Here are some long-form exercises for you to work on to improve understanding and retention of course content. Short-form recall questions, designed to be part of your spaced-repetition learning regimen, can be found at the bottom of each page of course notes.
Many of these practice problems will refer to a “Worker Database” in which we want to capture:
- A set of people, known by their name and the street and city of their primary residence.
- A set of companies, and the cities in which their offices are located.
- Information about which people work at which company offices, and which people manage whom. People can work at zero or more companies and can have zero or more managers.
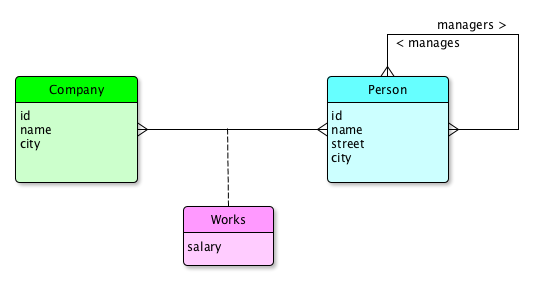
- Consider a representation of the Worker Database with four relations having the following attributes:
- person (id, name, street, city)
- company (id, name, city)
- works (person_id, company_id, salary)
- manages (manager_id, employee_id)
- For the relations in the preceding problem, write SQL to create a new database called workers, connect to it, then define each of the relations in the new database. Use sensible not null and foreign key constraints. State which dialect (Postgres, MySQL, Oracle, etc.) you have chosen.
-- Postgres drop database if exists workers; create database workers; \c workers; create table person (id serial primary key, name varchar not null, street varchar, city varchar); create table company (id serial primary key, name varchar not null, city varchar); create table works (person_id int not null, company_id int not null, salary decimal(16, 2), primary key(person_id, company_id), foreign key(person_id) references person(id), foreign key(company_id) references company(id)); create table manages (manager_id int not null, employee_id int not null, primary key(manager_id, employee_id), foreign key(manager_id) references person(id), foreign key(employee_id) references person(id));
- For the relations in the preceding problem, give a script to populate the database with about a dozen people, a dozen companies, and relations that highlight the fact that the working and managing relations are indeed many-to-many.
insert into person (name, street, city) values ('Mari', 'Third', 'Los Angeles'), ('Karen', 'Sunset', 'West Hollywood'), ('Ellie', 'Hollywood', 'Los Angeles'), ('Gwen', 'Qianmen', 'Beijing'), ('Emily', 'Melrose', 'Los Angeles'), ('Joey', 'Beverly', 'Los Angeles'), ('Ivan', 'Rodeo', 'Los Angeles'), ('Jie', 'La Brea', 'Inglewood'), ('Hiro', 'Wilton', 'Beverly Hills'), ('Sipho', 'Sixth', 'Los Angeles'), ('Luiza', 'Xidan', 'Beijing'), ('Kameke', 'Park', 'New York'), ('Kimiko', 'Yonge', 'Toronto'), ('Olivia', 'Xidan', 'Beijing'); insert into company (name, city) values ('Criteo', 'Paris'), ('Fandango', 'Santa Monica'), ('Tsujita', 'Los Angeles'), ('Bernini', 'Beverly Hills'), ('Riot', 'Los Angeles'), ('Google', 'Mountain View'), ('Google', 'Venice'), ('IBM', 'San Jose'), ('Snapchat', 'Santa Monica'), ('Sony', 'Culver City'), ('Sony', 'Tokyo'), ('Criteo', 'São Paulo'), ('Criteo', 'Dubai'); insert into works (person_id, company_id, salary) values (1, 5, 125572.27), (1, 8, 130000), (2, 1, 93250), (3, 3, 75000), (4, 3, 25000), (5, 1, 450000), (5, 7, 200000), (8, 3, 23350), (8, 8, 85750.10), (9, 7, 115000), (10, 9, 132700), (11, 13, 310000), (13, 10, 89925), (13, 11, 118000), (14, 13, 400000); insert into manages values (3, 4), (3, 8), (5, 2), (9, 5), (1, 8), (11, 1), (11, 14); - For the relations in the preceding problem, write SQL queries (in the dialect of your choice) for:
- The names of people that live in Los Angeles.
select p.name from person p where p.city='Los Angeles';
- The names, streets, and cities of all people living in Beijing or West Hollywood.
select p.name, p.street, p.city from person p where p.city in ('Beijing', 'West Hollywood'); - The names, streets, and cities of all people living in Beijing or West Hollywood, sorted by name.
select p.name, p.street, p.city from person p where p.city in ('Beijing', 'West Hollywood') order by p.name; - The city name, together with the number of residents that we know of.
select p.city, count(p.id) from person p group by p.city;
- The city name, together with the number of residents that we know of, for each city having more than one known resident. Order by the number of residents descending. Label the count column number_of_residents.
select p.city, count(p.id) as number_of_residents from person p group by p.city having count(p.id) > 1 order by number_of_residents desc;
- Each company name together with the number of offices (locations) it has, sorted by company name.
select c.name, count(c.name) as number_of_locations from company c group by c.name order by c.name;
- The names and cities of all Tsujita employees.
select p.name, p.city from person p join works w on p.id=w.person_id join company c on c.id=w.company_id where c.name='Tsujita';
- The names, addresses (combine the street and city into a single column called address), and salaries of all Tsujita employees earning under 50K per year at a Tsujita location.
select p.name, p.street || ', ' || p.city as address, w.salary from person p join works w on p.id=w.person_id join company c on c.id=w.company_id where c.name='Tsujita' and w.salary < 50000;
- All people who live in the same city in which they work (in at least one of their jobs). Display the person’s name, the city, and the company name.
select p.name as employee_name, p.city, c.name as company_name from person p join works w on p.id=w.person_id join company c on c.id=w.company_id where p.city=c.city;
- All people who live on the same street and city as one of their managers.
select e.name as employee, m.name as manager, e.street, e.city from person e join manages r on e.id=r.employee_id join person m on m.id=r.manager_id where e.street=m.street and e.city=m.city;
- The names of people that work at no company (at least none we are aware of).
select p.name from person p where p.id not in ( select person_id from works );
- All people who do not work for Tsujita (at all).
select p.name from person p where p.id not in ( select p.id from person p join works w on p.id=w.person_id join company c on c.id=w.company_id where c.name = 'Tsujita' );
- All people who have a salary that is more than everyone’s IBM salary.
select p.name, w.salary from person p join works w on p.id=w.person_id where w.salary > ( select max(w.salary) from works w join company c on w.company_id=c.id and c.name='IBM' );
- All people and their total salaries. If a person doesn’t have any known jobs, enter them in the result with 0. Order the result by total salary (label the field total_salary) descending.
select p.name, coalesce(sum(w.salary), 0) as total_salary from person p left join works w on p.id=w.person_id group by p.name order by total_salary desc;
- All companies together with their number of employees at each location. List the company name, city, and number of employees. Order by company name, and within each company, order by location name. Include locations with 0 employees.
select c.name, c.city, count(p.id) from company c left join works w on c.id=w.company_id left join person p on p.id=w.person_id group by c.name, c.city order by c.name, c.city;
- All companies located in every city in which Riot is located.
select distinct c.name from company c where not exists ( (select city from company where name='Riot') except (select c1.city from company c1 where c.name=c1.name));
- Each person together with the number of people the person directly manages.
select p.name, count(*) as direct_reports from person p join manages m on p.id=m.manager_id group by p.name;
- Each person together with the number of people the person directly or indirectly manages.
- All people whose manager has a manager (show the names of all three people in this ternary relationship).
select e.name as employee, m.name as middle, b.name as boss from person e join manages m1 on e.id=m1.employee_id join person m on m1.manager_id=m.id join manages m2 on m.id=m2.employee_id join person b on m2.manager_id=b.id;
- Each person together with number of places the person works at, sorted by the number of work locations descending, then the person name ascending.
- Each city and the average salary for all residents of that city.
select p.city, avg(w.salary) from person p join works w on p.id=w.person_id group by p.city
- The company location with the most employees, together with the count.
select c.name, c.city, count(*) from company c join works w on c.id=w.company_id group by c.name, c.city order by 3 desc limit 1;
- The company with the most employees across all of its locations, together with the count.
select c.name, count(*) from company c join works w on c.id=w.company_id group by c.name order by 2 desc limit 1;
- All companies with their total payroll, minium salary, maximum salary, average salary, and number of workers across all of its locations.
select c.name, sum(w.salary) as payroll, min(w.salary), max(w.salary), round(avg(w.salary)::decimal, 2) as avg, count(*) as num_workers from company c join works w on c.id=w.company_id group by c.name;
- All companies with a higher average salary than Snapchat’s average salary.
select c.name, round(avg(w.salary)::decimal, 2) as avg from company c join works w on c.id=w.company_id group by c.name having avg(w.salary) > ( select avg(w.salary) from works w where w.company_id in ( select id from company where name='Snapchat' ) );
- The names of people that live in Los Angeles.
- Give relational algebra expressions for each of the queries in the preceding problem.
- Give relational calculus expressions for each of the queries in the preceding problem.
- Build a Neo4j database for the Worker Database.
create (mari: Person {name: 'Mari', street: 'Third', city: 'Los Angeles'}), (karen: Person {name: 'Karen', street: 'Sunset', city: 'West Hollywood'}), (ellie: Person {name: 'Ellie', street: 'Hollywood', city: 'Los Angeles'}), (gwen: Person {name: 'Gwen', street: 'Qianmen', city: 'Beijing'}), (emily: Person {name: 'Emily', street: 'Melrose', city: 'Los Angeles'}), (joey: Person {name: 'Joey', street: 'Beverly', city: 'Los Angeles'}), (ivan: Person {name: 'Ivan', street: 'Rodeo', city: 'Los Angeles'}), (jie: Person {name: 'Jie', street: 'La Brea', city: 'Inglewood'}), (hiro: Person {name: 'Hiro', street: 'Wilton', city: 'Beverly Hills'}), (sipho: Person {name: 'Sipho', street: 'Sixth', city: 'Los Angeles'}), (luiza: Person {name: 'Luiza', street: 'Xidan', city: 'Beijing'}), (kameke: Person {name: 'Kameke', street: 'Park', city: 'New York'}), (kimiko: Person {name: 'Kimiko', street: 'Yonge', city: 'Toronto'}), (olivia: Person {name: 'Olivia', street: 'Xidan', city: 'Beijing'}), (criteo_p: Company {name: 'Criteo', city: 'Paris'}), (fandango_s: Company {name: 'Fandango', city: 'Santa Monica'}), (tsujita_l: Company {name: 'Tsujita', city: 'Los Angeles'}), (bernini_b: Company {name: 'Bernini', city: 'Beverly Hills'}), (riot_l: Company {name: 'Riot', city: 'Los Angeles'}), (google_m: Company {name: 'Google', city: 'Mountain View'}), (google_v: Company {name: 'Google', city: 'Venice'}), (ibm_s: Company {name: 'IBM', city: 'San Jose'}), (snapchat_s: Company {name: 'Snapchat', city: 'Santa Monica'}), (sony_c: Company {name: 'Sony', city: 'Culver City'}), (sony_t: Company {name: 'Sony', city: 'Tokyo'}), (criteo_s: Company {name: 'Criteo', city: 'São Paulo'}), (criteo_d: Company {name: 'Criteo', city: 'Dubai'}), (mari)-[:WORKS {salary: 125572.27}]->(riot_l), (mari)-[:WORKS {salary: 130000.00}]->(ibm_s), (karen)-[:WORKS {salary: 93250.00}]->(criteo_p), (ellie)-[:WORKS {salary: 75000.00}]->(tsujita_l), (gwen)-[:WORKS {salary: 25000.00}]->(tsujita_l), (emily)-[:WORKS {salary: 450000.00}]->(criteo_p), (emily)-[:WORKS {salary: 200000.00}]->(google_v), (jie)-[:WORKS {salary: 23350.00}]->(tsujita_l), (jie)-[:WORKS {salary: 85750.10}]->(ibm_s), (hiro)-[:WORKS {salary: 115000.00}]->(google_v), (sipho)-[:WORKS {salary: 132700.00}]->(snapchat_s), (luiza)-[:WORKS {salary: 310000.00}]->(criteo_d), (kimiko)-[:WORKS {salary: 89925.00}]->(sony_c), (kimiko)-[:WORKS {salary: 118000.00}]->(sony_t), (olivia)-[:WORKS {salary: 400000.00}]->(criteo_d), (ellie)-[:MANAGES]->(gwen), (ellie)-[:MANAGES]->(jie), (emily)-[:MANAGES]->(karen), (hiro)-[:MANAGES]->(emily), (mari)-[:MANAGES]->(jie), (luiza)-[:MANAGES]->(mari), (luiza)-[:MANAGES]->(olivia); - For the Neo database in the preceding problem, give Cypher queries for:
- The names of people that live in Los Angeles.
match (p:Person {city: 'Los Angeles'}) return p.name; - The names, streets, and cities of all people living in Beijing or West Hollywood.
match (p:Person) where p.city in ['Beijing', 'West Hollywood'] return p.name;
- The names, streets, and cities of all people living in Beijing or West Hollywood, sorted by name.
match (p:Person) where p.city in ['Beijing', 'West Hollywood'] return p.name order by p.name;
- The city name, together with the number of residents that we know of.
match (p:Person) return p.city, count(*)
- The city name, together with the number of residents that we know of, for each city having more than one known resident. Order by the number of residents descending. Label the count column number_of_residents.
match (p:Person) with p.city as city, count(*) as number_of_residents where number_of_residents > 1 return city, number_of_residents order by number_of_residents desc
- Each company name together with the number of offices (locations) it has, sorted by company name.
match (c:Company) return c.name, count(c.city) order by c.name
- The names and cities of all Tsujita employees.
match (p:Person)-[:WORKS]->(:Company {name: 'Tsujita'}) return p.name, p.city - The names, addresses (combine the street and city into a single property called address), and salaries of all Tsujita employees earning under 50K per year at a Tsujita location.
match (p:Person)-[w: WORKS]->(:Company {name: 'Tsujita'}) where w.salary < 50000 return p.name, (p.street + ", " + p.city) as address, w.salary - All people who live in the same city in which they work (in at least one of their jobs). Display the person’s name, the city, and the company name.
match (p:Person)-[:WORKS]->(c:Company) where p.city = c.city return p.name, p.city, c.name
- All people who live on the same street and city as one of their managers.
match (e:Person)<-[:MANAGES]-(m:Person) where e.city = m.city AND e.street = m.street return e, m
- The names of people that work at no company (at least none we are aware of).
match (p:Person) where not exists((p)-[:WORKS]->(:Company)) return p
- All people who do not work for Tsujita (at all).
match (p:Person) where not exists((p)-[:WORKS]->(:Company {name: 'Tsujita'})) return p - All people who have a salary that is more than everyone’s IBM salary.
- All people and their total salaries. If a person doesn’t have any known jobs, enter them in the result with 0. Order the result by total salary (label the field total_salary) descending.
- All companies together with their number of employees at each location. List the company name, city, and number of employees. Order by company name, and within each company, order by location name. Include locations with 0 employees.
- All companies located in every city in which Riot is located.
- Each person together with the number of people the person directly manages.
match (p:Person)-[r:MANAGES]->(s:Person) return p.name, count(s)
- Each person together with the number of people the person directly or indirectly manages.
match (p:Person)-[r:MANAGES*]->(s:Person) return p.name, count(s)
- All people whose manager has a manager (show the names of all three people in this ternary relationship).
match (boss:Person)-[:MANAGES]->(middle:Person)-[:MANAGES]->(employee:Person) return boss.name as boss, middle.name as middle, employee.name as employee
- Each person together with number of places the person works at, sorted by the number of work locations descending, then the person name ascending.
- Each city and the average salary for all residents of that city.
match (p:Person)-[w:WORKS]->(c:Company) return p.city, avg(w.salary)
- The company location with the most employees, together with the count.
match (p:Person)-[:WORKS]->(c:Company) return c.name, c.city, count(p) as num_employees order by num_employees desc limit 1
- The company with the most employees across all of its locations, together with the count.
match (p:Person)-[:WORKS]->(c:Company) return c.name, count(p) as num_employees order by num_employees desc limit 1
- All companies with their total payroll, minium salary, maximum salary, average salary, and number of workers across all of its locations.
match (p:Person)-[w:WORKS]->(c:Company) return c.name, sum(w.salary) as payroll, min(w.salary), max(w.salary), avg(w.salary) as avg, count(*) as num_workers order by num_employees desc limit 1
- All companies with a higher average salary than Snapchat’s average salary.
- The names of people that live in Los Angeles.
- We can represent our running example database of workers and their companies and managers in a document database using only a single collection. Here’s a sample document:
{ "_id" : ObjectId("59064fa0a3e67042eadf759a"), "name" : "Mari", "street" : "Third", "city" : "Los Angeles", "manages" : [ ObjectId("59064fa0a3e67042eadf75a1") ], "companies" : [ { "name" : "Riot", "city" : "Los Angeles", "salary" : 125572.27 }, { "name" : "IBM", "city" : "San Jose", "salary" : 130000 } ] }Write a JavaScript or Python script to create a Mongo database, and a collection of workers, according to this scheme. Use the same content as in your previous (relation and graph) answers.db.people.insert({name: 'Mari', street: 'Third', city: 'Los Angeles'}); db.people.insert({name: 'Karen', street: 'Sunset', city: 'West Hollywood'}); db.people.insert({name: 'Ellie', street: 'Hollywood', city: 'Los Angeles'}); db.people.insert({name: 'Gwen', street: 'Qianmen', city: 'Beijing'}); db.people.insert({name: 'Emily', street: 'Melrose', city: 'Los Angeles'}); db.people.insert({name: 'Joey', street: 'Beverly', city: 'Los Angeles'}); db.people.insert({name: 'Ivan', street: 'Rodeo', city: 'Los Angeles'}); db.people.insert({name: 'Jie', street: 'La Brea', city: 'Inglewood'}); db.people.insert({name: 'Hiro', street: 'Wilton', city: 'Beverly Hills'}); db.people.insert({name: 'Sipho', street: 'Sixth', city: 'Los Angeles'}); db.people.insert({name: 'Luiza', street: 'Xidan', city: 'Beijing'}); db.people.insert({name: 'Kameke', street: 'Park', city: 'New York'}); db.people.insert({name: 'Kimiko', street: 'Yonge', city: 'Toronto'}); db.people.insert({name: 'Olivia', street: 'Xidan', city: 'Beijing'}); let ids = {}; db.people.find({}).forEach(d => ids[d.name.toLowerCase()] = d._id); db.people.update({name: 'Ellie'}, {$set: {manages: [ids.gwen, ids.jie]}}); db.people.update({name: 'Emily'}, {$set: {manages: [ids.karen]}}); db.people.update({name: 'Hiro'}, {$set: {manages: [ids.emily]}}); db.people.update({name: 'Mari'}, {$set: {manages: [ids.jie]}}); db.people.update({name: 'Luiza'}, {$set: {manages: [ids.mari, ids.olivia]}}); db.people.update({name: 'Mari'}, {$addToSet : {companies: {name: 'Riot', city: 'Los Angeles', salary: 125572.27}}}); db.people.update({name: 'Mari'}, {$addToSet : {companies: {name: 'IBM', city: 'San Jose', salary: 130000}}}); db.people.update({name: 'Karen'}, {$addToSet : {companies: {name: 'Criteo', city: 'Paris', salary: 93250}}}); db.people.update({name: 'Ellie'}, {$addToSet : {companies: {name: 'Tsujita', city: 'Los Angeles', salary: 75000}}}); db.people.update({name: 'Gwen'}, {$addToSet : {companies: {name: 'Tsujita', city: 'Los Angeles', salary: 25000}}}); db.people.update({name: 'Emily'}, {$addToSet : {companies: {name: 'Criteo', city: 'Paris', salary: 450000}}}); db.people.update({name: 'Emily'}, {$addToSet : {companies: {name: 'Google', city: 'Venice', salary: 200000}}}); db.people.update({name: 'Jie'}, {$addToSet : {companies: {name: 'Tsujita', city: 'Los Angeles', salary: 23350}}}); db.people.update({name: 'Jie'}, {$addToSet : {companies: {name: 'IBM', city: 'San Jose', salary: 85750.10}}}); db.people.update({name: 'Hiro'}, {$addToSet : {companies: {name: 'Google', city: 'Venice', salary: 115000}}}); db.people.update({name: 'Sipho'}, {$addToSet : {companies: {name: 'Snapchat', city: 'Santa Monica', salary: 132700}}}); db.people.update({name: 'Luiza'}, {$addToSet : {companies: {name: 'Criteo', city: 'Dubai', salary: 310000}}}); db.people.update({name: 'Kimiko'}, {$addToSet : {companies: {name: 'Sony', city: 'Culver City', salary: 89925}}}); db.people.update({name: 'Kimiko'}, {$addToSet : {companies: {name: 'Sony', city: 'Tokyo', salary: 118000}}}); db.people.update({name: 'Olivia'}, {$addToSet : {companies: {name: 'Criteo', city: 'Dubai', salary: 400000}}}); - Implement these (familiar) queries for this Mongo database.
- The names of people that live in Los Angeles.
db.people.find({city: 'Los Angeles'}, {_id: 0, name: 1}) - The names, streets, and cities of all people living in Beijing or West Hollywood.
db.people.find({city: {$in: ['Beijing', 'West Hollywood']}}, {_id: 0, name: 1, street: 1, city: 1}) - The names, streets, and cities of all people living in Beijing or West Hollywood, sorted by name.
db.people.find({city: {$in: ['Beijing', 'West Hollywood']}}, {_id: 0, name: 1, street: 1, city: 1}).sort({name: 1}) - The city name, together with the number of residents that we know of.
- The city name, together with the number of residents that we know of, for each city having more than one known resident. Order by the number of residents descending. Label the count column number_of_residents.
- Each company name together with the number of offices (locations) it has, sorted by company name.
- The names and cities of all Tsujita employees.
db.people.find({"companies.name": "Tsujita"}, {_id: 0, name: 1, city: 1}); - The names, addresses (combine the street and city into a single column called address), and salaries of all Tsujita employees earning under 50K per year at a Tsujita location.
- All people who live in the same city in which they work (in at least one of their jobs). Display the person’s name, the city, and the company name.
- All people who live on the same street and city as one of their managers.
- The names of people that work at no company (at least none we are aware of).
- All people who do not work for Tsujita (at all).
db.people.find({"companies.name": {$ne: "Tsujita"}}) - All people who have a salary that is more than everyone’s IBM salary.
- All people and their total salaries. If a person doesn’t have any known jobs, enter them in the result with 0. Order the result by total salary (label the field total_salary) descending.
- All companies together with their number of employees at each location. List the company name, city, and number of employees. Order by company name, and within each company, order by location name. Include locations with 0 employees.
- All companies located in every city in which Riot is located.
- Each person together with the number of people the person directly manages.
db.people.aggregate([ {$match: {manages: {$exists: 1}}}, {$project: {name: 1, direct_reports: {$size: "$manages"}}} ]) - Each person together with the number of people the person directly or indirectly manages.
- All people whose manager has a manager (show the names of all three people in this ternary relationship).
- Each person together with number of places the person works at, sorted by the number of work locations descending, then the person name ascending.
- Each city and the average salary for all residents of that city.
db.people.aggregate([ {$unwind: "$companies"}, {$group: {_id: "$city", average_salary: {$avg: "$companies.salary"}}}, ]) - The company location with the most employees, together with the count.
db.people.aggregate([ {$unwind: "$companies"}, {$group: {_id: "$companies.name", num_people: {$sum: 1}}}, {$sort: {num_people: -1}}, {$limit: 1} ]) - The company with the most employees across all of its locations, together with the count.
db.people.aggregate([ {$unwind: "$companies"}, {$group: {_id: "$companies.name", num_people: {$sum: 1}}}, {$sort: {num_people: -1}}, {$limit: 1} ]) - All companies with their total payroll, minium salary, maximum salary, average salary, and number of workers across all of its locations.
db.people.aggregate([ {$unwind: "$companies"}, {$group: { _id: "$companies.name", num_people: {$sum: 1}, payroll: {$sum: "$companies.salary"}, min_salary: {$min: "$companies.salary"}, max_salary: {$max: "companies.salary"}, avg_salary: {$avg: "$companies.salary"} }} ]) - All companies with a higher average salary than Snapchat’s average salary.
- The names of people that live in Los Angeles.