Adversarial Search
Games
Game playing: solving search problems in competitive (usually unpredictable) multi-agent environments.
Simplest games:
- Two player
- Turn taking
- Zero-sum
- Perfect information — deterministic, fully observable
- Have small number of possible actions
- Precise, formal rules
Games are interesting because
- Most are too hard to solve optimally
- Most penalize inefficiency (so search must be fast)
- Many have elements of chance (e.g. dice)
- Many have imperfect information (e.g. opponents cards my be hidden)
Simple classification
| Perfect Information | Imperfect Information | |
|---|---|---|
| Deterministic | Go, Chess, Othello, Kalah, ... | Stratego, ... |
| Non-deterministic | Backgammon, ... | Poker, Scrabble, ... |
Games as search problems
Game has
- initial state — configuration + player to move
- successor function
- terminal test — game over or not
- utility function — maps terminal states to numeric values
Players have to find contigent strategies. An optimal strategy assumes an infallible opponent. Can be found with minimax evaluation.
Minimax Evaluation
Expand the game tree depth first out to a certain number of ply. Evaluate nodes at the fringe, using the utility function if it's a leaf, or a heuristic evaluation function otherwise. (It's okay if there are terminal nodes occuring before the depth limit.) One player (MAX) likes big scores, the other (MIN) likes small scores. Record mins and maxes up the tree as you backtrack.
Minimax gives best results against an optimal opponent.
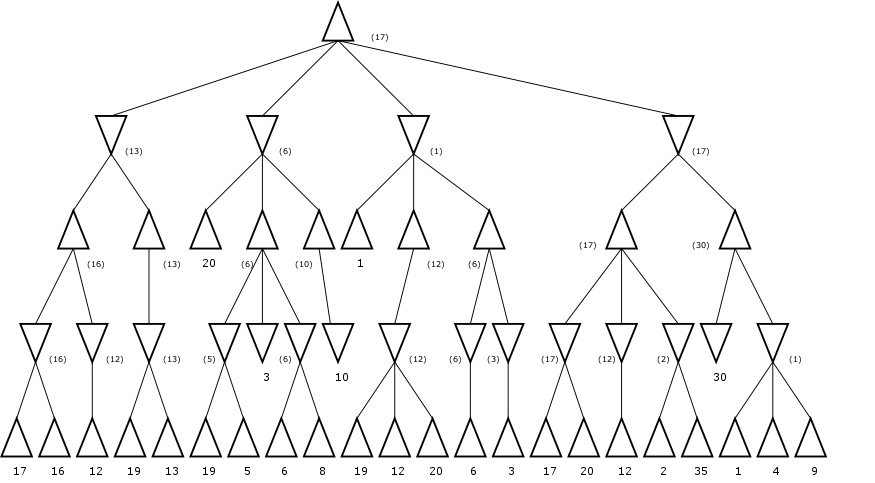
Alpha Beta Pruning
Keep track of, for each node,
- α — highest value found along the path so far
- β — lowest value found along the path so far
Prune as soon as you see something worse than the current α or β. Works the best if you can order successors by how good they are for you; theoretically this can cut run time from Θ(bm) to Θ(bm/2) doubling the search depth that can be explored in a given duration... but still not good enough to completely solve chess.
Search in Practice
Lots of room for cleverness
- Order considerations from best to worst
- Use moves that were found to be the best "last time"
- Avoid repeated states — store in a hash table, usually called a "transposition table"
- But watch out for transposition tables getting to big — store only certain nodes in it
- Adjust the move-ordering schemes dynamically
- For chess, keep "opening book" and massive database of previously played grandmaster games
- Use iterative deepening: this allows searches to be cutoff when time is running short, and to provide hints for move ordering in future iterations!
- Use singular extensions (moves that are obviously way better than others) can help extend the search depth
- Sometimes try forward pruning — just whack whole branches you think aren't promising. (Not optimal, but savings in time might allow deeper exploration of more promising lines.)
Be Careful!
- Don't cutoff too soon (maybe on the next move you lose your queen)
- Evaluation function should be only applied to quiscent positions
- The horizon effect is problematic (singular extensions help here)
If more than two players,
- value of each state is a tuple (v1, v2, ..., vn)
- extension of minimax is fairly obvious.
Other Algorithms
- Negascout (principal variation search) — a form of alpha-beta pruning that is better in the sense that it never examines nodes alpha-beta won't, but it will run slower than plain α-β unless there's a good ordering.
- MTD(f) — theoretically better than Negascout, but has practical issues
- SSS* — a best-first, not depth-first, algorithm (so may have memory issues)
Evaluation Functions
The evaluation function gives an estimate of the utility of a node. A good evaluation function must obviously:
- evaluate terminal nodes perfectly
- run quickly enough
- be really, really close to the actual "chances of winning" for non-terminal nodes
Usually done as a linear weighted combination of features
w1f1(s) + w2f2(s) + ... + wnfn(s)
Examples of features (from Chess)
- Material count
- Good pawn structure
- King safety
- Control of center
- Control of open files
- Mobility
But in reality
- Weights can change during a game
- Combination can be non-linear
Where do the weights and features come from?
- Human game playing experience
- Machine learning (values refined over time, often from playing computer players against each other over and over)
Games of Chance
Game trees have chance nodes. Edges in are moves, edges out are the dice rolls (or equivalent) labeled with the probability of occurrence.
TODOExact values do matter, unlike in deterministic games where only the relative ordering of values mattered.
TODOGames of Imperfect Information
TODOState of the Art
- Checkers — computers always win
- Chess — computers almost always win
- Othello — computers always win
- Go — best computer players still amateurs
- Backgammon — TD-Gammon plays at world-championship level (big reinforcement learning success story, also changed the way the best human players play certain opening positions!)
- Bridge — GIB plays at expert level