node src/carlos.js examples/gcd.carlos js- Prints the result of generating the program, namely the target program.
Let’s separate the user interface of the command line app from a function that runs the compiler programatically. This not only demonstrates the good engineering practice known as Separation of Concerns, but also makes the compiler easier to test.
The command line script will do some checking of the command line arguments and take care of reporting. It will ensure that different outputs are rendered nicely, and that error messages appear in red.
Here’s the command line script:
#! /usr/bin/env node
import * as fs from "node:fs/promises"
import stringify from "graph-stringify"
import compile from "./compiler.js"
const help = `Carlos compiler
Syntax: carlos <filename> <outputType>
Prints to stdout according to <outputType>, which must be one of:
parsed a message that the program was matched ok by the grammar
analyzed the statically analyzed representation
optimized the optimized semantically analyzed representation
js the translation to JavaScript
`
async function compileFromFile(filename, outputType) {
try {
const buffer = await fs.readFile(filename)
const compiled = compile(buffer.toString(), outputType)
console.log(stringify(compiled, "kind") || compiled)
} catch (e) {
console.error(`\u001b[31m${e}\u001b[39m`)
process.exitCode = 1
}
}
if (process.argv.length !== 4) {
console.log(help)
} else {
compileFromFile(process.argv[2], process.argv[3])
}
The compiler.js file does the actual compiling:
import parse from "./parser.js"
import analyze from "./analyzer.js"
import optimize from "./optimizer.js"
import generate from "./generator.js"
export default function compile(source, outputType) {
if (!["parsed", "analyzed", "optimized", "js"].includes(outputType)) {
throw new Error("Unknown output type")
}
const match = parse(source)
if (outputType === "parsed") return "Syntax is ok"
const analyzed = analyze(match)
if (outputType === "analyzed") return analyzed
const optimized = optimize(analyzed)
if (outputType === "optimized") return optimized
return generate(optimized)
}
Create these files:
- Create src/carlos.js (or, the equivalent for your own language).
- Create src/compiler.js.
- git add, commit, and push.
Begin the Parser, Tests First
We want to write tests FIRST! Compilers need lots and lots of tests. The first part of the compiler we will work on is the parser portion, which will attempt to match a source code file against that grammar and return a match result, or throw an error if a match was not possible—that is, the parser found lexical or syntax errors in the soruce program.
We have to test both (1) that Carlos programs we expect to be syntactically correct are indeed correct, and (2) that Carlos programs with syntax errors should have those errors detected at the point we expect them to be detected.Here’s how the parser test should look:
import { describe, it } from "node:test"
import assert from "node:assert/strict"
import parse from "../src/parser.js"
// Programs expected to be syntactically correct
const syntaxChecks = [
["simplest syntactically correct program", "break;"],
["multiple statements", "print(1);\nbreak;\nx=5; return; return;"],
["variable declarations", "let e=99*1;\nconst z=false;"],
["type declarations", "struct S {x:T1 y:T2 z:bool}"],
["function with no params, no return type", "function f() {}"],
["function with one param", "function f(x: int) {}"],
["function with two params", "function f(x: int, y: boolean) {}"],
["function with no params + return type", "function f(): int {}"],
["function types in params", "function f(g: (int)->boolean) {}"],
["function types returned", "function f(): (int)->(int)->void {}"],
["array type for param", "function f(x: [[[boolean]]]) {}"],
["array type returned", "function f(): [[int]] {}"],
["optional types", "function f(c: int?): float {}"],
["assignments", "a--; c++; abc=9*3; a=1;"],
["complex var assignment", "c(5)[2] = 100;c.p.r=1;c.q(8)[2](1,1).z=1;"],
["complex var bumps", "c(5)[2]++;c.p.r++;c.q(8)[2](1,1).z--;"],
["call in statement", "let x = 1;\nf(100);\nprint(1);"],
["call in exp", "print(5 * f(x, y, 2 * y));"],
["short if", "if true { print(1); }"],
["longer if", "if true { print(1); } else { print(1); }"],
["even longer if", "if true { print(1); } else if false { print(1);}"],
["while with empty block", "while true {}"],
["while with one statement block", "while true { let x = 1; }"],
["repeat with long block", "repeat 2 { print(1);\nprint(2);print(3); }"],
["if inside loop", "repeat 3 { if true { print(1); } }"],
["for closed range", "for i in 2...9*1 {}"],
["for half-open range", "for i in 2..<9*1 {}"],
["for collection-as-id", "for i in things {}"],
["for collection-as-lit", "for i in [3,5,8] {}"],
["conditional", "return x?y:z?y:p;"],
["??", "return a ?? b ?? c ?? d;"],
["ors can be chained", "print(1 || 2 || 3 || 4 || 5);"],
["ands can be chained", "print(1 && 2 && 3 && 4 && 5);"],
["bitwise ops", "return (1|2|3) + (4^5^6) + (7&8&9);"],
["relational operators", "print(1<2||1<=2||1==2||1!=2||1>=2||1>2);"],
["shifts", "return 3 << 5 >> 8 << 13 >> 21;"],
["arithmetic", "return 2 * x + 3 / 5 - -1 % 7 ** 3 ** 3;"],
["length", "return #c; return #[1,2,3];"],
["boolean literals", "let x = false || true;"],
["all numeric literal forms", "print(8 * 89.123 * 1.3E5 * 1.3E+5 * 1.3E-5);"],
["empty array literal", "print([int]());"],
["nonempty array literal", "print([1, 2, 3]);"],
["some operator", "return some dog;"],
["no operator", "return no dog;"],
["random operator", "return random [1, 2, 3];"],
["parentheses", "print(83 * ((((((((-(13 / 21))))))))) + 1 - 0);"],
["variables in expression", "return r.p(3,1)[9]?.x?.y.z.p()(5)[1];"],
["more variables", "return c(3).p?.oh(9)[2][2].nope(1)[3](2);"],
["indexing array literals", "print([1,2,3][1]);"],
["member expression on string literal", `print("hello".append("there"));`],
["non-Latin letters in identifiers", "let コンパイラ = 100;"],
["a simple string literal", 'print("hello😉😬💀🙅🏽♀️—`");'],
["string literal with escapes", 'return "a\\n\\tbc\\\\de\\"fg";'],
["u-escape", 'print("\\u{a}\\u{2c}\\u{1e5}\\u{ae89}\\u{1f4a9}\\u{10ffe8}");'],
["end of program inside comment", "print(0); // yay"],
["comments with no text", "print(1);//\nprint(0);//"],
]
// Programs with syntax errors that the parser will detect
const syntaxErrors = [
["non-letter in an identifier", "let ab😭c = 2;", /Line 1, col 7:/],
["malformed number", "let x= 2.;", /Line 1, col 10:/],
["a float with an E but no exponent", "let x = 5E * 11;", /Line 1, col 10:/],
["a missing right operand", "print(5 -);", /Line 1, col 10:/],
["a non-operator", "print(7 * ((2 _ 3));", /Line 1, col 15:/],
["an expression starting with a )", "return );", /Line 1, col 8:/],
["a statement starting with expression", "x * 5;", /Line 1, col 3:/],
["an illegal statement on line 2", "print(5);\nx * 5;", /Line 2, col 3:/],
["a statement starting with a )", "print(5);\n)", /Line 2, col 1:/],
["an expression starting with a *", "let x = * 71;", /Line 1, col 9:/],
["negation before exponentiation", "print(-2**2);", /Line 1, col 10:/],
["mixing ands and ors", "print(1 && 2 || 3);", /Line 1, col 15:/],
["mixing ors and ands", "print(1 || 2 && 3);", /Line 1, col 15:/],
["associating relational operators", "print(1 < 2 < 3);", /Line 1, col 13:/],
["while without braces", "while true\nprint(1);", /Line 2, col 1/],
["if without braces", "if x < 3\nprint(1);", /Line 2, col 1/],
["while as identifier", "let for = 3;", /Line 1, col 5/],
["if as identifier", "let if = 8;", /Line 1, col 5/],
["unbalanced brackets", "function f(): int[;", /Line 1, col 18/],
["empty array without type", "print([]);", /Line 1, col 8/],
["random used like a function", "print(random(1,2));", /Line 1, col 15/],
["bad array literal", "print([1,2,]);", /Line 1, col 12/],
["empty subscript", "print(a[]);", /Line 1, col 9/],
["true is not assignable", "true = 1;", /Line 1, col 5/],
["false is not assignable", "false = 1;", /Line 1, col 6/],
["numbers cannot be subscripted", "print(500[x]);", /Line 1, col 10/],
["numbers cannot be called", "print(500(x));", /Line 1, col 10/],
["numbers cannot be dereferenced", "print(500 .x);", /Line 1, col 11/],
["no-paren function type", "function f(g:int->int) {}", /Line 1, col 17/],
["string lit with unknown escape", 'print("ab\\zcdef");', /col 11/],
["string lit with newline", 'print("ab\\zcdef");', /col 11/],
["string lit with quote", 'print("ab\\zcdef");', /col 11/],
["string lit with code point too long", 'print("\\u{1111111}");', /col 17/],
]
describe("The parser", () => {
for (const [scenario, source] of syntaxChecks) {
it(`matches ${scenario}`, () => {
assert(parse(source).succeeded())
})
}
for (const [scenario, source, errorMessagePattern] of syntaxErrors) {
it(`throws on ${scenario}`, () => {
assert.throws(() => parse(source), errorMessagePattern)
})
}
})
Let’s get to work:
- Fill in your parser.test.js file, using mine as a guide.
- From the project root folder, run
npm test
You will see a big scary output that somewhere inside of it all says The requested module '../src/parser.js' does not provide an export named 'default', which just means we haven't actually written the parser yet. This is normal in Test-Driven Development. One nice benefit of TDD is that we have, in writing the test file, spent a lot of time writing Carlos code that should and should not compile, so we are deepening our understanding of the language we are writing a compiler for. And that is good.
Write the Parser
Writing hand-crafted syntax analyzers (parsers) is good, but getting Ohm to generate the parser is better! (I told you these notes were opinionated.) When designing your own language, use the Ohm Editor.
Use the Ohm Editor for Syntax DesignTHE OHM EDITOR IS AMAZING! You can write a few tests in the Ohm editor and the tests run as you type! Such immediate feedback is crucial in the creative design process.
Here’s the Carlos grammar:
Carlos {
Program = Statement+
Statement = VarDecl
| TypeDecl
| FunDecl
| Exp9 ("++" | "--") ";" --bump
| Exp9 "=" Exp ";" --assign
| Exp9_call ";" --call
| break ";" --break
| return Exp ";" --return
| return ";" --shortreturn
| IfStmt
| LoopStmt
VarDecl = (let | const) id "=" Exp ";"
TypeDecl = struct id "{" Field* "}"
Field = id ":" Type
FunDecl = function id Params (":" Type)? Block
Params = "(" ListOf<Param, ","> ")"
Param = id ":" Type
Type = Type "?" --optional
| "[" Type "]" --array
| "(" ListOf<Type, ","> ")" "->" Type --function
| id --id
IfStmt = if Exp Block else Block --long
| if Exp Block else IfStmt --elsif
| if Exp Block --short
LoopStmt = while Exp Block --while
| repeat Exp Block --repeat
| for id in Exp ("..." | "..<") Exp Block --range
| for id in Exp Block --collection
Block = "{" Statement* "}"
Exp = Exp1 "?" Exp1 ":" Exp --conditional
| Exp1
Exp1 = Exp1 "??" Exp2 --unwrapelse
| Exp2
Exp2 = Exp3 ("||" Exp3)+ --or
| Exp3 ("&&" Exp3)+ --and
| Exp3
Exp3 = Exp4 ("|" Exp4)+ --bitor
| Exp4 ("^" Exp4)+ --bitxor
| Exp4 ("&" Exp4)+ --bitand
| Exp4
Exp4 = Exp5 ("<="|"<"|"=="|"!="|">="|">") Exp5 --compare
| Exp5
Exp5 = Exp5 ("<<" | ">>") Exp6 --shift
| Exp6
Exp6 = Exp6 ("+" | "-") Exp7 --add
| Exp7
Exp7 = Exp7 ("*"| "/" | "%") Exp8 --multiply
| Exp8
Exp8 = Exp9 "**" Exp8 --power
| Exp9
| ("#" | "-" | "!" | some | random) Exp9 --unary
Exp9 = true ~mut
| false ~mut
| floatlit ~mut
| intlit ~mut
| no Type ~mut --emptyopt
| Exp9 "(" ListOf<Exp, ","> ")" ~mut --call
| Exp9 "[" Exp "]" --subscript
| Exp9 ("." | "?.") id --member
| stringlit ~mut
| id --id
| Type_array "(" ")" ~mut --emptyarray
| "[" NonemptyListOf<Exp, ","> "]" ~mut --arrayexp
| "(" Exp ")" ~mut --parens
intlit = digit+
floatlit = digit+ "." digit+ (("E" | "e") ("+" | "-")? digit+)?
stringlit = "\"" char* "\""
char = ~control ~"\\" ~"\"" any
| "\\" ("n" | "t" | "\"" | "\\") --escape
| "\\u{" hex hex? hex? hex? hex? hex? "}" --codepoint
control = "\x00".."\x1f" | "\x80".."\x9f"
hex = hexDigit
mut = ~"==" "=" | "++" | "--"
let = "let" ~alnum
const = "const" ~alnum
struct = "struct" ~alnum
function = "function" ~alnum
if = "if" ~alnum
else = "else" ~alnum
while = "while" ~alnum
repeat = "repeat" ~alnum
for = "for" ~alnum
in = "in" ~alnum
random = "random" ~alnum
break = "break" ~alnum
return = "return" ~alnum
some = "some" ~alnum
no = "no" ~alnum
true = "true" ~alnum
false = "false" ~alnum
keyword = let | const | struct | function | if | else | while | repeat
| for | in | break | return | some | no | random | true | false
id = ~keyword letter alnum*
space += "//" (~"\n" any)* --comment
}
The parser itself is surprisingly small! Ohm does a lot of work for you. The parser module needs to first have Ohm create a grammar object from the grammar in the carlos.ohm file. Then the parse function itself invokes the grammar’s match operation to do all the parsing for us:
// The parse() function uses Ohm to produce a match object for a given
// source code program, using the grammar in the file carlos.ohm.
import * as fs from "node:fs"
import * as ohm from "ohm-js"
const grammar = ohm.grammar(fs.readFileSync("src/carlos.ohm"))
// Returns the Ohm match if successful, otherwise throws an error
export default function parse(sourceCode) {
const match = grammar.match(sourceCode)
if (!match.succeeded()) throw new Error(match.message)
return match
}
Time to build the parser:
- Fill in src/carlos.ohm (or the equivalent if you are working on your own).
- Fill in src/parser.js.
- Now run those tests (
npm test), fixing issues until all the tests pass. You should see something like:$ npm test ▶ The parser ✔ matches simplest syntactically correct program\u001b[39m (1.888833ms) ✔ matches multiple statements (2.223667ms) ✔ matches variable declarations (0.807167ms) ✔ matches type declarations (0.748459ms) . . . ✔ throws on string lit with newline (0.959667ms) ✔ throws on string lit with quote (0.719292ms) ✔ throws on string lit with code point too long (0.707208ms) ✔ The parser (93.502083ms) ℹ tests 89 ℹ suites 1 ℹ pass 89 ℹ fail 0 ℹ cancelled 0 ℹ skipped 0 ℹ todo 0 ℹ duration_ms 104.536791 -----------|---------|----------|---------|---------|------------------- File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s -----------|---------|----------|---------|---------|------------------- All files | 100 | 100 | 100 | 100 | parser.js | 100 | 100 | 100 | 100 | -----------|---------|----------|---------|---------|-------------------
- Enjoy the green text that says all your tests pass and pat yourself on the back for 100% test coverage.
- git add, commit, and push.
- It’s a good time to try a manual test to see if the parser can be fired off from the command line. Run one of the examples from the examples folder (if you haven’t made one, do so now!) as follows:
$ node src/carlos.js examples/gcd.carlos parsed Syntax is ok
Design the Program Representation
The parser checks syntax and creates a match result object containing a parse tree. Parse trees are important but more complex than we need for later stages of compilation. It’s not helpful to carry around parentheses and punctuation, nor do we care about the syntax categories Exp1, Exp2, ..., Exp9. The parser will already resolve precedence and associativity for us, so all we need is to build a lighter program representation, akin to an abstract syntax tree, but with with name resolution and type information.
Let’s try to get an idea for how such a representation will look. Let’s start with a very simple Carlos program, such as:
let x = 3.0; print(x - sqrt(x) ** sin(π));
In Carlos, print, sqrt, and sin are all functions from the standard library, so syntactically, they are calls. However, let’s think ahead a bit. We really won’t be calling these particular functions at run time; instead, these functions are intrinsic meaning our compiler has intimate knowledge about them and will basically treat them as special statements or operators. We can use knowledge about their indented meaning within our compiler. The abstract syntax tree is therefore:
Program
/ \
let print
/ \ |
x 3.0 –
/ \
x **
/ \
sqrt sin
| |
x π
The representation of the program will want to take into account the types of all of the expressions, as well as know that all references to x are, in this case, referring to the same variable. Here’s how we can internally represent this program:

While we’re designing, let’s sketch a representation for a slightly more complex program:
function gcd(x: int, y: int): int {
return y == 0 ? x : gcd(y, x % y);
}
print(gcd(5023427, 920311));
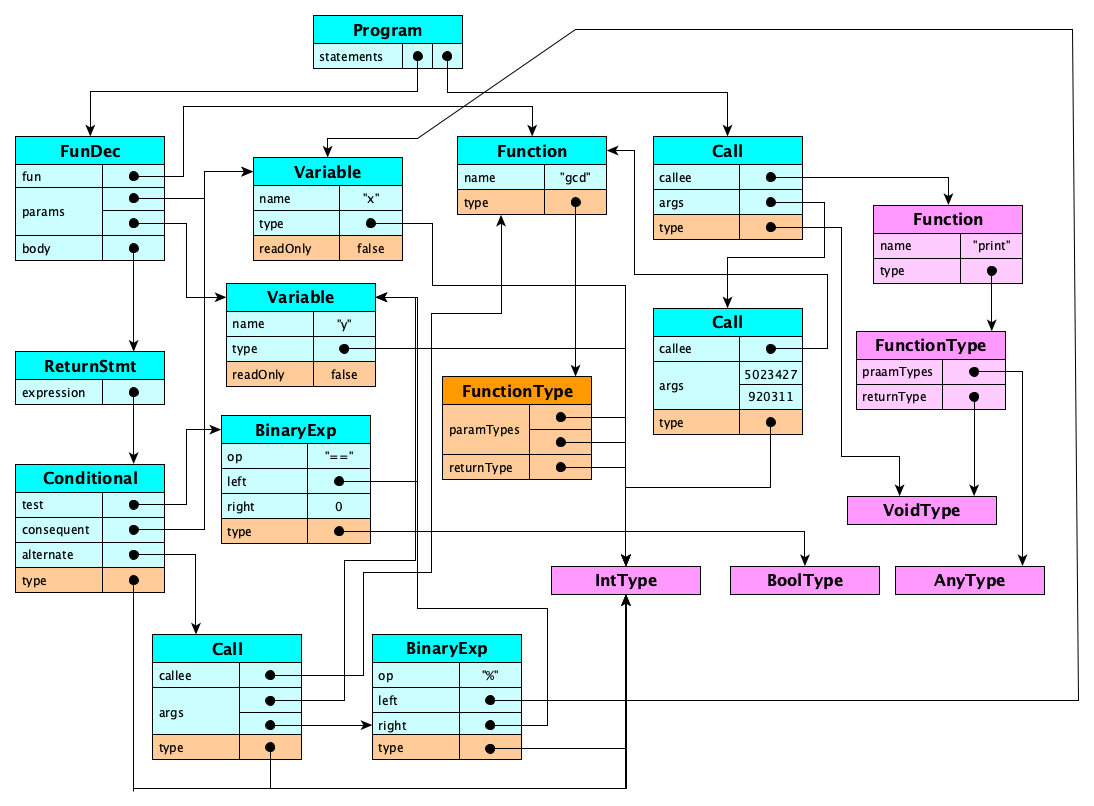
Let’s do one more.
struct Info { id: int label: string? }
while (3 < 2) {
let i = Info(1, some "hello");
print([1, 2, 3]);
}
As programs get larger, drawing out the entire object graph can get unwieldy. This is where the graph-stringify module can be helpful. Here’s how the program representation graph of the above Carlos program looks when stringified:
1 | Program statements=[#2,#7] 2 | TypeDeclaration type=#3 3 | StructType name='Info' fields=[#4,#5] 4 | Field name='id' type='int' 5 | Field name='label' type=#6 6 | OptionalType baseType='string' 7 | WhileStatement test=#8 body=[#9,#14] 8 | BinaryExpression op='<' left=3n right=2n type='boolean' 9 | VariableDeclaration variable=#10 initializer=#11 10 | Variable name='i' mutable=true type=#3 11 | ConstructorCall callee=#3 args=[1n,#12] type=#3 12 | UnaryExpression op='some' operand='"hello"' type=#13 13 | OptionalType baseType='string' 14 | Print args=[#15] 15 | ArrayExpression elements=[1n,2n,3n] type=#16 16 | ArrayType baseType='int'
Now we’re ready to determine all of the node types we will need. To do this, we go through the Ohm grammar and ask ourselves which things are relevant for semantics and which are not. This takes experience, so don’t fret if you don’t get things perfect at first. This is what I selected for Carlos:
| Kind | Properties | Notes |
|---|---|---|
| Program | statements | A program contains a list of statements. |
| VariableDeclaration | variable, initializer | A variable declaration will create a VariableDeclaration node and also a node for the actual variable being declared. |
| Variable | name, mutable, type | Created during variable declarations, parameter declarations, and also when processing for-loops, since the iterator of a for-loop is indeed a variable. |
| TypeDeclaration | type | A type declaration builds a TypeDeclaration node and also a node for the type being declared. Carlos only allows the declaration of new struct types. (Arrays, functions, and optionals are never named; they are built on-the-fly. The predefined types int, float, boolean, string, any (the top type) and void (the bottom type), will be stored as strings.) |
| ArrayType | baseType | An array type. |
| StructType | name, fields | A struct type. |
| OptionalType | baseType | An optional type. |
| Field | name, type | A field in a struct type. |
| FunctionDeclaration | fun | A function declaration builds a FunctionDeclaration node and also a Function node for the actual function being declared. |
| Function | name, params, body, type | The function object built during a function declaration. (If Carlos had anonymous functions (lambda expressions), we would build a node for those too.) The type property of a function object is a FunctionType object. |
| FunctionType | parameterTypes, returnType | The type that functions have, consisting of the parameter types (in order) and the return type. The returnType can be void. There’s no good reason for a parameter to have type void, though it’s not prohibited by the syntax. Such a thing would never compile, though, as any attempt to pass an actual expression to a parameter typed with void would never typecheck. |
| Increment | variable | The statement of the form e++; |
| Decrement | variable | The statement of the form e--; |
| Assignment | target, source | The statement of the form v = e; |
| BreakStatement | break; | |
| ReturnStatement | expression | A return statement with an expression. |
| ShortReturnStatement | A return statement without an expression. | |
| IfStatement | test, consequent, alternate | Standard if-then-else statement. The else part can be a statement list or another if statement. |
| ShortIfStatement | test, consequent | If statement without an else part. |
| WhileStatement | test, body | Statements of the form while test {...}. |
| RepeatStatement | count, body | Statements of the form repeat count {...}. |
| ForRangeStatement | iterator, low, op, high, body | For loop with low and high values of a range; op is either ..< or .... |
| ForStatement | iterator, collection, body | Statement for iterating over the elements of an array. |
| Conditional | test, consequent, alternate | Conditional expression. The only ternary operator in Carlos. |
| BinaryExpression | op, left, right | An expression made from any of the binary operators. The binary operators are those defined in the language specific as well as an operator for the intrinsic hypot function from the standard library. |
| UnaryExpression | op, operand | An expression made from any of the unary operators. The binary operators are -, !, #, some, as well as operators for the intrinsic one-argument functions from the standard library (sqrt, sin, cos, exp, ln, codepoints, and bytes). |
| EmptyOptional | baseType | Represents expressions such as no string. Carlos does not have a free-standing nil value; the type that the optional wraps must be made explicit. |
| SubscriptExpression | array, index | a[e] |
| ArrayExpression | elements | [x, y, z] |
| EmptyArray | baseType | Represents the expression [T]() for some type T. Note that Carlos, unlike many other languages, requires you to specify the type for empty arrays. |
| MemberExpression | object, op, field | The operator is . or ?. |
| FunctionCall | callee, args | fn(x, y) |
| ConstructorCall | callee, args | T(x, y) |
We’ll be storing a type field in all expression nodes, too. While we probably could compute these on the fly during type checking, it’s faster to compute them up front and store them in the object.
For simplicity, we’re going to handle:
- Carlos float literals directly as JavaScript numbers
- Carlos integer literals directly as JavaScript BigInts
- Carlos string literals directly as JavaScript strings
- Carlos identifiers directly as JavaScript symbols
We will represent these nodes as plain old objects. In src/core.js we’ll include functions to build these objects, together withe objects for all of the predefined identifiers that are part of the standard library:
export function program(statements) {
return { kind: "Program", statements }
}
export function variableDeclaration(variable, initializer) {
return { kind: "VariableDeclaration", variable, initializer }
}
export function variable(name, mutable, type) {
return { kind: "Variable", name, mutable, type }
}
export function typeDeclaration(type) {
return { kind: "TypeDeclaration", type }
}
export const booleanType = "boolean"
export const intType = "int"
export const floatType = "float"
export const stringType = "string"
export const voidType = "void"
export const anyType = "any"
export function structType(name, fields) {
return { kind: "StructType", name, fields }
}
export function field(name, type) {
return { kind: "Field", name, type }
}
export function functionDeclaration(fun) {
return { kind: "FunctionDeclaration", fun }
}
export function fun(name, params, body, type) {
return { kind: "Function", name, params, body, type }
}
export function intrinsicFunction(name, type) {
return { kind: "Function", name, type, intrinsic: true }
}
export function arrayType(baseType) {
return { kind: "ArrayType", baseType }
}
export function functionType(paramTypes, returnType) {
return { kind: "FunctionType", paramTypes, returnType }
}
export function optionalType(baseType) {
return { kind: "OptionalType", baseType }
}
export function increment(variable) {
return { kind: "Increment", variable }
}
export function decrement(variable) {
return { kind: "Decrement", variable }
}
export function assignment(target, source) {
return { kind: "Assignment", target, source }
}
export const breakStatement = { kind: "BreakStatement" }
export function returnStatement(expression) {
return { kind: "ReturnStatement", expression }
}
export const shortReturnStatement = { kind: "ShortReturnStatement" }
export function ifStatement(test, consequent, alternate) {
return { kind: "IfStatement", test, consequent, alternate }
}
export function shortIfStatement(test, consequent) {
return { kind: "ShortIfStatement", test, consequent }
}
export function whileStatement(test, body) {
return { kind: "WhileStatement", test, body }
}
export function repeatStatement(count, body) {
return { kind: "RepeatStatement", count, body }
}
export function forRangeStatement(iterator, low, op, high, body) {
return { kind: "ForRangeStatement", iterator, low, op, high, body }
}
export function forStatement(iterator, collection, body) {
return { kind: "ForStatement", iterator, collection, body }
}
export function conditional(test, consequent, alternate, type) {
return { kind: "Conditional", test, consequent, alternate, type }
}
export function binary(op, left, right, type) {
return { kind: "BinaryExpression", op, left, right, type }
}
export function unary(op, operand, type) {
return { kind: "UnaryExpression", op, operand, type }
}
export function emptyOptional(baseType) {
return { kind: "EmptyOptional", baseType, type: optionalType(baseType) }
}
export function subscript(array, index) {
return { kind: "SubscriptExpression", array, index, type: array.type.baseType }
}
export function arrayExpression(elements) {
return { kind: "ArrayExpression", elements, type: arrayType(elements[0].type) }
}
export function emptyArray(type) {
return { kind: "EmptyArray", type }
}
export function memberExpression(object, op, field) {
return { kind: "MemberExpression", object, op, field, type: field.type }
}
export function functionCall(callee, args) {
if (callee.intrinsic) {
if (callee.type.returnType === voidType) {
return { kind: callee.name.replace(/^\p{L}/u, c => c.toUpperCase()), args }
} else if (callee.type.paramTypes.length === 1) {
return unary(callee.name, args[0], callee.type.returnType)
} else {
return binary(callee.name, args[0], args[1], callee.type.returnType)
}
}
return { kind: "FunctionCall", callee, args, type: callee.type.returnType }
}
export function constructorCall(callee, args) {
return { kind: "ConstructorCall", callee, args, type: callee }
}
// These local constants are used to simplify the standard library definitions.
const floatToFloatType = functionType([floatType], floatType)
const floatFloatToFloatType = functionType([floatType, floatType], floatType)
const stringToIntsType = functionType([stringType], arrayType(intType))
const anyToVoidType = functionType([anyType], voidType)
export const standardLibrary = Object.freeze({
int: intType,
float: floatType,
boolean: booleanType,
string: stringType,
void: voidType,
any: anyType,
π: variable("π", false, floatType),
print: intrinsicFunction("print", anyToVoidType),
sqrt: intrinsicFunction("sqrt", floatToFloatType),
sin: intrinsicFunction("sin", floatToFloatType),
cos: intrinsicFunction("cos", floatToFloatType),
exp: intrinsicFunction("exp", floatToFloatType),
ln: intrinsicFunction("ln", floatToFloatType),
hypot: intrinsicFunction("hypot", floatFloatToFloatType),
bytes: intrinsicFunction("bytes", stringToIntsType),
codepoints: intrinsicFunction("codepoints", stringToIntsType),
})
// We want every expression to have a type property. But we aren't creating
// special entities for numbers, strings, and booleans; instead, we are
// just using JavaScript values for those. Fortunately we can monkey patch
// the JS classes for these to give us what we want.
String.prototype.type = stringType
Number.prototype.type = floatType
BigInt.prototype.type = intType
Boolean.prototype.type = booleanType
At this point:
- Fill in src/core.js.
- Run
npm testand make sure nothing broke. - git add, commit, and push.
Build and Analyze the Representation
While it would feel nice to first build a program representation and then analyze it (separation of concerns again!), it’s kind of hard to untangle these phases and they are best done together. After all, you sometimes need to have made certain semantic checks and have performed type inference in order to even build the representation. So in our analyzer module, our analyze function will accept the match from the parser and give back a program representation that it both builds and analyzes.
Understanding Semantic Analysis
As you know, it’s very possible that your program has no syntax errors, but is still semantically meaningless. In a static language like Carlos, the semantic checking phase of the compiler is huge! The following are just some of the rules that must be enforced:
- Identifiers must be in scope before they are used. (Identifiers for the built-in types
int,float,string,boolean,any, andvoid; the built-in constantπ; and all the built in functions are assumed to be pre-declared in a scope that encloses the entire program.) - Identifiers must not be declared more than once in a scope.
- In an assignment, the type of the source must be compatible with, or assignable to, the type of the target.
- Immutable variables may not be assigned.
- In a call (or operator invocation), the number of arguments must match the number of parameters in the callee.
- In a call (or operator invocation), the types of the arguments must be compatible with the types of the corresponding parameters.
- The order, names, and types of bindings in a struct expression must match the fields of the corresponding struct type exactly. By match we mean the order and names are exactly the same, and the types of the struct expression arguments must be compatible with the declared types of the fields.
- The types of the arms of a conditional operator expression must be the same.
- In the expression $x$
??$y$, $x$ must be of an optional type and $y$ must be of the wrapped type. - In an array expression $[e_1, \ldots, e_2]$, all elements $e_i$ must have the same type.
- In a subscript expression
a[e], $a$ must have an array type and $e$ must have integer type. - In a member expression
x.y, $x$ must have a struct type and $y$ must be a field of that type. - Break statements can only appear in loops.
- Return statements can only appear in functions.
- The type of a return expression must match the return type of the function
- A
breakexpression may only appear within afororwhileexpression; however, watch out for function declarations inside of loops—do you see why?
There are many more! The full list of checks are determined by reading the language spec, and they become clear as you write the compiler, and importantly, write all of its tests.
Semantic analysis proceeds by traversing the parse tree returned by the parser and performing actions at each node. These actions include both (1) the construction of program representation nodes AND the validation of the contextual, semantic rules of the language that cannot be captured by the grammar. These contextual rules are enforced with the aid of a context object. The context holds all the local declarations we’ve seen in this scope (for lookup later), whether we are in a loop (so we can check the legality of break statements), the function we are processing, in any, (so we can check the legality of return statements), and a reference to the enclosing context, so we can search for non-local identifier declarations. During analysis we not only perform legality checks, but also create entities from declarations and resolve identifiers to the entities they refer to. That’s a lot, so let’s get back to building the compiler.
Semantic Analysis Tests
We should write tests (1) for programs that we expect to be semantically correct, (2) for programs that are syntactically correct but have semantic errors, and (3) that our program representation is correct:
import { describe, it } from "node:test"
import assert from "node:assert/strict"
import parse from "../src/parser.js"
import analyze from "../src/analyzer.js"
import { program, variableDeclaration, variable, binary, floatType } from "../src/core.js"
// Programs that are semantically correct
const semanticChecks = [
["variable declarations", 'const x = 1; let y = "false";'],
["complex array types", "function f(x: [[[int?]]?]) {}"],
["increment and decrement", "let x = 10; x--; x++;"],
["initialize with empty array", "let a = [int]();"],
["type declaration", "struct S {f: (int)->boolean? g: string}"],
["assign arrays", "let a = [int]();let b=[1];a=b;b=a;"],
["assign to array element", "let a = [1,2,3]; a[1]=100;"],
["initialize with empty optional", "let a = no int;"],
["short return", "function f() { return; }"],
["long return", "function f(): boolean { return true; }"],
["assign optionals", "let a = no int;let b=some 1;a=b;b=a;"],
["return in nested if", "function f() {if true {return;}}"],
["break in nested if", "while false {if true {break;}}"],
["long if", "if true {print(1);} else {print(3);}"],
["elsif", "if true {print(1);} else if true {print(0);} else {print(3);}"],
["for over collection", "for i in [2,3,5] {print(1);}"],
["for in range", "for i in 1..<10 {print(0);}"],
["repeat", "repeat 3 {let a = 1; print(a);}"],
["conditionals with ints", "print(true ? 8 : 5);"],
["conditionals with floats", "print(1<2 ? 8.0 : -5.22);"],
["conditionals with strings", 'print(1<2 ? "x" : "y");'],
["??", "print(some 5 ?? 0);"],
["nested ??", "print(some 5 ?? 8 ?? 0);"],
["||", "print(true||1<2||false||!true);"],
["&&", "print(true&&1<2&&false&&!true);"],
["bit ops", "print((1&2)|(9^3));"],
["relations", 'print(1<=2 && "x">"y" && 3.5<1.2);'],
["ok to == arrays", "print([1]==[5,8]);"],
["ok to != arrays", "print([1]!=[5,8]);"],
["shifts", "print(1<<3<<5<<8>>2>>0);"],
["arithmetic", "let x=1;print(2*3+5**-3/2-5%8);"],
["array length", "print(#[1,2,3]);"],
["optional types", "let x = no int; x = some 100;"],
["random with array literals, ints", "print(random [1,2,3]);"],
["random with array literals, strings", 'print(random ["a", "b"]);'],
["random on array variables", "let a=[true, false];print(random a);"],
["variables", "let x=[[[[1]]]]; print(x[0][0][0][0]+2);"],
["pseudo recursive struct", "struct S {z: S?} let x = S(no S);"],
["nested structs", "struct T{y:int} struct S{z: T} let x=S(T(1)); print(x.z.y);"],
["member exp", "struct S {x: int} let y = S(1);print(y.x);"],
["optional member exp", "struct S {x: int} let y = some S(1);print(y?.x);"],
["subscript exp", "let a=[1,2];print(a[0]);"],
["array of struct", "struct S{} let x=[S(), S()];"],
["struct of arrays and opts", "struct S{x: [int] y: string??}"],
["assigned functions", "function f() {}\nlet g = f;g = f;"],
["call of assigned functions", "function f(x: int) {}\nlet g=f;g(1);"],
["type equivalence of nested arrays", "function f(x: [[int]]) {} print(f([[1],[2]]));"],
[
"call of assigned function in expression",
`function f(x: int, y: boolean): int {}
let g = f;
print(g(1, true));`,
],
[
"pass a function to a function",
`function f(x: int, y: (boolean)->void): int { return 1; }
function g(z: boolean) {}
f(2, g);`,
],
[
"function return types",
`function square(x: int): int { return x * x; }
function compose(): (int)->int { return square; }`,
],
["function assign", "function f() {} let g = f; let h = [g, f]; print(h[0]());"],
[
"covariant return types",
`function f(): any { return 1; }
function g(): float { return 1.0; }
let h = f; h = g;`,
],
[
"contravariant parameter types",
`function f(x: float) { }
function g(x: any) { }
let h = f; h = g;`,
],
["struct parameters", "struct S {} function f(x: S) {}"],
["array parameters", "function f(x: [int?]) {}"],
["optional parameters", "function f(x: [int], y: string?) {}"],
["empty optional types", "print(no [int]); print(no string);"],
["types in function type", "function f(g: (int?, float)->string) {}"],
["voids in fn type", "function f(g: (void)->void) {}"],
["outer variable", "let x=1; while(false) {print(x);}"],
["built-in constants", "print(25.0 * π);"],
["built-in sqrt", "print(sin(25.0));"],
["built-in sin", "print(sin(π));"],
["built-in cos", "print(cos(93.999));"],
["built-in hypot", "print(hypot(-4.0, 3.00001));"],
]
// Programs that are syntactically correct but have semantic errors
const semanticErrors = [
["non-distinct fields", "struct S {x: boolean x: int}", /Fields must be distinct/],
["non-int increment", "let x=false;x++;", /an integer/],
["non-int decrement", 'let x=some[""];x++;', /an integer/],
["undeclared id", "print(x);", /Identifier x not declared/],
["redeclared id", "let x = 1;let x = 1;", /Identifier x already declared/],
["assign to const", "const x = 1;x = 2;", /Cannot assign to immutable/],
[
"assign to function",
"function f() {} function g() {} f = g;",
/Cannot assign to immutable/,
],
["assign to struct", "struct S{} S = 2;", /Cannot assign to immutable/],
[
"assign to const array element",
"const a = [1];a[0] = 2;",
/Cannot assign to immutable/,
],
[
"assign to const optional",
"const x = no int;x = some 1;",
/Cannot assign to immutable/,
],
[
"assign to const field",
"struct S {x: int} const s = S(1);s.x = 2;",
/Cannot assign to immutable/,
],
["assign bad type", "let x=1;x=true;", /Cannot assign a boolean to a int/],
["assign bad array type", "let x=1;x=[true];", /Cannot assign a \[boolean\] to a int/],
["assign bad optional type", "let x=1;x=some 2;", /Cannot assign a int\? to a int/],
["break outside loop", "break;", /Break can only appear in a loop/],
[
"break inside function",
"while true {function f() {break;}}",
/Break can only appear in a loop/,
],
["return outside function", "return;", /Return can only appear in a function/],
[
"return value from void function",
"function f() {return 1;}",
/Cannot return a value/,
],
["return nothing from non-void", "function f(): int {return;}", /should be returned/],
["return type mismatch", "function f(): int {return false;}", /boolean to a int/],
["non-boolean short if test", "if 1 {}", /Expected a boolean/],
["non-boolean if test", "if 1 {} else {}", /Expected a boolean/],
["non-boolean while test", "while 1 {}", /Expected a boolean/],
["non-integer repeat", 'repeat "1" {}', /Expected an integer/],
["non-integer low range", "for i in true...2 {}", /Expected an integer/],
["non-integer high range", "for i in 1..<no int {}", /Expected an integer/],
["non-array in for", "for i in 100 {}", /Expected an array/],
["non-boolean conditional test", "print(1?2:3);", /Expected a boolean/],
["diff types in conditional arms", "print(true?1:true);", /not have the same type/],
["unwrap non-optional", "print(1??2);", /Expected an optional/],
["bad types for ||", "print(false||1);", /Expected a boolean/],
["bad types for &&", "print(false&&1);", /Expected a boolean/],
["bad types for ==", "print(false==1);", /Operands do not have the same type/],
["bad types for !=", "print(false==1);", /Operands do not have the same type/],
["bad types for +", "print(false+1);", /Expected a number or string/],
["bad types for -", "print(false-1);", /Expected a number/],
["bad types for *", "print(false*1);", /Expected a number/],
["bad types for /", "print(false/1);", /Expected a number/],
["bad types for **", "print(false**1);", /Expected a number/],
["bad types for <", "print(false<1);", /Expected a number or string/],
["bad types for <=", "print(false<=1);", /Expected a number or string/],
["bad types for >", "print(false>1);", /Expected a number or string/],
["bad types for >=", "print(false>=1);", /Expected a number or string/],
["bad types for ==", "print(2==2.0);", /not have the same type/],
["bad types for !=", "print(false!=1);", /not have the same type/],
["bad types for negation", "print(-true);", /Expected a number/],
["bad types for length", "print(#false);", /Expected an array/],
["bad types for not", 'print(!"hello");', /Expected a boolean/],
["bad types for random", "print(random 3);", /Expected an array/],
["non-integer index", "let a=[1];print(a[false]);", /Expected an integer/],
["no such field", "struct S{} let x=S(); print(x.y);", /No such field/],
["diff type array elements", "print([3,3.0]);", /Not all elements have the same type/],
["shadowing", "let x = 1;\nwhile true {let x = 1;}", /Identifier x already declared/],
["call of uncallable", "let x = 1;\nprint(x());", /Call of non-function/],
[
"Too many args",
"function f(x: int) {}\nf(1,2);",
/1 argument\(s\) required but 2 passed/,
],
[
"Too few args",
"function f(x: int) {}\nf();",
/1 argument\(s\) required but 0 passed/,
],
[
"Parameter type mismatch",
"function f(x: int) {}\nf(false);",
/Cannot assign a boolean to a int/,
],
[
"function type mismatch",
`function f(x: int, y: (boolean)->void): int { return 1; }
function g(z: boolean): int { return 5; }
f(2, g);`,
/Cannot assign a \(boolean\)->int to a \(boolean\)->void/,
],
["bad param type in fn assign", "function f(x: int) {} function g(y: float) {} f = g;"],
[
"bad return type in fn assign",
`function f(x: int): int {return 1;}
function g(y: int): string {return "uh-oh";}
let h = f; h = g;`,
/Cannot assign a \(int\)->string to a \(int\)->int/,
],
["type error call to sin()", "print(sin(true));", /Cannot assign a boolean to a float/],
[
"type error call to sqrt()",
"print(sqrt(true));",
/Cannot assign a boolean to a float/,
],
["type error call to cos()", "print(cos(true));", /Cannot assign a boolean to a float/],
[
"type error call to hypot()",
'print(hypot("dog", 3.3));',
/Cannot assign a string to a float/,
],
[
"too many arguments to hypot()",
"print(hypot(1, 2, 3));",
/2 argument\(s\) required but 3 passed/,
],
["Non-type in param", "let x=1;function f(y:x){}", /Type expected/],
["Non-type in return type", "let x=1;function f():x{return 1;}", /Type expected/],
["Non-type in field type", "let x=1;struct S {y:x}", /Type expected/],
]
describe("The analyzer", () => {
for (const [scenario, source] of semanticChecks) {
it(`recognizes ${scenario}`, () => {
assert.ok(analyze(parse(source)))
})
}
for (const [scenario, source, errorMessagePattern] of semanticErrors) {
it(`throws on ${scenario}`, () => {
assert.throws(() => analyze(parse(source)), errorMessagePattern)
})
}
it("produces the expected representation for a trivial program", () => {
assert.deepEqual(
analyze(parse("let x = π + 2.2;")),
program([
variableDeclaration(
variable("x", true, floatType),
binary("+", variable("π", false, floatType), 2.2, floatType)
),
])
)
})
})
Study these tests, and if you have the inclination, write some of your own.
Of course, if you ran npm test now, you’d get errors since we haven’t yet implemented the analyzer itself. That’s next.
Writing the Semantic Analyzer
The analyzer is, well, really big. But we’ll do our best to structure it in manageable pieces. Here’s a big picture view of the file:
class Context { /* ... */ }
export default function analyze(match) {
/* a local variable to hold the current context */
/* a bunch of semantic validation functions */
/* Definitions of the semantic actions */
/* One line to run it */
}
Here’s the Carlos analyzer. It’s a big module. There is so much to explain. Rather than using the guide to explain what is going on, we’ll defer you to the comments within the source code below:
// The semantic analyzer exports a single function, analyze(match), that
// accepts a grammar match object (the CST) from Ohm and produces the
// internal representation of the program (pretty close to what is usually
// called the AST). This representation also includes entities from the
// standard library, as needed.
import * as core from "./core.js"
class Context {
// Like most statically-scoped languages, Carlos contexts will contain a
// map for their locally declared identifiers and a reference to the parent
// context. The parent of the global context is null. In addition, the
// context records whether analysis is current within a loop (so we can
// properly check break statements), and reference to the current function
// (so we can properly check return statements).
constructor({ parent = null, locals = new Map(), inLoop = false, function: f = null }) {
Object.assign(this, { parent, locals, inLoop, function: f })
}
add(name, entity) {
this.locals.set(name, entity)
}
lookup(name) {
return this.locals.get(name) || this.parent?.lookup(name)
}
static root() {
return new Context({ locals: new Map(Object.entries(core.standardLibrary)) })
}
newChildContext(props) {
return new Context({ ...this, ...props, parent: this, locals: new Map() })
}
}
export default function analyze(match) {
// Track the context manually via a simple variable. The initial context
// contains the mappings from the standard library. Add to this context
// as necessary. When needing to descent into a new scope, create a new
// context with the current context as its parent. When leaving a scope,
// reset this variable to the parent context.
let context = Context.root()
// The single gate for error checking. Pass in a condition that must be true.
// Use errorLocation to give contextual information about the error that will
// appear: this should be an object whose "at" property is a parse tree node.
// Ohm's getLineAndColumnMessage will be used to prefix the error message. This
// allows any semantic analysis errors to be presented to an end user in the
// same format as Ohm's reporting of syntax errors.
function must(condition, message, errorLocation) {
if (!condition) {
const prefix = errorLocation.at.source.getLineAndColumnMessage()
throw new Error(`${prefix}${message}`)
}
}
// Next come a number of carefully named utility functions that keep the
// analysis code clean and readable. Without these utilities, the analysis
// code would be cluttered with if-statements and error messages. Each of
// the utilities accept a parameter that should be an object with an "at"
// property that is a parse tree node. This is used to provide contextual
// information in the error message.
function mustNotAlreadyBeDeclared(name, at) {
must(!context.lookup(name), `Identifier ${name} already declared`, at)
}
function mustHaveBeenFound(entity, name, at) {
must(entity, `Identifier ${name} not declared`, at)
}
function mustHaveNumericType(e, at) {
const expectedTypes = [core.intType, core.floatType]
must(expectedTypes.includes(e.type), "Expected a number", at)
}
function mustHaveNumericOrStringType(e, at) {
const expectedTypes = [core.intType, core.floatType, core.stringType]
must(expectedTypes.includes(e.type), "Expected a number or string", at)
}
function mustHaveBooleanType(e, at) {
must(e.type === core.booleanType, "Expected a boolean", at)
}
function mustHaveIntegerType(e, at) {
must(e.type === core.intType, "Expected an integer", at)
}
function mustHaveAnArrayType(e, at) {
must(e.type?.kind === "ArrayType", "Expected an array", at)
}
function mustHaveAnOptionalType(e, at) {
must(e.type?.kind === "OptionalType", "Expected an optional", at)
}
function mustHaveAStructType(e, at) {
must(e.type?.kind === "StructType", "Expected a struct", at)
}
function mustHaveAnOptionalStructType(e, at) {
// Used to check e?.x expressions, e must be an optional struct
must(
e.type?.kind === "OptionalType" && e.type.baseType?.kind === "StructType",
"Expected an optional struct",
at
)
}
function mustBothHaveTheSameType(e1, e2, at) {
must(equivalent(e1.type, e2.type), "Operands do not have the same type", at)
}
function mustAllHaveSameType(expressions, at) {
// Used to check the elements of an array expression, and the two
// arms of a conditional expression, among other scenarios.
must(
expressions.slice(1).every(e => equivalent(e.type, expressions[0].type)),
"Not all elements have the same type",
at
)
}
function mustBeAType(e, at) {
const isBasicType = /int|float|string|bool|void|any/.test(e)
const isCompositeType = /StructType|FunctionType|ArrayType|OptionalType/.test(e?.kind)
must(isBasicType || isCompositeType, "Type expected", at)
}
function mustBeAnArrayType(t, at) {
must(t?.kind === "ArrayType", "Must be an array type", at)
}
function equivalent(t1, t2) {
return (
t1 === t2 ||
(t1?.kind === "OptionalType" &&
t2?.kind === "OptionalType" &&
equivalent(t1.baseType, t2.baseType)) ||
(t1?.kind === "ArrayType" &&
t2?.kind === "ArrayType" &&
equivalent(t1.baseType, t2.baseType)) ||
(t1?.kind === "FunctionType" &&
t2?.kind === "FunctionType" &&
equivalent(t1.returnType, t2.returnType) &&
t1.paramTypes.length === t2.paramTypes.length &&
t1.paramTypes.every((t, i) => equivalent(t, t2.paramTypes[i])))
)
}
function assignable(fromType, toType) {
return (
toType == core.anyType ||
equivalent(fromType, toType) ||
(fromType?.kind === "FunctionType" &&
toType?.kind === "FunctionType" &&
// covariant in return types
assignable(fromType.returnType, toType.returnType) &&
fromType.paramTypes.length === toType.paramTypes.length &&
// contravariant in parameter types
toType.paramTypes.every((t, i) => assignable(t, fromType.paramTypes[i])))
)
}
function typeDescription(type) {
if (typeof type === "string") return type
if (type.kind == "StructType") return type.name
if (type.kind == "FunctionType") {
const paramTypes = type.paramTypes.map(typeDescription).join(", ")
const returnType = typeDescription(type.returnType)
return `(${paramTypes})->${returnType}`
}
if (type.kind == "ArrayType") return `[${typeDescription(type.baseType)}]`
if (type.kind == "OptionalType") return `${typeDescription(type.baseType)}?`
}
function mustBeAssignable(e, { toType: type }, at) {
const source = typeDescription(e.type)
const target = typeDescription(type)
const message = `Cannot assign a ${source} to a ${target}`
must(assignable(e.type, type), message, at)
}
function isMutable(e) {
return (
(e?.kind === "Variable" && e?.mutable) ||
(e?.kind === "SubscriptExpression" && isMutable(e?.array)) ||
(e?.kind === "MemberExpression" && isMutable(e?.object))
)
}
function mustBeMutable(e, at) {
must(isMutable(e), "Cannot assign to immutable variable", at)
}
function mustHaveDistinctFields(type, at) {
const fieldNames = new Set(type.fields.map(f => f.name))
must(fieldNames.size === type.fields.length, "Fields must be distinct", at)
}
function mustHaveMember(structType, field, at) {
must(structType.fields.map(f => f.name).includes(field), "No such field", at)
}
function mustBeInLoop(at) {
must(context.inLoop, "Break can only appear in a loop", at)
}
function mustBeInAFunction(at) {
must(context.function, "Return can only appear in a function", at)
}
function mustBeCallable(e, at) {
const callable = e?.kind === "StructType" || e.type?.kind === "FunctionType"
must(callable, "Call of non-function or non-constructor", at)
}
function mustNotReturnAnything(f, at) {
const returnsNothing = f.type.returnType === core.voidType
must(returnsNothing, "Something should be returned", at)
}
function mustReturnSomething(f, at) {
const returnsSomething = f.type.returnType !== core.voidType
must(returnsSomething, "Cannot return a value from this function", at)
}
function mustBeReturnable(e, { from: f }, at) {
mustBeAssignable(e, { toType: f.type.returnType }, at)
}
function mustHaveCorrectArgumentCount(argCount, paramCount, at) {
const message = `${paramCount} argument(s) required but ${argCount} passed`
must(argCount === paramCount, message, at)
}
// Building the program representation will be done together with semantic
// analysis and error checking. In Ohm, we do this with a semantics object
// that has an operation for each relevant rule in the grammar. Since the
// purpose of analysis is to build the program representation, we will name
// the operations "rep" for "representation". Most of the rules are straight-
// forward except for those dealing with function and type declarations,
// since types and functions need to be dealt with in two steps to allow
// recursion.
const builder = match.matcher.grammar.createSemantics().addOperation("rep", {
Program(statements) {
return core.program(statements.children.map(s => s.rep()))
},
VarDecl(modifier, id, _eq, exp, _semicolon) {
mustNotAlreadyBeDeclared(id.sourceString, { at: id })
const initializer = exp.rep()
const mutable = modifier.sourceString === "let"
const variable = core.variable(id.sourceString, mutable, initializer.type)
context.add(id.sourceString, variable)
return core.variableDeclaration(variable, initializer)
},
TypeDecl(_struct, id, _left, fields, _right) {
mustNotAlreadyBeDeclared(id.sourceString, { at: id })
// To allow recursion, enter type name into context before the fields
const type = core.structType(id.sourceString, [])
context.add(id.sourceString, type)
type.fields = fields.children.map(field => field.rep())
mustHaveDistinctFields(type, { at: id })
return core.typeDeclaration(type)
},
Field(id, _colon, type) {
return core.field(id.sourceString, type.rep())
},
FunDecl(_fun, id, parameters, _colons, type, block) {
mustNotAlreadyBeDeclared(id.sourceString, { at: id })
// Add immediately so that we can have recursion
const fun = core.fun(id.sourceString)
context.add(id.sourceString, fun)
// Parameters are part of the child context
context = context.newChildContext({ inLoop: false, function: fun })
fun.params = parameters.rep()
// Now that the parameters are known, we compute the function's type.
// This is fine; we did not need the type to analyze the parameters,
// but we do need to set it before analyzing the body.
const paramTypes = fun.params.map(param => param.type)
const returnType = type.children?.[0]?.rep() ?? core.voidType
fun.type = core.functionType(paramTypes, returnType)
// Analyze body while still in child context
fun.body = block.rep()
// Go back up to the outer context before returning
context = context.parent
return core.functionDeclaration(fun)
},
Params(_open, paramList, _close) {
// Returns a list of variable nodes
return paramList.asIteration().children.map(p => p.rep())
},
Param(id, _colon, type) {
const param = core.variable(id.sourceString, false, type.rep())
mustNotAlreadyBeDeclared(param.name, { at: id })
context.add(param.name, param)
return param
},
Type_optional(baseType, _questionMark) {
return core.optionalType(baseType.rep())
},
Type_array(_left, baseType, _right) {
return core.arrayType(baseType.rep())
},
Type_function(_left, types, _right, _arrow, type) {
const paramTypes = types.asIteration().children.map(t => t.rep())
const returnType = type.rep()
return core.functionType(paramTypes, returnType)
},
Type_id(id) {
const entity = context.lookup(id.sourceString)
mustHaveBeenFound(entity, id.sourceString, { at: id })
mustBeAType(entity, { at: id })
return entity
},
Statement_bump(exp, operator, _semicolon) {
const variable = exp.rep()
mustHaveIntegerType(variable, { at: exp })
return operator.sourceString === "++"
? core.increment(variable)
: core.decrement(variable)
},
Statement_assign(variable, _eq, expression, _semicolon) {
const source = expression.rep()
const target = variable.rep()
mustBeMutable(target, { at: variable })
mustBeAssignable(source, { toType: target.type }, { at: variable })
return core.assignment(target, source)
},
Statement_call(call, _semicolon) {
return call.rep()
},
Statement_break(breakKeyword, _semicolon) {
mustBeInLoop({ at: breakKeyword })
return core.breakStatement
},
Statement_return(returnKeyword, exp, _semicolon) {
mustBeInAFunction({ at: returnKeyword })
mustReturnSomething(context.function, { at: returnKeyword })
const returnExpression = exp.rep()
mustBeReturnable(returnExpression, { from: context.function }, { at: exp })
return core.returnStatement(returnExpression)
},
Statement_shortreturn(returnKeyword, _semicolon) {
mustBeInAFunction({ at: returnKeyword })
mustNotReturnAnything(context.function, { at: returnKeyword })
return core.shortReturnStatement
},
IfStmt_long(_if, exp, block1, _else, block2) {
const test = exp.rep()
mustHaveBooleanType(test, { at: exp })
context = context.newChildContext()
const consequent = block1.rep()
context = context.parent
context = context.newChildContext()
const alternate = block2.rep()
context = context.parent
return core.ifStatement(test, consequent, alternate)
},
IfStmt_elsif(_if, exp, block, _else, trailingIfStatement) {
const test = exp.rep()
mustHaveBooleanType(test, { at: exp })
context = context.newChildContext()
const consequent = block.rep()
context = context.parent
const alternate = trailingIfStatement.rep()
return core.ifStatement(test, consequent, alternate)
},
IfStmt_short(_if, exp, block) {
const test = exp.rep()
mustHaveBooleanType(test, { at: exp })
context = context.newChildContext()
const consequent = block.rep()
context = context.parent
return core.shortIfStatement(test, consequent)
},
LoopStmt_while(_while, exp, block) {
const test = exp.rep()
mustHaveBooleanType(test, { at: exp })
context = context.newChildContext({ inLoop: true })
const body = block.rep()
context = context.parent
return core.whileStatement(test, body)
},
LoopStmt_repeat(_repeat, exp, block) {
const count = exp.rep()
mustHaveIntegerType(count, { at: exp })
context = context.newChildContext({ inLoop: true })
const body = block.rep()
context = context.parent
return core.repeatStatement(count, body)
},
LoopStmt_range(_for, id, _in, exp1, op, exp2, block) {
const [low, high] = [exp1.rep(), exp2.rep()]
mustHaveIntegerType(low, { at: exp1 })
mustHaveIntegerType(high, { at: exp2 })
const iterator = core.variable(id.sourceString, false, core.intType)
context = context.newChildContext({ inLoop: true })
context.add(id.sourceString, iterator)
const body = block.rep()
context = context.parent
return core.forRangeStatement(iterator, low, op.sourceString, high, body)
},
LoopStmt_collection(_for, id, _in, exp, block) {
const collection = exp.rep()
mustHaveAnArrayType(collection, { at: exp })
const iterator = core.variable(id.sourceString, false, collection.type.baseType)
context = context.newChildContext({ inLoop: true })
context.add(iterator.name, iterator)
const body = block.rep()
context = context.parent
return core.forStatement(iterator, collection, body)
},
Block(_open, statements, _close) {
// No need for a block node, just return the list of statements
return statements.children.map(s => s.rep())
},
Exp_conditional(exp, _questionMark, exp1, colon, exp2) {
const test = exp.rep()
mustHaveBooleanType(test, { at: exp })
const [consequent, alternate] = [exp1.rep(), exp2.rep()]
mustBothHaveTheSameType(consequent, alternate, { at: colon })
return core.conditional(test, consequent, alternate, consequent.type)
},
Exp1_unwrapelse(exp1, elseOp, exp2) {
const [optional, op, alternate] = [exp1.rep(), elseOp.sourceString, exp2.rep()]
mustHaveAnOptionalType(optional, { at: exp1 })
mustBeAssignable(alternate, { toType: optional.type.baseType }, { at: exp2 })
return core.binary(op, optional, alternate, optional.type)
},
Exp2_or(exp, _ops, exps) {
let left = exp.rep()
mustHaveBooleanType(left, { at: exp })
for (let e of exps.children) {
let right = e.rep()
mustHaveBooleanType(right, { at: e })
left = core.binary("||", left, right, core.booleanType)
}
return left
},
Exp2_and(exp, _ops, exps) {
let left = exp.rep()
mustHaveBooleanType(left, { at: exp })
for (let e of exps.children) {
let right = e.rep()
mustHaveBooleanType(right, { at: e })
left = core.binary("&&", left, right, core.booleanType)
}
return left
},
Exp3_bitor(exp, _ops, exps) {
let left = exp.rep()
mustHaveIntegerType(left, { at: exp })
for (let e of exps.children) {
let right = e.rep()
mustHaveIntegerType(right, { at: e })
left = core.binary("|", left, right, core.intType)
}
return left
},
Exp3_bitxor(exp, xorOps, exps) {
let left = exp.rep()
mustHaveIntegerType(left, { at: exp })
for (let e of exps.children) {
let right = e.rep()
mustHaveIntegerType(right, { at: e })
left = core.binary("^", left, right, core.intType)
}
return left
},
Exp3_bitand(exp, andOps, exps) {
let left = exp.rep()
mustHaveIntegerType(left, { at: exp })
for (let e of exps.children) {
let right = e.rep()
mustHaveIntegerType(right, { at: e })
left = core.binary("&", left, right, core.intType)
}
return left
},
Exp4_compare(exp1, relop, exp2) {
const [left, op, right] = [exp1.rep(), relop.sourceString, exp2.rep()]
// == and != can have any operand types as long as they are the same
// But inequality operators can only be applied to numbers and strings
if (["<", "<=", ">", ">="].includes(op)) {
mustHaveNumericOrStringType(left, { at: exp1 })
}
mustBothHaveTheSameType(left, right, { at: relop })
return core.binary(op, left, right, core.booleanType)
},
Exp5_shift(exp1, shiftOp, exp2) {
const [left, op, right] = [exp1.rep(), shiftOp.sourceString, exp2.rep()]
mustHaveIntegerType(left, { at: exp1 })
mustHaveIntegerType(right, { at: exp2 })
return core.binary(op, left, right, core.intType)
},
Exp6_add(exp1, addOp, exp2) {
const [left, op, right] = [exp1.rep(), addOp.sourceString, exp2.rep()]
if (op === "+") {
mustHaveNumericOrStringType(left, { at: exp1 })
} else {
mustHaveNumericType(left, { at: exp1 })
}
mustBothHaveTheSameType(left, right, { at: addOp })
return core.binary(op, left, right, left.type)
},
Exp7_multiply(exp1, mulOp, exp2) {
const [left, op, right] = [exp1.rep(), mulOp.sourceString, exp2.rep()]
mustHaveNumericType(left, { at: exp1 })
mustBothHaveTheSameType(left, right, { at: mulOp })
return core.binary(op, left, right, left.type)
},
Exp8_power(exp1, powerOp, exp2) {
const [left, op, right] = [exp1.rep(), powerOp.sourceString, exp2.rep()]
mustHaveNumericType(left, { at: exp1 })
mustBothHaveTheSameType(left, right, { at: powerOp })
return core.binary(op, left, right, left.type)
},
Exp8_unary(unaryOp, exp) {
const [op, operand] = [unaryOp.sourceString, exp.rep()]
let type
if (op === "#") {
mustHaveAnArrayType(operand, { at: exp })
type = core.intType
} else if (op === "-") {
mustHaveNumericType(operand, { at: exp })
type = operand.type
} else if (op === "!") {
mustHaveBooleanType(operand, { at: exp })
type = core.booleanType
} else if (op === "some") {
type = core.optionalType(operand.type)
} else if (op === "random") {
mustHaveAnArrayType(operand, { at: exp })
type = operand.type.baseType
}
return core.unary(op, operand, type)
},
Exp9_emptyarray(ty, _open, _close) {
const type = ty.rep()
mustBeAnArrayType(type, { at: ty })
return core.emptyArray(type)
},
Exp9_arrayexp(_open, args, _close) {
const elements = args.asIteration().children.map(e => e.rep())
mustAllHaveSameType(elements, { at: args })
return core.arrayExpression(elements)
},
Exp9_emptyopt(_no, type) {
return core.emptyOptional(type.rep())
},
Exp9_parens(_open, expression, _close) {
return expression.rep()
},
Exp9_subscript(exp1, _open, exp2, _close) {
const [array, subscript] = [exp1.rep(), exp2.rep()]
mustHaveAnArrayType(array, { at: exp1 })
mustHaveIntegerType(subscript, { at: exp2 })
return core.subscript(array, subscript)
},
Exp9_member(exp, dot, id) {
const object = exp.rep()
let structType
if (dot.sourceString === "?.") {
mustHaveAnOptionalStructType(object, { at: exp })
structType = object.type.baseType
} else {
mustHaveAStructType(object, { at: exp })
structType = object.type
}
mustHaveMember(structType, id.sourceString, { at: id })
const field = structType.fields.find(f => f.name === id.sourceString)
return core.memberExpression(object, dot.sourceString, field)
},
Exp9_call(exp, open, expList, _close) {
const callee = exp.rep()
mustBeCallable(callee, { at: exp })
const exps = expList.asIteration().children
const targetTypes =
callee?.kind === "StructType"
? callee.fields.map(f => f.type)
: callee.type.paramTypes
mustHaveCorrectArgumentCount(exps.length, targetTypes.length, { at: open })
const args = exps.map((exp, i) => {
const arg = exp.rep()
mustBeAssignable(arg, { toType: targetTypes[i] }, { at: exp })
return arg
})
return callee?.kind === "StructType"
? core.constructorCall(callee, args)
: core.functionCall(callee, args)
},
Exp9_id(id) {
// When an id appears in an expression, it had better have been declared
const entity = context.lookup(id.sourceString)
mustHaveBeenFound(entity, id.sourceString, { at: id })
return entity
},
true(_) {
return true
},
false(_) {
return false
},
intlit(_digits) {
// Carlos ints will be represented as plain JS bigints
return BigInt(this.sourceString)
},
floatlit(_whole, _point, _fraction, _e, _sign, _exponent) {
// Carlos floats will be represented as plain JS numbers
return Number(this.sourceString)
},
stringlit(_openQuote, _chars, _closeQuote) {
// Carlos strings will be represented as plain JS strings, including
// the quotation marks
return this.sourceString
},
})
return builder(match).rep()
}
What was this module so large?In some sense, the size of this module compared to the others isn’t really too surprising. Syntax was much easier: grammar processing is a well-understood process, so we get great libraries like Ohm that can parse pretty much any language. But semantic processing is language-dependent, context-sensitive, and full of sometimes messy and crazy rules.
At this point:
- Fill in src/analyzer.js.
- Run
npm testand make sure we’ve satisfied the tests we wrote earlier. - Run
node src/carlos.js examples/gcd.carlos analyzedand make sure the output looks good. You should now be able to see graph-stringify in action. - Try a few more examples an explore the representations that you can now build.
- git add, commit, and push.
Optimization
In practice, you do optimizations, or code improvement, at several different places throughout a compiler. But many compilers have a special optimization pass that runs on the program representation, right after semantic analysis. A simple optimizer includes strength reductions, constant folding, dead code elimination for while-false and simplifications for if-true and if-false. Tests first:
import { describe, it } from "node:test"
import assert from "node:assert/strict"
import optimize from "../src/optimizer.js"
import * as core from "../src/core.js"
// Make some test cases easier to read
const i = core.variable("x", true, core.intType)
const x = core.variable("x", true, core.floatType)
const a = core.variable("a", true, core.arrayType(core.intType))
const xpp = core.increment(x)
const xmm = core.decrement(x)
const return1p1 = core.returnStatement(core.binary("+", 1, 1, core.intType))
const return2 = core.returnStatement(2)
const returnX = core.returnStatement(x)
const onePlusTwo = core.binary("+", 1, 2, core.intType)
const aParam = core.variable("a", false, core.anyType)
const anyToAny = core.functionType([core.anyType], core.anyType)
const identity = Object.assign(core.fun("id", [aParam], [returnX], anyToAny))
const voidInt = core.functionType([], core.intType)
const intFun = body => core.fun("f", [], body, voidInt)
const intFunDecl = body => core.functionDeclaration(intFun(body))
const callIdentity = args => core.functionCall(identity, args)
const or = (...d) => d.reduce((x, y) => core.binary("||", x, y))
const and = (...c) => c.reduce((x, y) => core.binary("&&", x, y))
const less = (x, y) => core.binary("<", x, y)
const eq = (x, y) => core.binary("==", x, y)
const times = (x, y) => core.binary("*", x, y)
const neg = x => core.unary("-", x)
const array = (...elements) => core.arrayExpression(elements)
const assign = (v, e) => core.assignment(v, e)
const emptyArray = core.emptyArray(core.intType)
const sub = (a, e) => core.subscript(a, e)
const unwrapElse = (o, e) => core.binary("??", o, e)
const emptyOptional = core.emptyOptional(core.intType)
const some = x => core.unary("some", x)
const program = core.program
const tests = [
["folds +", core.binary("+", 5, 8), 13],
["folds -", core.binary("-", 5n, 8n), -3n],
["folds *", core.binary("*", 5, 8), 40],
["folds /", core.binary("/", 5, 8), 0.625],
["folds **", core.binary("**", 5, 8), 390625],
["folds <", core.binary("<", 5, 8), true],
["folds <=", core.binary("<=", 5, 8), true],
["folds ==", core.binary("==", 5, 8), false],
["folds !=", core.binary("!=", 5, 8), true],
["folds >=", core.binary(">=", 5, 8), false],
["folds >", core.binary(">", 5, 8), false],
["optimizes +0", core.binary("+", x, 0), x],
["optimizes -0", core.binary("-", x, 0), x],
["optimizes *1 for ints", core.binary("*", i, 1), i],
["optimizes *1 for floats", core.binary("*", x, 1), x],
["optimizes /1", core.binary("/", x, 1), x],
["optimizes *0", core.binary("*", x, 0), 0],
["optimizes 0*", core.binary("*", 0, x), 0],
["optimizes 0/", core.binary("/", 0, x), 0],
["optimizes 0+ for floats", core.binary("+", 0, x), x],
["optimizes 0+ for ints", core.binary("+", 0n, i), i],
["optimizes 0-", core.binary("-", 0, x), neg(x)],
["optimizes 1*", core.binary("*", 1, x), x],
["folds negation", core.unary("-", 8), -8],
["optimizes 1** for ints", core.binary("**", 1n, i), 1n],
["optimizes 1** for floats", core.binary("**", 1n, x), 1n],
["optimizes **0", core.binary("**", x, 0), 1],
["removes left false from ||", or(false, less(x, 1)), less(x, 1)],
["removes right false from ||", or(less(x, 1), false), less(x, 1)],
["removes left true from &&", and(true, less(x, 1)), less(x, 1)],
["removes right true from &&", and(less(x, 1), true), less(x, 1)],
["removes x=x at beginning", program([core.assignment(x, x), xpp]), program([xpp])],
["removes x=x at end", program([xpp, core.assignment(x, x)]), program([xpp])],
["removes x=x in middle", program([xpp, assign(x, x), xpp]), program([xpp, xpp])],
["optimizes if-true", core.ifStatement(true, [xpp], []), [xpp]],
["optimizes if-false", core.ifStatement(false, [], [xpp]), [xpp]],
["optimizes short-if-true", core.shortIfStatement(true, [xmm]), [xmm]],
["optimizes short-if-false", core.shortIfStatement(false, [xpp]), []],
["optimizes while-false", program([core.whileStatement(false, [xpp])]), program([])],
["optimizes repeat-0", program([core.repeatStatement(0, [xpp])]), program([])],
["optimizes for-range", core.forRangeStatement(x, 5, "...", 3, [xpp]), []],
["optimizes for-empty-array", core.forStatement(x, emptyArray, [xpp]), []],
["applies if-false after folding", core.shortIfStatement(eq(1, 1), [xpp]), [xpp]],
["optimizes away nil", unwrapElse(emptyOptional, 3), 3],
["optimizes left conditional true", core.conditional(true, 55, 89), 55],
["optimizes left conditional false", core.conditional(false, 55, 89), 89],
[
"optimizes in functions",
program([intFunDecl([return1p1])]),
program([intFunDecl([return2])]),
],
["optimizes in subscripts", sub(a, onePlusTwo), sub(a, 3)],
["optimizes in array literals", array(0, onePlusTwo, 9), array(0, 3, 9)],
["optimizes in arguments", callIdentity([times(3, 5)]), callIdentity([15])],
[
"passes through nonoptimizable constructs",
...Array(2).fill([
core.program([core.shortReturnStatement]),
core.variableDeclaration("x", true, "z"),
core.typeDeclaration([core.field("x", core.intType)]),
core.assignment(x, core.binary("*", x, "z")),
core.assignment(x, core.unary("not", x)),
core.constructorCall(identity, core.memberExpression(x, ".", "f")),
core.variableDeclaration("q", false, core.emptyArray(core.floatType)),
core.variableDeclaration("r", false, core.emptyOptional(core.intType)),
core.whileStatement(true, [core.breakStatement]),
core.repeatStatement(5, [core.returnStatement(1)]),
core.conditional(x, 1, 2),
unwrapElse(some(x), 7),
core.ifStatement(x, [], []),
core.shortIfStatement(x, []),
core.forRangeStatement(x, 2, "..<", 5, []),
core.forStatement(x, array(1, 2, 3), []),
]),
],
]
describe("The optimizer", () => {
for (const [scenario, before, after] of tests) {
it(`${scenario}`, () => {
assert.deepEqual(optimize(before), after)
})
}
})
and the actual optimizer:
// The optimizer module exports a single function, optimize(node), to perform
// machine-independent optimizations on the analyzed semantic representation.
//
// The only optimizations supported here are:
//
// - assignments to self (x = x) turn into no-ops
// - constant folding
// - some strength reductions (+0, -0, *0, *1, etc.)
// - turn references to built-ins true and false to be literals
// - remove all disjuncts in || list after literal true
// - remove all conjuncts in && list after literal false
// - while-false becomes a no-op
// - repeat-0 is a no-op
// - for-loop over empty array is a no-op
// - for-loop with low > high is a no-op
// - if-true and if-false reduce to only the taken arm
//
// The optimizer also replaces token references with their actual values,
// since the original token line and column numbers are no longer needed.
// This simplifies code generation.
import * as core from "./core.js"
export default function optimize(node) {
return optimizers?.[node.kind]?.(node) ?? node
}
const isZero = n => n === 0 || n === 0n
const isOne = n => n === 1 || n === 1n
const optimizers = {
Program(p) {
p.statements = p.statements.flatMap(optimize)
return p
},
VariableDeclaration(d) {
d.variable = optimize(d.variable)
d.initializer = optimize(d.initializer)
return d
},
TypeDeclaration(d) {
d.type = optimize(d.type)
return d
},
FunctionDeclaration(d) {
d.fun = optimize(d.fun)
return d
},
Function(f) {
if (f.body) f.body = f.body.flatMap(optimize)
return f
},
Increment(s) {
s.variable = optimize(s.variable)
return s
},
Decrement(s) {
s.variable = optimize(s.variable)
return s
},
Assignment(s) {
s.source = optimize(s.source)
s.target = optimize(s.target)
if (s.source === s.target) {
return []
}
return s
},
BreakStatement(s) {
return s
},
ReturnStatement(s) {
s.expression = optimize(s.expression)
return s
},
ShortReturnStatement(s) {
return s
},
IfStatement(s) {
s.test = optimize(s.test)
s.consequent = s.consequent.flatMap(optimize)
if (s.alternate?.kind?.endsWith?.("IfStatement")) {
s.alternate = optimize(s.alternate)
} else {
s.alternate = s.alternate.flatMap(optimize)
}
if (s.test.constructor === Boolean) {
return s.test ? s.consequent : s.alternate
}
return s
},
ShortIfStatement(s) {
s.test = optimize(s.test)
s.consequent = s.consequent.flatMap(optimize)
if (s.test.constructor === Boolean) {
return s.test ? s.consequent : []
}
return s
},
WhileStatement(s) {
s.test = optimize(s.test)
if (s.test === false) {
// while false is a no-op
return []
}
s.body = s.body.flatMap(optimize)
return s
},
RepeatStatement(s) {
s.count = optimize(s.count)
if (s.count === 0) {
// repeat 0 times is a no-op
return []
}
s.body = s.body.flatMap(optimize)
return s
},
ForRangeStatement(s) {
s.iterator = optimize(s.iterator)
s.low = optimize(s.low)
s.op = optimize(s.op)
s.high = optimize(s.high)
s.body = s.body.flatMap(optimize)
if (s.low.constructor === Number) {
if (s.high.constructor === Number) {
if (s.low > s.high) {
return []
}
}
}
return s
},
ForStatement(s) {
s.iterator = optimize(s.iterator)
s.collection = optimize(s.collection)
s.body = s.body.flatMap(optimize)
if (s.collection?.kind === "EmptyArray") {
return []
}
return s
},
Conditional(e) {
e.test = optimize(e.test)
e.consequent = optimize(e.consequent)
e.alternate = optimize(e.alternate)
if (e.test.constructor === Boolean) {
return e.test ? e.consequent : e.alternate
}
return e
},
BinaryExpression(e) {
e.op = optimize(e.op)
e.left = optimize(e.left)
e.right = optimize(e.right)
if (e.op === "??") {
// Coalesce empty optional unwraps
if (e.left?.kind === "EmptyOptional") {
return e.right
}
} else if (e.op === "&&") {
// Optimize boolean constants in && and ||
if (e.left === true) return e.right
if (e.right === true) return e.left
} else if (e.op === "||") {
if (e.left === false) return e.right
if (e.right === false) return e.left
} else if ([Number, BigInt].includes(e.left.constructor)) {
// Numeric constant folding when left operand is constant
if ([Number, BigInt].includes(e.right.constructor)) {
if (e.op === "+") return e.left + e.right
if (e.op === "-") return e.left - e.right
if (e.op === "*") return e.left * e.right
if (e.op === "/") return e.left / e.right
if (e.op === "**") return e.left ** e.right
if (e.op === "<") return e.left < e.right
if (e.op === "<=") return e.left <= e.right
if (e.op === "==") return e.left === e.right
if (e.op === "!=") return e.left !== e.right
if (e.op === ">=") return e.left >= e.right
if (e.op === ">") return e.left > e.right
}
if (isZero(e.left) && e.op === "+") return e.right
if (isOne(e.left) && e.op === "*") return e.right
if (isZero(e.left) && e.op === "-") return core.unary("-", e.right)
if (isOne(e.left) && e.op === "**") return e.left
if (isZero(e.left) && ["*", "/"].includes(e.op)) return e.left
} else if ([Number, BigInt].includes(e.right.constructor)) {
// Numeric constant folding when right operand is constant
if (["+", "-"].includes(e.op) && isZero(e.right)) return e.left
if (["*", "/"].includes(e.op) && isOne(e.right)) return e.left
if (e.op === "*" && isZero(e.right)) return e.right
if (e.op === "**" && isZero(e.right)) return 1
}
return e
},
UnaryExpression(e) {
e.op = optimize(e.op)
e.operand = optimize(e.operand)
if (e.operand.constructor === Number) {
if (e.op === "-") {
return -e.operand
}
}
return e
},
SubscriptExpression(e) {
e.array = optimize(e.array)
e.index = optimize(e.index)
return e
},
ArrayExpression(e) {
e.elements = e.elements.map(optimize)
return e
},
MemberExpression(e) {
e.object = optimize(e.object)
return e
},
FunctionCall(c) {
c.callee = optimize(c.callee)
c.args = c.args.map(optimize)
return c
},
ConstructorCall(c) {
c.callee = optimize(c.callee)
c.args = c.args.map(optimize)
return c
},
Print(s) {
s.args = s.args.map(optimize)
return s
},
}
There’s room for plenty more, but this is a good start.
At this point:
- Fill in test/optimizer.test.js
- Fill in src/optimizer.js.
- Run
npm testand make sure we’ve satisfied the tests we wrote earlier. - git add, commit, and push.
Generate Target Code
If all the semantic checks pass, we’re ready to walk our semantic graph and output some code. We can output JavaScript, C, LLVM, some made-up intermediate language, some virtual machine language, or anything really. In these notes, we’re going to output JavaScript.
There’s no real magic here; things are pretty straightforward. But there are some useful things to keep in mind:
- Carlos and JavaScript have different reserved words. So we put a numeric suffix on each of the identifiers to distinguish them: for example, the Carlos variable
switchmust become something likeswitch_1in JavaScript. The mapping from Carlos entity to JavaScript identifier name is kept in a little cache in the code generator, so each Carlos variable gets a distinct JS name. - Types are used only in the front-end of the compiler. One all the types are inferred, resolved, and checked, we know are Carlos program is type-safe. So we ignore them during code generation. Ditto for whether a variable is read-only or not.
- We’ll do “inlining” on the built-in functions.
When generating JavaScript code, we don’t have to expend any real effort into making the output pretty. If you wish to, you can bring in a third-party tool like js-beautify or see if you can get Prettier to work on your output.
As usual, start with the tests. We just pair example Carlos programs with the JS output we expect:
import { describe, it } from "node:test"
import assert from "node:assert/strict"
import parse from "../src/parser.js"
import analyze from "../src/analyzer.js"
import optimize from "../src/optimizer.js"
import generate from "../src/generator.js"
function dedent(s) {
return `${s}`.replace(/(?<=\n)\s+/g, "").trim()
}
const fixtures = [
{
name: "small",
source: `
let x = 3 * 7;
x++;
x--;
let y = true;
y = 5 ** -x / -100 > - x || false;
print((y && y) || false || (x*2) != 5);
`,
expected: dedent`
let x_1 = 21;
x_1++;
x_1--;
let y_2 = true;
y_2 = (((5 ** -(x_1)) / -(100)) > -(x_1));
console.log(((y_2 && y_2) || ((x_1 * 2) !== 5)));
`,
},
{
name: "if",
source: `
let x = 0;
if (x == 0) { print("1"); }
if (x == 0) { print(1); } else { print(2); }
if (x == 0) { print(1); } else if (x == 2) { print(3); }
if (x == 0) { print(1); } else if (x == 2) { print(3); } else { print(4); }
`,
expected: dedent`
let x_1 = 0;
if ((x_1 === 0)) {
console.log("1");
}
if ((x_1 === 0)) {
console.log(1);
} else {
console.log(2);
}
if ((x_1 === 0)) {
console.log(1);
} else
if ((x_1 === 2)) {
console.log(3);
}
if ((x_1 === 0)) {
console.log(1);
} else
if ((x_1 === 2)) {
console.log(3);
} else {
console.log(4);
}
`,
},
{
name: "while",
source: `
let x = 0;
while x < 5 {
let y = 0;
while y < 5 {
print(x * y);
y = y + 1;
break;
}
x = x + 1;
}
`,
expected: dedent`
let x_1 = 0;
while ((x_1 < 5)) {
let y_2 = 0;
while ((y_2 < 5)) {
console.log((x_1 * y_2));
y_2 = (y_2 + 1);
break;
}
x_1 = (x_1 + 1);
}
`,
},
{
name: "functions",
source: `
let z = 0.5;
function f(x: float, y: boolean) {
print(sin(x) > π);
return;
}
function g(): boolean {
return false;
}
f(sqrt(z), g());
`,
expected: dedent`
let z_1 = 0.5;
function f_2(x_3, y_4) {
console.log((Math.sin(x_3) > Math.PI));
return;
}
function g_5() {
return false;
}
f_2(Math.sqrt(z_1), g_5());
`,
},
{
name: "arrays",
source: `
let a = [true, false, true];
let b = [10, #a - 20, 30];
const c = [[int]]();
const d = random b;
print(a[1] || (b[0] < 88 ? false : true));
`,
expected: dedent`
let a_1 = [true,false,true];
let b_2 = [10,(a_1.length - 20),30];
let c_3 = [];
let d_4 = ((a=>a[~~(Math.random()*a.length)])(b_2));
console.log((a_1[1] || (((b_2[0] < 88)) ? (false) : (true))));
`,
},
{
name: "structs",
source: `
struct S { x: int }
let x = S(3);
print(x.x);
`,
expected: dedent`
class S_1 {
constructor(x_2) {
this["x_2"] = x_2;
}
}
let x_3 = new S_1(3);
console.log((x_3["x_2"]));
`,
},
{
name: "optionals",
source: `
let x = no int;
let y = x ?? 2;
struct S {x: int}
let z = some S(1);
let w = z?.x;
`,
expected: dedent`
let x_1 = undefined;
let y_2 = (x_1 ?? 2);
class S_3 {
constructor(x_4) {
this["x_4"] = x_4;
}
}
let z_5 = new S_3(1);
let w_6 = (z_5?.["x_4"]);
`,
},
{
name: "for loops",
source: `
for i in 1..<50 {
print(i);
}
for j in [10, 20, 30] {
print(j);
}
repeat 3 {
// hello
}
for k in 1...10 {
}
`,
expected: dedent`
for (let i_1 = 1; i_1 < 50; i_1++) {
console.log(i_1);
}
for (let j_2 of [10,20,30]) {
console.log(j_2);
}
for (let i_3 = 0; i_3 < 3; i_3++) {
}
for (let k_4 = 1; k_4 <= 10; k_4++) {
}
`,
},
{
name: "standard library",
source: `
let x = 0.5;
print(sin(x) - cos(x) + exp(x) * ln(x) / hypot(2.3, x));
print(bytes("∞§¶•"));
print(codepoints("💪🏽💪🏽🖖👩🏾💁🏽♀️"));
`,
expected: dedent`
let x_1 = 0.5;
console.log(((Math.sin(x_1) - Math.cos(x_1)) + ((Math.exp(x_1) * Math.log(x_1)) / Math.hypot(2.3,x_1))));
console.log([...Buffer.from("∞§¶•", "utf8")]);
console.log([...("💪🏽💪🏽🖖👩🏾💁🏽♀️")].map(s=>s.codePointAt(0)));
`,
},
]
describe("The code generator", () => {
for (const fixture of fixtures) {
it(`produces expected js output for the ${fixture.name} program`, () => {
const actual = generate(optimize(analyze(parse(fixture.source))))
assert.deepEqual(actual, fixture.expected)
})
}
})
and the generator itself:
// The code generator exports a single function, generate(program), which
// accepts a program representation and returns the JavaScript translation
// as a string.
import { voidType, standardLibrary } from "./core.js"
export default function generate(program) {
// When generating code for statements, we'll accumulate the lines of
// the target code here. When we finish generating, we'll join the lines
// with newlines and return the result.
const output = []
// Variable and function names in JS will be suffixed with _1, _2, _3,
// etc. This is because "switch", for example, is a legal name in Carlos,
// but not in JS. So, the Carlos variable "switch" must become something
// like "switch_1". We handle this by mapping each name to its suffix.
const targetName = (mapping => {
return entity => {
if (!mapping.has(entity)) {
mapping.set(entity, mapping.size + 1)
}
return `${entity.name}_${mapping.get(entity)}`
}
})(new Map())
const gen = node => generators?.[node?.kind]?.(node) ?? node
const generators = {
// Key idea: when generating an expression, just return the JS string; when
// generating a statement, write lines of translated JS to the output array.
Program(p) {
p.statements.forEach(gen)
},
VariableDeclaration(d) {
// We don't care about const vs. let in the generated code! The analyzer has
// already checked that we never updated a const, so let is always fine.
output.push(`let ${gen(d.variable)} = ${gen(d.initializer)};`)
},
TypeDeclaration(d) {
// The only type declaration in Carlos is the struct! Becomes a JS class.
output.push(`class ${gen(d.type)} {`)
output.push(`constructor(${d.type.fields.map(gen).join(",")}) {`)
for (let field of d.type.fields) {
output.push(`this[${JSON.stringify(gen(field))}] = ${gen(field)};`)
}
output.push("}")
output.push("}")
},
StructType(t) {
return targetName(t)
},
Field(f) {
return targetName(f)
},
FunctionDeclaration(d) {
output.push(`function ${gen(d.fun)}(${d.fun.params.map(gen).join(", ")}) {`)
d.fun.body.forEach(gen)
output.push("}")
},
Variable(v) {
// Standard library constants get special treatment
if (v === standardLibrary.π) return "Math.PI"
return targetName(v)
},
Function(f) {
return targetName(f)
},
Increment(s) {
output.push(`${gen(s.variable)}++;`)
},
Decrement(s) {
output.push(`${gen(s.variable)}--;`)
},
Assignment(s) {
output.push(`${gen(s.target)} = ${gen(s.source)};`)
},
BreakStatement(s) {
output.push("break;")
},
ReturnStatement(s) {
output.push(`return ${gen(s.expression)};`)
},
ShortReturnStatement(s) {
output.push("return;")
},
IfStatement(s) {
output.push(`if (${gen(s.test)}) {`)
s.consequent.forEach(gen)
if (s.alternate?.kind?.endsWith?.("IfStatement")) {
output.push("} else")
gen(s.alternate)
} else {
output.push("} else {")
s.alternate.forEach(gen)
output.push("}")
}
},
ShortIfStatement(s) {
output.push(`if (${gen(s.test)}) {`)
s.consequent.forEach(gen)
output.push("}")
},
WhileStatement(s) {
output.push(`while (${gen(s.test)}) {`)
s.body.forEach(gen)
output.push("}")
},
RepeatStatement(s) {
// JS can only repeat n times if you give it a counter variable!
const i = targetName({ name: "i" })
output.push(`for (let ${i} = 0; ${i} < ${gen(s.count)}; ${i}++) {`)
s.body.forEach(gen)
output.push("}")
},
ForRangeStatement(s) {
const i = targetName(s.iterator)
const op = s.op === "..." ? "<=" : "<"
output.push(`for (let ${i} = ${gen(s.low)}; ${i} ${op} ${gen(s.high)}; ${i}++) {`)
s.body.forEach(gen)
output.push("}")
},
ForStatement(s) {
output.push(`for (let ${gen(s.iterator)} of ${gen(s.collection)}) {`)
s.body.forEach(gen)
output.push("}")
},
Conditional(e) {
return `((${gen(e.test)}) ? (${gen(e.consequent)}) : (${gen(e.alternate)}))`
},
BinaryExpression(e) {
if (e.op === "hypot") return `Math.hypot(${gen(e.left)},${gen(e.right)})`
const op = { "==": "===", "!=": "!==" }[e.op] ?? e.op
return `(${gen(e.left)} ${op} ${gen(e.right)})`
},
UnaryExpression(e) {
const operand = gen(e.operand)
if (e.op === "some") return operand
if (e.op === "#") return `${operand}.length`
if (e.op === "random") return `((a=>a[~~(Math.random()*a.length)])(${operand}))`
if (e.op === "codepoints") return `[...(${operand})].map(s=>s.codePointAt(0))`
if (e.op === "bytes") return `[...Buffer.from(${operand}, "utf8")]`
if (e.op === "sqrt") return `Math.sqrt(${operand})`
if (e.op === "sin") return `Math.sin(${operand})`
if (e.op === "cos") return `Math.cos(${operand})`
if (e.op === "exp") return `Math.exp(${operand})`
if (e.op === "ln") return `Math.log(${operand})`
return `${e.op}(${operand})`
},
EmptyOptional(e) {
return "undefined"
},
SubscriptExpression(e) {
return `${gen(e.array)}[${gen(e.index)}]`
},
ArrayExpression(e) {
return `[${e.elements.map(gen).join(",")}]`
},
EmptyArray(e) {
return "[]"
},
MemberExpression(e) {
const object = gen(e.object)
const field = JSON.stringify(gen(e.field))
const chain = e.op === "." ? "" : e.op
return `(${object}${chain}[${field}])`
},
FunctionCall(c) {
const targetCode = `${gen(c.callee)}(${c.args.map(gen).join(", ")})`
// Calls in expressions vs in statements are handled differently
if (c.callee.type.returnType !== voidType) {
return targetCode
}
output.push(`${targetCode};`)
},
ConstructorCall(c) {
return `new ${gen(c.callee)}(${c.args.map(gen).join(", ")})`
},
Print(s) {
output.push(`console.log(${s.args.map(gen).join(", ")});`)
},
}
gen(program)
return output.join("\n")
}
Wait was that a real code generator?
Perhaps you expected that we would first generate some kind of intermediate code, and then do code generation to a register-based machine like an x86 or MIPS, with all that flow analysis, static single assignment stuff, graph coloring for register allocation, and pipeline analysis.Well no, not today. When your compiler targets and existing language like JavaScript or C, you can simply rely on the fact that the authors of the JavaScript and C compiler did that work already. Alternatively, just output LLVM IR. It's more work, but there are advantages to doing so.
At this point:
- Fill in test/generator.test.js
- Fill in src/generator.js.
- Run
npm testand make sure we’ve satisfied the tests we wrote earlier. You should be at or near 100% test coverage. - Run
node src/carlos.js examples/gcd.carlos jsand make sure the output looks good.
Now we can finish the compiler test
Remember the compiler test we started at the beginning of this module, in which we added a placeholder-test? It’s time to fully test that compile function:
import { describe, it } from "node:test"
import assert from "node:assert/strict"
import compile from "../src/compiler.js"
const sampleProgram = "print(0);"
describe("The compiler", () => {
it("throws when the output type is missing", () => {
assert.throws(() => compile(sampleProgram), /Unknown output type/)
})
it("throws when the output type is unknown", () => {
assert.throws(() => compile(sampleProgram, "no such type"), /Unknown output type/)
})
it("accepts the parsed option", () => {
const compiled = compile(sampleProgram, "parsed")
assert(compiled.startsWith("Syntax is ok"))
})
it("accepts the analyzed option", () => {
const compiled = compile(sampleProgram, "analyzed")
assert(compiled.kind === "Program")
})
it("accepts the optimized option", () => {
const compiled = compile(sampleProgram, "optimized")
assert(compiled.kind === "Program")
})
it("generates js code when given the js option", () => {
const compiled = compile(sampleProgram, "js")
assert(compiled.startsWith("console.log(0)"))
})
})
At this point:
- Fill in test/compiler.test.js
- Run
npm testand make sure we’ve satisfied the tests we wrote earlier. You should be at 100% coverage. - git add, commit, and push.
- Celebrate!
Thanks!
Thanks for reading, and be sure to check out the entire project on GitHub.
You might feel like adding some new features to the Carlos language. Or enhancing the compiler. Or using it as a basis for a language you design and implement yourself.