Binding
Names, Entities, and Bindings
Programs, are constructed form entities. Entities refer to, store, and manipulate values. Some entities are pure language structures, like declarations, expressions, and statements. Literals are entities that directly represent values. But other entities can be named.
A binding is the attachment of a name to an entity.
| Examples of names | Examples of entities |
|---|---|
|
|
Names allow us to refer to entities.
Note how names can be alphanumeric or symbolic.
Fun fact: In most languages, the set of symbolic names are fixed, but in a few, like Scala, Swift, Haskell, and Standard ML, you can define your own.
Declarations vs. Definitions
A declaration brings a name into existence, but a definition creates an entity and the initial binding.
extern int z; // just a declaration class C; // just a declaration double square(double); // just a declaration void f() { // declaration plus definition together int x; // also a declaration plus definition int y = x + z /square(3); // so is this } double square(double x) { // definition completing earlier declaration return x * x; }
The purpose of a definition-less declaration is to allow the name to used, even though the definition will be somewhere else (in a place you might not even know).
Assignments vs. Bindings
Here is something very tricky but very, very important. What do you think the meaning of the following is?
x ← 3
x ← 5
Is there one entity here? Or two? If you are a language designer, it’s your choice!
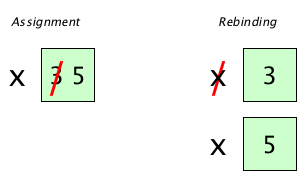
If one, we are changing the value of an entity, which we call assignment, and in which case we call the entity an assignable. (Assignment can be dangerous, because it makes programs harder to reason about. But that’s a different story.)
Here are two languages that do things differently. JavaScript does assignment:
let x = 3 // create entity, value is 3, bind x const f = () => x // f returns value of entity bound to x x = 5 // assignment: replace value of entity f() // ==> 5
And Standard ML does rebinding:
val x = 3; (* create entity, bind to x *) val f = fn () => x; (* f returns value of entity NOW bound to x *) val x = 5; (* COMPLETELY NEW BINDING *) f(); (* ==> 3, because value of original binding *)
Initialization vs. Assignment
Initialization and assignment are very different.
- Initialization creates a variable where none existed before
- Assignment updates the value of an existing variable
One language that makes the distinction explicit in code is C++. Examples:
// C++ Initializations: int x = 10; int y(15); int z(a + 5 / 2); int w(x); Point p(5, 12); Point q = p; // C++ Assignments: x = 12; y = x / 6; q = p; q = midpoint(p1, p2);
Prefer initialization to assignment where possible. Here’s a case where you must. Suppose we had a point class in C++:
class Point { public: int x; int y; Point(int x1, int y1): x(x1), y(y1) {} };
Because we defined a constructor with parameters, we cannot ever define uninitialized points:
Point p; // ILLEGAL Point* p = new Point[10]; // ILLEGAL class Rectangle { public: Point corner1, corner2; Rectangle(Point p, Point q) { // ILLEGAL corner1 = p; corner2 = q; } };
The Rectangle constructor failed because it is trying to initialize the fields to their default values and then assign them in the constructor body.... but there is NO default initializer for class Point. You MUST write the Rectangle constructor like this:
class Rectangle { public: Point corner1, corner2; Rectangle(Point p, Point q): corner1(p), corner2(q) {} };
Polymorphism and Aliasing
Instead of rebinding a name to a new entity, what if we allowed the same name to refer to different entities at the same time? Oooooh. And, and.... turning things around, what if we allowed multiple names to be bound to the same entity at the same time?
We have words for these things:
Polymorphism
Same name bound to multiple entities at the same time
Aliasing
Multiple names bound to the same entity at the same time
And pictures:
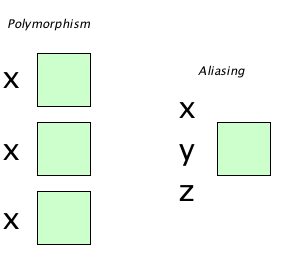
A precise way to say “at the same time” is “within the same referencing environment.” Technically, a referencing environment is the set of bindings in effect at a given point.
Examples of Polymorphism
In a few languages, multiple functions can have the same name at the same time provided their signatures (parameter names, types, orders, etc.), or their receiver class, differs. Check out this C++ example:
bool f(string s) { return s.empty(); } int f(int x, char c) { return x * c; } int main() { cout << f("hello") << '\n'; // 0 cout << f(75, 'w') << '\n'; // 8925 }
Polymorphism is interesting because, when given a name, a program has to find the right entity for the name to use! If the right entity can be determined at compile time, like in the example above, we have static polymorphism. If it can only be determined at run time, we have dynamic polymorphism, like in this Ruby example:
class Animal; end class Dog < Animal; def speak() = 'woof' end class Rat < Animal; def speak() = 'squeak' end class Duck < Animal; def speak() = 'quack' end animals = (1..50).map{[Dog.new, Rat.new, Duck.new].sample} animals.each {|a| puts a.speak}
Here’s another example of dynamic polymorphism, this time in Julia. It may look like static polymorphism, but Julia checks those types at run time:
function f(s::String) reverse(s) end function f(x::Int, y::Char) x * Int(y) end print(f("Hello")) # "olleH" print(f(75, 'π')) # 72000
Evaluating that script in the console shows you Julia has “methods,” a word commonly associated with dynamic lookup (we’ll hear more about this when we cover OOP):
julia> function f(s::String) reverse(s) end
f (generic function with 1 method)
julia> function f(x::Int, y::Char) x * Int(y) end
f (generic function with 2 methods)
julia> f("Hello")
"olleH"
julia> f(75, 'π')
72000

Examples of Aliasing
Aliasing is pretty common in language with explicit pointers:
#include <iostream> using namespace std; int main() { int x = 5; int* p = &x; cout << p << '\n'; // 0x7fff5febb0fc cout << &x << '\n'; // 0x7fff5febb0fc cout << x << '\n'; // 5 cout << *p << '\n'; // 5 }
A pointer is the name of a reference object that has a numeric address that you can manipulate with arithmetic operations. At least, that’s the general definition—different languages tend to tweak the vocabulary.

C++ has explicit aliases! Perhaps unfortunately, they are called references. This is kind of annoying because in basic PL speak, a reference is a value that refers to another value. But C++ does not use the regular terminology. Instead it confuses you by taking a perfectly good term and uses it for what everyone else calls an alias.
#include <iostream> using namespace std; int main() { int x = 5; int& y = x; // x and y refer to the same entity x = 3; cout << x << ' ' << y << '\n'; // 3 3 y = 8; cout << x << ' ' << y << '\n'; // 8 8 }
The picture for this one is easy:
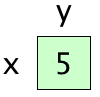
Scope
Bindings have (generally spatial) scope and (temporal) extent. The scope of a binding is the region in a program in which the binding is active. We say scope is “generally” spatial because:
- Most languages employ static scoping (also called lexical scoping), meaning all scopes can be determined at compile time.
- Some languages (APL, Snobol, early LISP) employ dynamic scoping, meaning scopes depend on runtime execution.
- Perl lets you have both, but they suggested you never use dynamic scoping.
Regardless of whether scoping is static or dynamic, the deal is this: when you leave a scope, the binding is deactivated.
Static Scope
Static scoping is determined by the structure of the source code:
┌──────────────────────────────────────────────┐
procedure P │ (X: Integer) is │
┌─────────────┘ │
│ A, B: Integer; │
│ ┌────────────────────────────────────────┐ │
│ procedure Q │ (Y: Integer) is │ │
│ ┌─────────────┘ ┌───────────────────────────────────┐ │ │
│ │ function R │ (X, Y: Integer) return Integer is │ │ │
│ │ ┌────────────┘ ┌───────────────┐ │ │ │
│ │ │ procedure T │ is │ │ │ │
│ │ │ ┌─────────────┘ │ │ │ │
│ │ │ │ T: Integer; │ │ │ │
│ │ │ │ begin │ │ │ │
│ │ │ │ ... │ │ │ │
│ │ │ │ end T; │ │ │ │
│ │ │ └─────────────────────────────┘ │ │ │
│ │ │ W: Float; │ │ │
│ │ │ begin │ │ │
│ │ │ ... │ │ │
│ │ │ end R; │ │ │
│ │ └────────────────────────────────────────────────┘ │ │
│ │ ┌──────────────────────────────────┐ │ │
│ │ procedure S │ (Y: Integer) is │ │ │
│ │ ┌─────────────┘ │ │ │
│ │ │ begin │ │ │
│ │ │ ... │ │ │
│ │ │ end S; │ │ │
│ │ └────────────────────────────────────────────────┘ │ │
│ │ begin │ │
│ │ ... │ │
│ │ declare X: Integer; begin ... end; │ │
│ │ ... │ │
│ │ end Q; │ │
│ └──────────────────────────────────────────────────────┘ │
│ M: Integer; │
│ begin │
│ ... │
│ end P; │
└────────────────────────────────────────────────────────────┘
The general rule is that bindings are determined by finding the “innermost” declaration, searching outward through the enclosing scopes if needed.
Interestingly, not everything is obvious! There are reasonable questions regarding:
- Where exactly the scope of a particular binding begins and ends
- Whether bindings that have been hidden in inner scopes are still accessible
- What actually counts as a declaration versus just a use? Can declarations be implicit?
- The effect of redeclarations within a scope
Scope Range
Where exactly a static scope begins and ends has at least four reasonable possibilities:
- Scope is whole block (like JavaScript
letorconst), or the whole function (like JavaScriptvar) - Scope starts at beginning of declaration (like C)
- Scope starts only after the whole declaration is finished (like Lua)
- Scope starts after declaration is finished, but using occurrences of name are prohibited during declaration (like Ada)
var x = 3
var y = 5
function f() {
print(y)
var x = x + 1
var y = 7
print(x)
}
f()
What is the effect of compiling and running the code under each of the four possibilities above?
Scope Holes
In static scoping, “inner” declarations hide, or shadow outer declarations of the same identifier, causing a hole in the scope of the outer identifier’s binding. But when we’re in the scope of the inner binding, can we still see the outer binding? Sometimes, we can:
In C++:
int x = 1; namespace N { int x = 2; class C { int x = 3; void f() {int x = 4; cout << ::x << N::x << this->x << x << '\n'; } }
In Ada:
procedure P is X: Integer := 1; procedure Q is X: Integer := 2; begin Put(X); -- writes 2 Put(P.X); -- writes 1 end Q; end P;
However, some languages have restrictions on hiding declarations:
void f() { int x = 1; if (true) { int x = 2; } }
is fine in C, but illegal in Java, because Java does not allow more than one declaration of a local variable within a method.
JavaScript has a somewhat interesting take on the interplay of scopes and nested blocks, with very different semantics between declarations introduced with var, const, or let.
var and let in JavaScript, as it pertains to scope. You should run across something called the temporal dead zone (TDZ). Explain the TDZ in your own words.
Indicating Declarations
Generally, languages indicate declarations with a keyword, such as var, val, let, const, my, our, or def. Or sometimes we see a type name, as in:
int x = 5;
or
X: Integer := 3;
When we use these explicit declarations in a local scope, things are pretty easy to figure out, as in this JavaScript example:
let x = 1, y = 2; function f() { let x = 3; // local declaration console.log(x); // uses local x console.log(y); // uses global y, it’s automatically visible } f(); // writes 3 and 2
Easy to understand, for sure, but be super careful, leaving off the declaration keyword in JavaScript updates, and introduces if necessary, a global variable:
let x = 1; function f() { x = 2; // DID YOU FORGET let? } // Updated global variable! Accident or intentional? f() console.log(x);
Forgetting the declaration-introducing keywords has happened in the real world, with very sad consequences.
But in Python, there are no keywords and no types. Declarations are implicit. How does this work?
x = -5 def f(): print(abs(x)) f() # prints 5
Sure enough we can see the globals abs and x inside f. Now consider:
x = -5 def f(): x = 3 f() print(x) # prints -5
Aha, so if we assign to a variable inside a function, that variable is implicitly declared to be a local variable. Now how about:
x = -5 def f(): print(x) x = 3 f() print(x)
This gives UnboundLocalError: local variable 'x' referenced before assignment. The scope of the local x is the whole function body!
Now Ruby’s declarations are also implicit. Let’s see what we can figure out here:
x = 3 def f() = puts x # Error when called! f()
WOAH! NameError: undefined local variable or method `x' for main:Object. We can’t see that outer x inside of f! If we want to play this game, we must use global variables, which in Ruby start with a $:
$x = 3 def f(); x = 5; y = 4; p [$x, x, y] end # writes [3, 5, 4] f()
So assigning to a local declares it, and variables starting with a $ are global.
CoffeeScript also has no explicit declarations. But it has a controversial design. If you assign to a variable inside a function, and that variable does not already have a binding in an outer scope, a new local variable is created. But if an outer binding does exist, you get an assignment to the outer variable.
x = 3 f = () -> x = 5 f() # Plasters the global x console.log(x) # Writes 5 g = () -> y = 8 g() # Defines a local y which then goes away console.log(y) # Throws ReferenceError: y is not defined
WTF? So if I write a little utility function that uses what I think are local variables, then I had better be damn sure that function does not find itself used in a context where it might actually affect global variables?
If an identifier is redeclared within a scope, a language designer can choose to:
- Reject it (as a compile-time or run-time error).
- Make a fresh new binding and retain the old ones.
- Treat the redeclaration like an assignment.
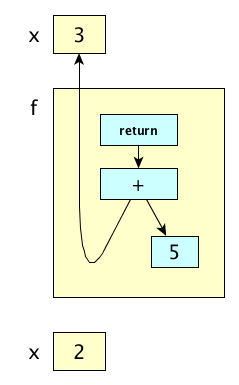
Perl and ML actually retain the old bindings; in other words, redeclarations introduce new entities:
# Perl my $x = 3; # declare $x and bind it sub f {return $x + 5;} # uses the existing binding of $x my $x = 2; # declare a NEW entity and thus a new binding print f(), "\n";
(* SML *) val x = 3; (* declare x and bind it *) fun f() = x + 5; (* uses existing binding of x *) val x = 2; (* declare a NEW entity and thus a new binding *) f();
Both of these programs print 8, because the bindings are new:
But in some languages, the second declaration is really just an assignment, rather than the creation of a new binding. In such a language, the code implementing the above example would print 7, not 8.
Dynamic Scope
With dynamic scoping, the current binding for a name is the one most recently encountered during execution. That is, scope becomes temporal rather than spatial. The following script prints 2, not 1:
# Perl our $x = 1; sub f { print "$x\n"; } sub g { local $x = 2; # `local` makes dynamic scope (use `my` for static) f(); } g(); print "$x\n";
Dynamic scopes tend to require a lot of run time overhead. The runtime system has to keep track of names in a structure that can be searched at run time to find the desired entity. There are two kinds of structures typically used to manage such scoping:
- Association lists
- Central reference tables
We’ll illustrate both with the following example:
// An example in which main calls q, then q calls p.
var i;
var j;
function p(var i) { ... }
function q(var j) {var x; ... p(j); ...}
q();
The association list, or A-list, works like this:
- When entering a scope: push its bindings on the list.
- When leaving a scope: pop its bindings off the list.
- When looking up a name: traverse the list.
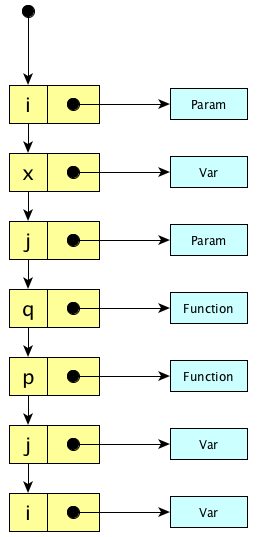
Generally speaking, scope entry and exit is fast, lookup is slow.
The central reference table works like this:
- When entering a scope: push an entity descriptor onto each chain corresponding to each name defined in the scope.
- When leaving a scope: pop the relevant entity descriptors.
- When looking up a name: do a constant-time hashtable lookup. (It’s guaranteed to be Θ(1) because the correct entry is first on the list!)
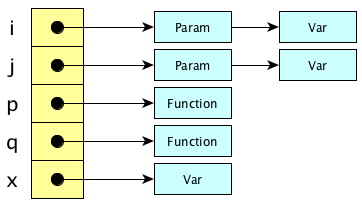
Generally speaking, scope entry and exit is slow, lookup is blazingly fast (assuming your hash function is cheap).
The principal argument in favor of dynamic scoping is the way they allow functions to be customized by using an “environment variable” style that allows selective overriding of a default (more or less). Michael Scott gives this example:
# Perl our $print_base = 10; sub print_integer { ... # some code using $print_base ... } # So generally we want to use 10, but say at one point # we were in a hex mood. We wrap the call in a block like this: { local $print_base = 16; print_integer($n); } # At the end of the block the old value is essentially restored
Lifetimes
The lifetime of an entity (also known as its extent) is just what it sounds like: the period (of time) from its creation (allocation) to its destruction (deallocation). With regard to lifetime, we can imagine different kinds of entities:
- Global entities that live forever (“forever” means from the time of its creation to the end of the entire program)
- Local entities created automatically when their enclosing function or block is called and destroyed when their containing function or block exits
- Entities explicitly created by the programmer that must be explicitly destroyed by the programmer.
- Entities explicitly created by the programmer and destroyed automatically when the runtime system determines they can no longer be referenced.
In the world of programming language implementation, we often see storage partitioned into regions for different types of entities based on their lifetimes:
| Region | Entities are... | Examples | Notes |
|---|---|---|---|
| Static | Allocated at fixed location in memory when program starts and live forever |
|
|
| Stack | Allocated and deallocated automatically at subroutine calls and returns |
|
|
| Heap | Allocated and deallocated dynamically |
|
|
Here’s an example showing each kind of storage class in action. We’ll work through it in class.
int x = 5; // Static void f() { static float y = 0; // Static - this is pretty fancy, eh? int z; // Stack y++; printf("abcdef"); // Literal probably static } // z deallocated here void h(int* a) { // a on stack, *a don’t care! . . . *a = 5; a[6] = 3; a = new int; // doesn’t affect old entity } // a goes away here, but not *a void g() { int* p = new int; // p on stack, *p on heap . . . delete p; // explicit deallocation of *p int* q = new int[10]; // q on stack, *q on heap . . . h(q); . . . delete[] q; } int main() { f(); f(); g(); }
Do not confuse the lifetime of an entity (entity lifetime) with the lifetime of a binding (binding lifetime). Yes, bindings have lifetimes too: a binding lifetime is the duration in which the binding is active.
And very important: The lifetime of a binding can be different from the lifetime of the entity to which the name is bound. The next two sections will explore this in more detail.
Entities Outliving Bindings
Entities outlive bindings all the time, and is usually normal. Here’s an example:
void f(int& x) {x = 5;} . . . int y; // create an entity and bind y to it f(y); // during execution of f, x is also bound to the entity cout << y; // x is no longer bound to the entity, but y still is, fine
But sometimes it can be a problem:
void f() { char* p = malloc(1024); } // Ooops!
This function allocates space for a new entity that lives, well, in C at least, (i.e., until the end of the process). But the binding of p to that entity is gone when the function returns. In C, this is called a memory leak and it is a Bad Thing. In (most) other languages, a (built-in) garbage collector can determine when dynamically allocated entities are no longer reachable, and will destroy those entities on its own. C programmers do not have a built-in garbage collector, so they have to:
- be insanely vigilant and careful in their coding;
- do allocation and deallocation from their own memory pools, never with
malloc/free; or - integrate some custom garbage collector (written by them or someone else).
Bindings Outliving Entities
Okay, if you think about it, bindings outliving entities is almost always a serious bug. One way it can happen is by explicitly deleting the entity while a binding is still active. Some languages prohibit explicit deallocation, but C allows it, making possible the following problem, the dangling pointer (also known as a dangling reference):
int* a; // create pointer entity and bind name 'a' to it a = malloc(sizeof(int)); // create int entity and bind name '*a' to it *a = 2; // assign to the int entity through the name '*a' free(a); // this destroys the int entity *a = 3; // NOOOOO! Binding still there; name *a attached to garbage
This bad enough, but there’s another way you can get dangling pointers; it’s one of the most evil and horrible and sinister things that happen in C programs. It goes like this:
char* get_some_data(FILE* f) { char buffer[1024]; read_at_most_n_bytes_from_file(f, &buffer, 1024); return &buffer; // NOOOOOOOOOOOOOO!!!!!!! }
The problem here is that, when a function finishes execution in C, all of its internal storage, that is, all of the entities bound to its local variables, are destroyed when the function exits. This code is returning a pointer to a destroyed entity. So this disaster can occur:
char* text = get_some_data(myfile); char secondCharacter = text[1]; // UH-OH, text[1] is bound to ... what?
get_some_data (Hint: define buffer differently).
Returning pointers to local variables is a special case of a more general problem: pointer variables in long-lived contexts pointing to data in shorter-lived contexts. Here’s another example:
int* p; void f() { int x; p = &x; // Assigning pointer-to-local to a global pointer, BAD } int main() { f(); // NOOOOOOOO!! At this point, what is *p? }
Dangling pointers are hideous. Evil. For more ways to create them, and for more problems they can cause, see the Wikipedia article on dangling pointers.
Knowing that the primary ways that dangling pointers occur are (1) via pointers to locals and via (2) permitting programmers to explicitly deallocation objects through a pointer, we can start to imagine how, as language, designers, we might prevent them from ever occurring.
Avoiding Pointers to Locals
How can we make it impossible for a pointer variable with a long lifetime to point to an object with a shorter lifetime? Here are some approaches:
- Have no explicit pointers in your language (with no explicit pointers, you can’t even make a pointer to a local variable);
- Disallow pointers to anything except heap-allocated storage;
- Allow pointers to locals, but only if a compile-time check determines it is safe to do so (after all, a compiler can easily keep track of nesting levels); or
- Move to the heap any local that becomes the target of a pointer.
Woah, had you even thought of Option 4? The language Go does this!
package main import "fmt" type Point struct{x, y int} func ExampleEscape() { var g *int // g means "global(ish)" f := func(x int) *Point { a := 5 // stays local b := 8 c := &b g = c // b escapes! return &Point{x, a * 5} // this escapes too! } fmt.Print(*f(2)) fmt.Println(*g) // Output: {2 25}8 }
If you only knew C, you might think this is terrible code! Pointers to both the local variable b, and a locally-allocated point object within the inner function f are passed out of the function: they escape. But this is not a problem in Go. The compiler recognizes this, and simply allocates b and the point object on the heap.
Note the thinking used by Go’s designers. They did not accept the fact that all local variables had to be allocated on the stack, even though that’s how things were always done in the past (in C and C++, that is). Always be amenable to questioning the conventional wisdom, and don’t trust those that say “this is the way we do things so shut up and conform.”
Preventing Explicit Deallocation
To avoid the other kind of dangling pointer creation, using a pointer variable after its target has been explicitly destroyed, you could:
- Disallow all forms of explicit deallocation and rely on a garbage collector.
- Check all memory accesses through pointers at run time, ensuring deallocated memory is never being accessed (but this can be expensive!)
- Allow explicit deallocation only by the owner of the resource.
Option 3 gives us safety and efficiency. Rust is famous for this. Let’s look at the most basic of basic examples only. The full story is very rich.
This Rust code does not even compile (the type Vec is not copyable):
fn main() { let a = vec![0, 1, 2]; // owned by variable a let b = a; // owned by variable b println!("{:?}", b); // works great, b is the owner println!("{:?}", a); // WILL NOT COMPILE }
Every time you assign, or pass as an argument, or return from a function, a non-copyable value, ownership is transferred. We call this a move. Non-copyable objects are implicitly pointed to. Rust prohibits non-owners from accessing the entity in any way. In addition to simply transferring ownership, Rust provides for borrowing:
fn main() { let a = vec![0, 1, 2]; // owned by variable a let b = &a; // b is just borrowing println!("{:?}", b); // works great, b is borrowing println!("{:?}", a); // works great, a still owns it }
delete operator. Research it. It’s not the same as the C++ delete, right? Can that cause a dangling pointer? Why or why not?
Safe Closures
Here’s a situation that looks like a cause of dangling references:
let x = 5; function a(i) { let y = 3; function b() { console.log(i + y + x); } y = 10; i = 2; return b; } p = a(4); // After this, a’s context goes away, or does it? p(); // But wait, what does p even do?
This looks bad because the returned function references variables from a function which has already finished. Generally, when a function finishes, don’t all of its local variables go away? What should happen in this case? A language could:
- Check for a cases like this in which a returned function references local variables of finished functions and prohibit such cases via a a compile-time or run-time error.
- Let the program crash or produce garbage when the returned function is called. Wait, just kidding, that’s not a good idea.
- Retain the context of the "outer" function, in this case
a, so that the returned function (b) can still use its data. In this case, where we keep the data from the finished function around for the returned function to use, the returned function is called a closure.
JavaScript’s designers chose option #3 because it is incredibly powerful, but at a price: you can’t allocate the function call contexts of the enclosing function on a (super-efficient) stack. Not every language is willing to give up stack allocation! What are the options for these less adventurous languages?
- C, Classic C++ — This issue never even comes up, since these languages don’t allow nested functions!
- Modula-2 — You can’t even write the code above because you can’t make a reference to any subroutine except a top-level one.
- Modula-3 — You can pass any subroutine, but you can’t return, or store in a variable anything other than a reference to a top-level one.
- Ada — The context in which a subroutine is declared must be at least as wide as the declared return type, and this rule is enforced at compile-time. This stifles any attempt to send a subprogram out of its context.
Deep and Shallow Binding
Here’s a fun case to consider:
function second(f) { const name = 'new' f() } function first() { const name = 'old' const printName = () => console.log(name) second(printName) } first()
In the function printName, the variable name is a free variable. When printName is passed to the function second and called there, it is running in a context that has its own name variable.
Question: what does this output? Does the function, when called, use the binding to name it received at the point it was defined ("old") or the one within the context it which it was finally executed ("new")?
The former behavior is known as deep binding (the binding happened early, back in the past, in the depths of time) and the latter as shallow binding (it happened later, more recently, in the shallow past).
Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- What is a binding? What, specifically is getting bound to what? A binding is an association between a name and an entity.
- Are there languages that let you create your own symbolic names? Mention a couple if you can. Yes, Swift, Haskell, Standard ML, and Scala.
- What is the difference between a declaration and a definition? A declaration introduces a name into the program, while a definition actually creates an entity (and allocates storage for it if required).
- What is an assignable? How does assignment differ from binding? An assignable is an entity that can be bound to a name. Assignment is the act of changing the value of an assignable.
- Why do some people dislike assignment? It makes reasoning about programs more difficult.
- Distinguish aliasing from polymorphism. Aliasing is when two names refer to the same entity, while polymorphism is when a single name can refer to different entities.
- Show how pointers give rise to aliasing. Two pointers can point to the same memory location.
- What is the scope of a binding? The region of the program text in which a binding is in effect.
- Why do we say scope is generally spatial rather than temporal? Because static scoping is easier to understand and implement; dynamic scoping has too many problems and is rarely, if ever, used anymore.
- What happens to a binding when a scope is left? It becomes deactivated (i.e., it is no longer in effect).
- What is the difference between static and dynamic scope? Static scope is determined by the program text, while dynamic scope is determined by the call stack.
- In a language with static scoping, what are three reasonable places for a scope of a variable to begin? At the beginning of the function, at the beginning of its declaration, or immediately after the declaration is complete.
- What is the technical term for a binding hiding a previous binding with the same name? Shadowing
- What is the temporal dead zone? The region between the beginning of a scope and the declaration of a variable within that scope.
- Distinguish Python, JavaScript, and Ruby's approaches to updating non-local variables. Python requires the use of the
globalkeyword, JavaScript updates the global variable, and Ruby requires the use of the$prefix. - What would this program output under (a) static scope rules and (b) under dynamic scope rules?
var x = 2; function f() { print x; } function g() { var x = 5; f(); print x; } g(); print x;Static: 2, 5, 2; Dynamic: 5, 5, 2 - What does this script print under (a) static scope rules and (b) dynamic scope rules?
var x = 1; function f() {return x;} function g() {var x = 2; return f();} print g() + x;(a) 2, (b) 3 - What is the difference between the way JavaScript and Rust handle the sequence:
let x = 3; let x = 3;
JavaScript disallows this (saying Identifier 'x' has already been declared) while Rust makes two distinct variables. - What are the two main approaches to implementing dynamic scope, and what are the advantages of each? (1) The association list, which is efficient when entering and leaving scopes, and (2) the central reference table, which performs lookup efficiently.
- What programming language feature practically destroys the sole argument in favor in dynamic scope? Default parameters
- What are static storage, stack storage, and heap storage, and what goes in each?
- What is a free variable? A variable that is used but not declared in a scope.
- What is the difference between deep binding and shallow binding? Deep binding uses the value of a free variable at the time the function was defined, while shallow binding uses the value at the time the function is called.
Summary
We’ve covered:
- Examples of names and entities
- Definition of entity
- Declarations vs. Definitions
- Assignables
- Polymorphism, Aliasing, Overloading
- Lifetimes
- Language design solution to possible lifetime problems
- Closures
- Dangling references
- Deep vs. Shallow Binding