Mutual Exclusion
Background
Mutually exclusive access to shared data is required to avoid problematic race conditions. What is meant by this? How can we make it happen?
A proper solution has these requirements:
- No more than one thread can be in its critical section at any one time.
- A thread which dies in its non-critical section will not affect the others’ ability to continue.
- No deadlock or starvation: if a thread wants to enter its critical section then it will eventually be allowed to do so.
- Threads are not forced into lock-step execution of their critical sections.
Approaches:
Bare Machine Techniques
Techniques that work in the absence of help from a scheduler.
Scheduler-Assisted Techniques
Techniques that rely on an scheduler (usually part of the operating system) to block threads until a resource is free.
Bare Machine Approaches
In most cases, a single one-word variable can be read or written atomically. To share such a variable between threads you just have to guarantee the value really is in memory, and not optimized into a register. In Java, C, and other languages, you just have to mark the variable volatile.
Reads and writes on multi-word variables (like long and double in Java) are not guaranteed to be atomic. What then?
The Wrong Way
A naive solution, which does not work, is the following:
while (something) {
if (!inUse) { // Line 2
inUse = true; // Line 3
doSomethingWithTheSharedResource();
inUse = false;
} else {
doSomethingElse();
}
}
There is no mutual exclusion here! Two threads, $A$ and $B$, might suffer this interleaving: $A2$ $B2$ $A3$ $B3$, etc. Now both are executing their critical sections at the same time.
Atomic Test and Set
To fix the problem above the test (line 2) and the set (line 3) have to be atomic! On many hardware architectures there exists an atomic testAndSet instruction. It examines a variable and if it is false, it sets it to true and returns true. Otherwise it leaves the variable true and returns false. This is all done as a single atomic hardware instruction. With it we could write:
while (something) {
if (atomicTestAndSet(&inUse)) {
doSomethingWithTheSharedResource();
inUse = false;
} else {
doSomethingElse();
}
}
Other Atomic Operations
Sometimes with advanced hardware, or with support from an operating system, larger words of memory can be protected with a very simple function. For examples see:
- The many functions with
Interlockedin their name in the Windows API winnt module. - The entire Java package java.util.concurrent.atomic.
Peterson’s Algorithm
If you don’t have a hardware atomic test and set, then enforcing mutual exclusion on a bare machine that meets all the requirements above takes a fair amount of work.
// Thread 0
claim0 = false;
while (true) {
claim0 = true;
turn = 1;
while (claim1 && turn != 0) {}
// CRITICAL SECTION
claim0 = false;
// NON_CRITICAL_SECTION
}
// Thread 1
claim1 = false;
while (true) {
claim1 = true;
turn = 0;
while (claim0 && turn != 1) {}
// CRITICAL SECTION
claim1 = false;
// NON_CRITICAL_SECTION
}
It works, but not without serious drawbacks, namely:
- It’s wordy and complex
- It burns CPU cycles while waiting
- It doesn’t directly scale up to more than two processors
Bakery Algorithm
The bakery algorithm works for multiple threads on a bare machine.
Scheduler-Assisted Mutual Exclusion
In modern operating systems, threads that want to enter a critical section but cannot can be blocked by the operating system so that they are not wasting processor time. The operating system also has facilities to unblock threads.
Mutual exclusion with blocking is achieved primarily through locking mechanisms such as mutexes, semaphores, or futexes. (Note that barriers, phasers, latches, and exchangers are used for other synchronization tasks and not specifically designed for mutual exclusion, so are not considered on this page.)
Mutexes
A mutex is a lock that a thread tries to acquire, and if it does, it proceeds through its critical section then releases the lock. If another thread has acquired the lock, any other thread requesting it must block, guaranteeing mutual exclusion. In pseudocode:
var lock = new Mutex();
// ...
lock.acquire();
// CRITICAL SECTION
lock.release();
// ...
To avoid a thread dying with a lock, you’re more likely to see locks used like this:
var lock = new Mutex();
// ...
try {
lock.acquire();
// CRITICAL SECTION
} finally {
lock.release();
}
// ...
Responsibility of proper use of locks is distributed among all the threads; one malicious or buggy thread could:
- Forget to
acquirebefore entering its critical section, and violate mutual exclusion. - Forget to
releasewhen done, causing the other threads to block forever.
An important property of mutexes is that they can only be unlocked by the thread that locked them. This prevents a thread from unlocking a mutex that it does not own, which can be problematic.
Semaphores
Semaphores are used when up to $N$ threads can use a resource. (A mutex is designed to only allow one thread at a time). They are generally used in a similar fashion to mutexes:
var s = new Semaphore(MAX, true);
// ...
try {
s.acquire();
// CRITICAL SECTION
} finally {
s.release();
}
// ...
The idea is that the thread will block on the semaphore if the maximum number of threads have already successfully acquired. When a thread releases, then one of the block threads will wake up from its acquisition request.
The internal implementation is something like this:
Semaphore(max, fifo)- Creates a new semaphore with the given maximum value and fifo flag. If
fifeis true, threads block in a FIFO queue so a release always wakes the one blocked the longest; otherwise releasing wakes an arbitrary blocked thread. s.acquire()atomically { if (s.value > 0) { s.value--; } else { block on s } }s.release()atomically { if (there are threads blocked on s) { wake one of them } else if (s.value == s.MAX) { fail } else { s.value++ } }
Unlike mutexes, a semaphore may be released by a thread other than its owner.
Like mutexes, semaphores must be managed carefully. You should not forget to acquire or release. Since this might be hard to remember, many programming languages provide a syntactic construct to help with this.
Implicit Locks
How about a statement that automatically locks and unlocks?
Java has a synchronized statement. Here’s an example:
synchronized (someObject) { // CRITICAL SECTION }
In C#, this is:
lock (lockObject) { // CRITICAL SECTION }
In Python, this is:
with lock: # CRITICAL SECTION
These constructs all guarantee release, even if a failure occurs in the critical section.
Now when the data to be protected is a complex object of some sort, an even higher level of syntactic support for mutual exclusion can be crafted. We’d like resources to protect themselves.
Resource Protection
A simple way to put the resource itself in charge of the protection (instead of the threads) is to have a lock associated with every object, like in Java:
public class Account {
private BigDecimal balance = BigDecimal.ZERO;
public synchronized BigDecimal balance() {
return balance;
}
public synchronized void deposit(BigDecimal amount) {
balance = balance.add(amount);
}
}
Every object in Java has an internal “monitor” which a thread can lock and unlock. Only one thread at a time can hold a monitor’s lock. A synchronized method or synchronized statement does an implicit lock at the beginning and an unlock at the end. An attempt to lock a monitor that is already locked causes the thread to wait until the lock is free (unless the lock owner itself is trying to lock again).
By making the account responsible for managing its own synchronization we free the gazillions of threads that wish to use accounts from having to remember to lock and unlock themselves!
Java synchronized methods are syntactic sugarMarking a method synchronized is shorthand for wrapping the whole method body in a
synchronizedstatement, for example:synchronized (this) { // method body }
Notification
Simply using the synchronized keyword might not be sufficient. Consider a message board where threads can post messages and other threads can take them out. The message buffer has a fixed, bounded size. Adds can only be done when the buffer isn’t full, and removes when not empty. The following seems reasonable, but is deeply flawed:
public class ImproperlySynchronizedBuffer { private Object[] data; private int head = 0; private int tail = 0; private int count = 0; public ImproperlySynchronizedBuffer(int capacity) { data = new Object[capacity]; } public synchronized boolean add(Object item) { if (count < data.length) { data[tail] = item; tail = (tail + 1) % data.length; count++; return true; } return false; } public synchronized Object remove() { if (count > 0) { Object item = data[head]; head = (head + 1) % data.length; count--; return item; } return null; } public synchronized int count() { return count; } }
Marking the methods synchronized will prevent race conditions where two threads may simultaneously find the queue with one free slot then both add. However, suppose a queue wants to add and finds the queue full. It will return false, and the thread will have to try again later. But what if another thread removes an item? The first thread will never know that it can now add an item! It will just keep trying and trying, busy waiting, wasting CPU cycles. Horrifying!
We want the threads to just go to sleep until some other thread makes room (in the wants-to-add case) or puts something in (in the wants-to-remove case). Here’s how it is done in Java:
public class SynchronizedBuffer { private Object[] data; private int head = 0; private int tail = 0; private int count = 0; public SynchronizedBuffer(int capacity) { data = new Object[capacity]; } public synchronized void add(Object item) throws InterruptedException { while (count == data.length) wait(); data[tail] = item; tail = (tail + 1) % data.length; count++; notifyAll(); } public synchronized Object remove() throws InterruptedException { while (count == 0) wait(); Object item = data[head]; head = (head + 1) % data.length; count--; notifyAll(); return item; } public synchronized int count() { return count; } }
wait() moves a thread into the object’s wait set, blocking the thread, and notifyAll removes all the threads in the object’s wait set, making them runnable again.
This makes the buffer a blocking queue, which is pretty nice; the API for it is quite clean. But, doing things this way in Java still leaves room for improvement: all threads here are waiting on the buffer object only, we’re not distinguishing between threads waiting for "not full" and those waiting for "not empty".
private Object notFull = new Object();
private Object notEmpty = new Object();
and then rewrote the body of add like this:
synchronized (notFull) {
while (count == data.length) notFull.wait();
}
data[tail] = item;
tail = (tail + 1) % data.length;
count++;
synchronized (notEmpty) {notEmpty.notifyAll();}
and made similar changes to remove(). Does this work? If so, is it better than the previous version? How? If not, how does it fail? (Describe any race conditions, deadlock or starvation in detail.)
By the way, Java does have its own blocking queue class, but you wanted to learn about wait and notifyAll, right?
Ada Protected Objects
Ada’s protected objects are like monitors but a bit more sophisticated—most everything you normally do in these cases is taken care of declaratively! Here is the bounded buffer example. Assume that Index was previously defined as a modular type and Item was defined as the type of objects to be stored in a buffer.
protected type Buffer is -- SPECIFICATION entry Put(I: Item); -- entry Get(I: out Item); -- Public part specifies: function Size return Natural; -- entries, procedures, functions private Data: array (Index) of Item; -- Private part holds the shared Head, Tail: Index := 0; -- data (this is in the spec so Count: Natural := 0; -- the compiler knows how much space end Buffer; -- to allocate for an object) protected body Buffer is -- BODY (operation bodies ONLY; no data) entry Put(I: Item) when Count < Index'Modulus is begin Data(Tail) := I; Count := Count + 1; Tail := Tail + 1; end Put; entry Get(I: out Item) when Count > 0 is begin I := Data(Head); Count := Count - 1; Head := Head + 1; end Get; function Size return Natural is return Count; end Size; end Buffer;
How it works:
- Entries, procedures and functions by definition provide mutually exclusive access.
- Entries and procedures can read and write shared data; functions can only read. Thus, an implementation can optimize by allowing multiple function calls at the same time.
- Only entries have barriers. There is a queue
associated with each entry "inside" the object.
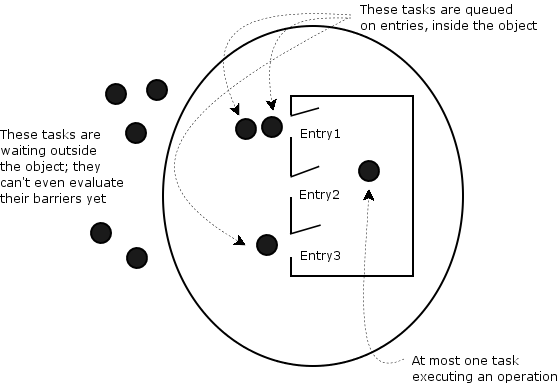
- When an entry is called the barrier is evaluated. If false, the calling task is queued on the entry.
- At the end of a procedure or entry body, barriers are reevaluated.
- Tasks already queued on entries have priority over tasks trying to get in. Therefore a caller can not even evaluate a barrier until the protected object is finished with the current and all queued tasks.
It’s the programmer’s responsibility to see that all barriers execute quickly and don’t call a potentially blocking operation!
Advantages of protected objects (please read the Ada 95 Rationale section on protected types):
- Scalability
- Adaptability
- Modularity
- Efficiency
- Expressiveness
- Compatibility
- Great for implementing interrupt handlers
Explicit vs. Implicit Locking
Data oriented (implicit) locking seems amazing! But explicit locking isn’t really evil, is it? If it were, we’d never see it, right? It must be okay, then. In fact, if it’s the case that you want:
- the flexibility to acquire and release a lock at any time
- to let an object hold multiple locks
- a lock scope to span multiple methods
- to lock a group of objects
then the code might be clearer with explicit locks.
Java has quite a few locks and lock-like classes, including phasers and exchangers. One of the advantages of explicit locks in Java over the synchronized statement is that a finally clause can be used to clean up data that might be in an inconsistent state if an exception were thrown in the critical section.
Related Topics
Mutual exclusion can be considered part of the larger topic of synchronization. Mutual exclusion deals specifically with coordinating access to critical sections. There are other synchronization devices:
- Barriers, which allow threads to wait until all have reached a certain point in their execution.
- Countdown latches, which allow one or more threads to wait until a certain number of events have occurred.
- Phasers, which allow threads to synchronize at multiple points in their execution.
- Exchangers, which allow two threads to exchange data at a certain point in their execution.
- Futures, which represent the result of a computation that may not have completed yet.
While not strictly devices for mutual exclusion, these are sometimes used to coordinate threads in a system so that they end up not making a mess of things.
Sometimes the difference between mutual exclusion and synchronization can be kind of blurry.
Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- What is mutual exclusion? A property of concurrent systems in which threads have exclusive access to resources.
- Why is mutual exclusion needed? To prevent resource conflicts and ensure data integrity in concurrent systems.
- What are some bare machine approaches to mutual exclusion? Atomic test-and-set, Peterson's algorithm, the Bakery algorithm, and Dekker’s algorithm.
- What are some approaches that embrace locking? Mutexes and semaphores.
- What are the two major differences between mutexes and semaphores? Mutexes allow only one thread to access a resource at a time, while semaphores can allow multiple threads up to a specified limit. Also, mutexes can only be released by the thread that acquired them, while semaphores can be released by any thread.
- What is implicit locking? A technique where the locking mechanism is built into the language or framework, such as Java's synchronized methods or Ada's protected objects.
- What statement-level constructs are used in Java, C#, and Python for managing locks in the syntax? Java uses the
synchronizedstatement, C# uses thelockstatement, and Python uses thewithstatement. - What is condition synchronization and notification? A mechanism that allows threads to wait for certain conditions to be met before proceeding.
- What are Ada protected objects? Objects that encapsulate shared data and operations inteded to implement mutual exclusion and condition synchronization.
- What are some synchronization devices that are not designed for mutual exclusion specifically but are often studied in the context of threads? Barriers, countdown latches, phasers, exchangers, and futures.
Summary
We’ve covered:
- What mutual exclusion is and why it is needed
- Bare machine approaches
- Approaches that embrace locking
- Mutexes vs semaphores
- Implicit locking
- Resource protection
- Condition synchronization and notification
- Ada protected objects
- Synchronization devices that are related to mutual exclusion