C
Overview
C is a very popular systems programming language. Every developer needs to know C, whether or not they use it: it’s a kind of lingua franca, and as most high-level language’s runtime systems are written in C, knowing it helps you deal with the problem of leaky abstractions.
Some words to describe C are: Systems Small Popular Unsafe Low-level Unmanaged
History
C was once called NB, short for “New B” which, you might guess, was an evolution of the language B, which came from BCPL, which came from CPL. C basically dates from 1972 and has evolved a lot, and is still evolving!
Check out this brief bullet-point history of C, it’s quite good.
And of course, Wikipedia has a much longer history.
Versions
This 50+ year old language has seen a lot of growth and many revisions! Here’s a brief look:
| Version | AKA | Year Appeared | Links | About |
|---|---|---|---|---|
| 1972 | The original version, never standardized, not very pretty by today’s standards. No longer in use. | |||
| K&R C | C78 | 1978 | Wikipedia | The version from the first edition of the famous book. Never actually standardized. Made several additions and breaking language changes from the original version. Interesting from a historical perspective, but no longer used. |
| C90 | ANSI C C89 | 1989 | Wikipedia | First version with a published standard. Motivated by the fact that vendors were making a lot of their own enhancements to K&R. Surprisingly, this version is still in use! This was standardized by ANSI in 1989 and by the ISO in 1990, which is why it goes by multiple names. |
| C95 | NA1 | 1995 | cppref | Not considered a "real" version. Just C90 with minor clarifications and new library modules. |
| C99 | 1999 | Wikipedia cppref | A pretty big revision from C90, it added inline functions, a complex number type, variable length arrays, flexible array struct fields, and more. Still widely used. | |
| C11 | 2011 | Wikipedia cppref | A bunch of new features, most notably decent Unicode support, anonymous structs, and atomic operations. | |
| C17 | C18 | 2018 | Wikipedia cppref | No new language features, only clarifications and fixes applied to the previous standard. |
| C23 | 2024 | Wikipedia cppref | A further modernization with a handful of new features. |
Useful Resources
A lot of interesting material on C is really old and somewhat timeless because the essence of C has not changed that much over time. To understand what makes C the language it is, you should see this article on the development of C, written by Dennis Ritchie (the creator of C himself) in 2003; Rob Pike’s notes on C programming from 1989; Steve Summit’s C programming course notes from 1996–1999; and read the Kernighan and Ritchie book. Although this book only covers C90, it is an absolute classic.
But we want to be practical too! Versions prior to C11 are called “Classic C” or “Old C”; versions from C11 on are called “Modern C.” For Modern C, check out the comprehensive documentation at cppreference.com. This is a great resource for learning about the language, and it is kept up to date with the latest standards. There you’ll find an amazing language reference.
The Official StandardC has an international standard, ISO/IEC 9899:2024, but it costs well over 200 USD, so use the cppreference.com site instead.
A very useful guide for both the learner and the security-minded expert is Andrew Koenig’s C Traps and Pitfalls. This guide can help you a lot.
Something Fun
You gotta browse the IOCCC, and especially don't miss the Winners Page.
Learning By Example
Examples first, reference stuff later.
Hello, World
#include <stdio.h>
int main() {
puts("Hello, World");
return 0;
}
To compile, you really should specify the version:
gcc -std=c23 hello.c
This compiles the program, producing a.exe on Windows systems and a.out on pretty much every other system. If you want to compile and run in one shot, you can, on non-Windows systems, do:
gcc -std=c23 hello.c && ./a.out
and on Windows:
gcc -std=c23 hello.c && a
Rather than compiling all the way down to nearly-runnable code, you can generate assembly language only:
gcc -std=c23 -S hello.c
You can compile without linking:
gcc -std=c23 -c hello.c
Wait...linking? What even is linking? We’ll explain later. We have more examples to cover first.
Variables, Conditionals and Loops
Here’s another simple example, showing off for and if statements, format specifiers for printf, and the fact that variables require type annotations:
#include <stdio.h>
int main() {
puts(" A B C");
puts("------------------");
for (int c = 1; c <= 100; c++) {
for (int b = 1; b <= c; b++) {
for (int a = 1; a <= b; a++) {
if (a * a + b * b == c * c) {
printf("%6d%6d%6d\n", a, b, c);
}
}
}
}
return 0;
}
Functions
Type annotations are required for parameters and return types, too:
/*
* A program that makes an approximation to pi by generating a million random
* points in the unit square and computing the ratio of those inside the unit
* circle to the total number in the square. That value should be pretty close
* to Pi/4. The program displays the approximation as well as the actual
* value to 10 digits.
*/
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
/*
* Bad code, sort of. This program is simply approximating Pi using a million
* probes, but a much better program would take a value as a command line
* argument. Oh well. Okay for now.
*/
#define NUMBER_OF_PROBES 1000000
double squareOfDistanceToOrigin(double x, double y) {
return x * x + y * y;
}
/*
* Returns a random value in (-1..1)
*/
double randomValue() {
return 2.0 * rand() / RAND_MAX - 1.0;
}
int main() {
int inside = 0;
for (int i = 0; i < NUMBER_OF_PROBES; i++) {
double x = randomValue();
double y = randomValue();
if (squareOfDistanceToOrigin(x, y) < 1.0) {
inside++;
}
}
printf(
"Pi is about %12.10f (actual to 10 digits is %12.10f)\n",
4.0 * ((double)inside / NUMBER_OF_PROBES), M_PI
);
return 0;
}
Sizes and Addresses
As a system programming language, we often in C care very much about (1) how many bytes an entity takes up in memory, and (2) exactly at what address an entity resides in memory. We can answer the former question with the sizeof operator: it tells us the size in bytes of types (if parenthesized) and values (if not):
#include <stdio.h>
int main() {
printf("bool size: %lu\n", sizeof(bool));
printf("char size: %lu\n", sizeof(char));
printf("short size: %lu\n", sizeof(short));
printf("int size: %lu\n", sizeof(int));
printf("long size: %lu\n", sizeof(long));
printf("long long size: %lu\n", sizeof(long long));
printf("float size: %lu\n", sizeof(float));
printf("double size: %lu\n", sizeof(double));
printf("long double size: %lu\n", sizeof(long double));
printf("float complex size: %lu\n", sizeof(float _Complex));
printf("double complex size: %lu\n", sizeof(double _Complex));
printf("long double complex size: %lu\n", sizeof(long double _Complex));
int x;
// No parens when taking size of expression
printf("An int fits in %lu bytes\n", sizeof x);
return 0;
}One run of this program on an ARM64 macOS computer produced:
bool size: 1 char size: 1 short size: 2 int size: 4 long size: 8 long long size: 8 float size: 4 double size: 8 long double size: 8 float complex size: 8 double complex size: 16 long double complex size: 16 An int fits in 4 bytes
On other machines you may find long long and long double to have size 16, and long double complex to have size 32.
Fun facts about sizeof:
- The only type whose size is guaranteed is
char, which by definition has size = 1 byte. So you should pronounce the word c-h-a-r as “byte”. - Even though the exact sizes for most types are not known, these relationships are guaranteed:
sizeof(char) ≤ sizeof(short) ≤ sizeof(int) ≤ sizeof(long) ≤ sizeof(long long), and also thatsizeof(float) ≤ sizeof(double) ≤ sizeof(long double).
To find the address of a variable or function in memory, we use the address operator, &:
#include <stdio.h>
int square(int x) {
return x * x;
}
double global = 6.28;
int main() {
long z = 892300123888897;
bool b;
short s;
double _Complex c;
double x;
float y = 2.99f;
bool w;
printf("square is at address %p\n", &square);
printf("main is at address %p\n", &main);
printf("global is at address %p\n", &global);
printf("z is at address %p\n", &z);
printf("b is at address %p\n", &b);
printf("s is at address %p\n", &s);
printf("c is at address %p\n", &c);
printf("x is at address %p\n", &x);
printf("y is at address %p\n", &y);
printf("w is at address %p\n", &w);
return 0;
}One run of this program produced:
square is at address 0x10084fd90 main is at address 0x10084fda0 global is at address 0x100854010 z is at address 0x7ffeef3b3a20 b is at address 0x7ffeef3b3a1f s is at address 0x7ffeef3b3a1c c is at address 0x7ffeef3b3a08 x is at address 0x7ffeef3b3a00 y is at address 0x7ffeef3b39fc w is at address 0x7ffeef3b39fb
Here we can see that global variables and executable code are in a very different region of memory than where the local variables go. It looks like the locals are allocated like this:
┌─────────────────┬─────┐
7ffeef3b39f8 │ │ w │
├─────────────────┴─────┤
7ffeef3b39fc │ y │
├───────────────────────┤
7ffeef3b3a00 │ │
├ x ┤
7ffeef3b3a04 │ │
├───────────────────────┤
7ffeef3b3a08 │ │
├ ┤
7ffeef3b3a0c │ │
├ c ┤
7ffeef3b3a10 │ │
├ ┤
7ffeef3b3a14 │ │
├───────────────────────┤
7ffeef3b3a18 │ │
├───────────┬─────┬─────┤
7ffeef3b3a1c │ s │ │ b │
├───────────┴─────┴─────┤
7ffeef3b3a20 │ │
├ z ┤
7ffeef3b3a24 │ │
└───────────────────────┘
7ffeef3b3a28
On my machine, the local variables were allocated in the order they were declared, from high addresses down to low addresses. Sometimes you will see memory diagrams with high addresses above the lower addresses (which might actually be more common, but get adept reading it both ways.)
Note the padding. Memory alignment is a big deal; you’ll learn why in your hardware classes (or via a simple web search!)
Structs
A struct is a value with named fields.
#include <stdio.h>
struct { int x; char c; double y; } p = {3, 'A', 1.5};
int main() {
printf("Size of p is %lu\n", sizeof p);
printf("p at %p, p.x at %p, p.c at %p, p.y at %p\n", &p, &(p.x), &(p.c), &(p.y));
printf("Value of p is {x=%d, c=%c, y=%g}\n", p.x, p.c, p.y);
return 0;
}
One run of this program produced:
$ gcc -std=c23 structs.c && ./a.out
Size of p is 16
p at 0x105103010, p.x at 0x105103010, p.c at 0x105103014, p.y at 0x105103018
Value of p is {x=3, c=A, y=1.5}
which means the object was laid out in memory like this:
┌───────────────────────┐
105103010 │ p.x │
├─────┬─────────────────┤
105103014 │ p.c | │
├─────┴─────────────────┤
105103018 │ │
├ p.y ┤
10510301b │ │
└───────────────────────┘
(Of course things might look different on your machine.)
When you assign structs or pass them as parameters, the entire struct is copied, no matter how big it is!
#include <stdio.h>
#include <assert.h>
typedef struct {
double x;
double y;
} Point;
int main() {
Point p = {3.0, 5.0};
Point q = p;
assert(q.x == 3.0);
assert(q.y == 5.0);
p.x = 2.0;
assert(p.x == 2.0);
assert(q.x == 3.0);
puts("All tests passed");
return 0;
}
This shouldn’t really be surprising: after all, we created two struct objects in the above program, and they are laid out in memory like so:
┌───────────────────────┐ │ │ ├ p.x ┤ │ │ ├───────────────────────┤ │ │ ├ p.y ┤ │ │ ├───────────────────────┤ │ │ ├ q.x ┤ │ │ ├───────────────────────┤ │ │ ├ q.y ┤ │ │ └───────────────────────┘
Why is this a big deal?
Well, if you have very large structs, then assigning them, passing them as parameters, or returning them from functions can be quite slow, because a lot of memory needs to be copied, not to mention the program simply needs more space to run.
This is why similar code in Python, Ruby, Java, and JavaScript, do not copy by default. But is there a way in C to avoid copying? There is. We use pointers.
typedef
In order to allow a struct in one variable to be copied to another variable, the two variables have to be type-compatible, so we needed a type definition (typedef). There are some technical reasons why this is required, which you can read about here.
Pointers
Having access to an object’s address is more than just a curiosity.
Working with addresses gives you quite a bit of power and control.
If you grab the address of an entity through the & operator, what you actually have is called a pointer. And you can do things with it! You can get read and write access to the data that is pointed to. You can even do arithmetic on the actual addresses too (more on this later).
You can make a pointer to an existing object by applying the & operator, or you can allocate new memory on the fly with malloc (or related functions), giving you a pointer to this new memory. In the latter case, you need to free the memory when you are done with it.
#include <stdio.h>
#include <stddef.h>
#include <stdlib.h>
int main() {
int x = 5; // local vars automatically allocated
int* p = &x; // point to existing memory
int* q = nullptr; // point to nothing
int* r = malloc(sizeof(int)); // allocate new memory, point to it
int* s = malloc(100 * sizeof(int)); // allocate new memory, point to it
printf("%d %d %d", *p, *r, s[20]);
// printf("%d", *q); // CRASHES WITH A SEGFAULT
free(r);
free(s);
// free(p); // CRASHES WITH "POINTER BEING FREED WAS NOT ALLOCATED"
// free(q); // THIS IS ACTUALLY OK, IT DOES NOTHING
// printf("%d", *r); // CRASHES, BECAUSE r IS A "DANGLING POINTER"
// free(r); // UGH, NO, DOUBLE FREES ARE A SECURITY PROBLEM
return 0;
}
Pointer Notation
This picture captures the basic idea:
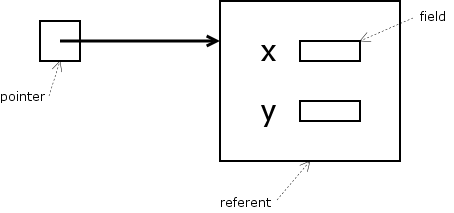
| If the pointer is called | Then the referent is called | and the field is called |
|---|---|---|
| p | *p | (*p).x or p->x
|
| If the referent is called | Then the pointer is called | and the field is called |
|---|---|---|
| p | &p | p.x
|
Pointers are usually used for dynamic, linked data structures. We’ll see some later.
The Null Pointer
The constant nullptr is a pointer that points to no valid memory location. It has the type nullptr_t, which can be implicitly converted to any other pointer type.
Memory Safety
C is a very unsafe language because of the awesome control you have over pointers. Because the language does not constrain you, you can (and will) introduce serious bugs and security vulnerabilities into your code. Among the problems you have to watch out for are:
Memory Leak
Failing to free up memory when you’re done with it, and the pointer to that memory is lost because it goes out of scope or is overwritten.
Dangling Pointer
A pointer that still points to memory that has been freed (or otherwise has gone away).
Use After Free
You actually access (read or write) a dangling pointer.
Double Free
You free the same memory twice.
Wild Pointer
An uninitialized pointer. It will point to a random location.
Invalid Free
Freeing a pointer that was not dynamically allocated.
Buffer Overflow
Writing outside the bounds of an allocated block of memory.
Here’s what ChatGPT has to say about this issues and how to prevent them:
| Problem | Description | Common Cause | Typical Fix |
|---|---|---|---|
| Memory Leak | Allocated memory not freed | Lost reference | Always free or track ownership |
| Dangling Pointer | Pointer to freed memory | Freed but not nulled | Set to NULL after free |
| Use After Free | Accessing freed memory | Dereferencing dangling pointer | Avoid use after free |
| Double Free | Calling free twice |
Duplicate frees | Nullify or track freed pointers |
| Wild Pointer | Uninitialized pointer | Used before assignment | Initialize to valid address or NULL |
| Buffer Overflow | Writing past bounds | Wrong index or length | Check bounds |
| Invalid Free | Freeing non-heap memory | Misuse of free |
Only free what you malloc |
| Memory Corruption | Overwriting wrong area | Overflow or use-after-free | Bounds checking and safe libraries |
The big takeaway here is that it is the programmer’s responsibility to manage memory safely in C. In many other languages, none of these problems are even possible.
Arrays
An array is C is really just a consecutive block of items in memory. When you create an array, you state how many items it contains. But you can’t ask the array at run time for this size value back! Under certain conditions, the sizeof operator can help you, but this happens at compile-time, and the compiler might not have that information.
Regardless of the allocated size of the array, arrays don’t really know how big they are, and you can read or write beyond the allocated memory:
#include <stdio.h>
void f(int i, int j) {
int x;
int ones[4] = { 1, 1, 1, 1 };
int twos[4] = { 2, 2, 2, 2 };
int y;
printf("%p %p %p %p\n", &x, &ones[0], &twos[0], &y);
twos[i] = 100; // twos[4] likely at same loc as ones[0]
ones[j] = 200; // ones[-1] likely at same loc as twos[3]
printf("%d\n", ones[0]); // very likely 100
printf("%d\n", twos[3]); // very likely 200
}
int main() {
f(4, -1);
return 0;
}
One run of this program produced:
0x7ffeee0559d4 0x7ffeee0559f0 0x7ffeee0559e0 0x7ffeee0559d0 100 200
On my machine at least, the non-arrays were put in memory at the lower address and the arrays went at the higher addresses. And some padding got put in there so the arrays were aligned at 16-bit addresses. You might see different things on your machine. And sure enough, writing outside the bounds of the array corrupted nearby variables. Here’s the picture:
┌───────────────────────┐
7ffeee0559d0 │ y │
├───────────────────────┤
7ffeee0559d4 │ x │ also ones[-7] and even twos[-3]
├───────────────────────┤
7ffeee0559d8 │ │
├───────────────────────┤
7ffeee0559dc │ │
├───────────────────────┤
7ffeee0559e0 │ twos[0] │
├───────────────────────┤
7ffeee0559e4 │ twos[1] │ also ones[-3]
├───────────────────────┤
7ffeee0559e8 │ twos[2] │ also ones[-2]
├───────────────────────┤
7ffeee0559ec │ twos[3] │ also ones[-1]
├───────────────────────┤
7ffeee0559f0 │ ones[0] │ also twos[4]
├───────────────────────┤
7ffeee0559f4 │ ones[1] │ also twos[5]
├───────────────────────┤
7ffeee0559f8 │ ones[2] │ also twos[6]
├───────────────────────┤
7ffeee0559fc │ ones[3] │
└───────────────────────┘
x and y by assigning to out-of-bounds indexes in either ones or twos.
twos[8992322]. What happened?
So bounds checking is not automatic because arrays do not know how big they are; however, you can sometimes do it yourself, because sizeof might be able to help:
#include <stdio.h>
int main() {
double vector[] = { 3.5, 2.9, 3.8, -22.9, 3.3E17 };
printf("The array is %lu bytes in size\n", sizeof vector);
printf("The array has %lu elements\n", sizeof vector / sizeof(double));
}
The array is 40 bytes in size The array has 5 elements
Hey, that was a cool trick to get the size of an array, right? Do you think it works for parameters? Let’s try it:
#include <stdio.h>
void worker(double v[]) {
printf("In worker, the array is %lu bytes in size \n", sizeof v);
printf("In worker, the array has %lu elements\n", sizeof v / sizeof(double));
}
int main() {
double vector[] = { 3.5, 2.9, 3.8, -22.9, 3.3E17 };
printf("In main, the array is %lu bytes in size \n", sizeof vector);
printf("In main, the array has %lu elements\n", sizeof vector / sizeof(double));
worker(vector);
}
In main, the array is 40 bytes in size In main, the array has 5 elements In worker, the array is 8 bytes in size In worker, the array has 1 elements
WHAT?! OH NO!
Instead of passing the entire 40-byte array from main to worker, something else happened. Only the eight byte address was passed. This is incredibly important:
When an array is declared as a variable, e.g.,int a[100]then space is allocated for the whole array, andsizeofwill work. BUT when an array is passed as a parameter, the parameter variable just holds an address, not the array itself We still get to use[ ]to access the array elements, at least C takes care that that still works.
There is a name for this: array decay.
So why is only the address passed? Well think about it: arrays could actually be massive, and it would take a lot of time to copy the big ones. Fair, C is, after all, efficient.
But efficiency is at odds with convenience, here: since passing arrays as arguments only passes the address of the array and nothing more, then actually doing anything with an array that you pass to a function requires that we pass the length of the array as a separate parameter. Really, no kidding:
/*
* A program that displays all the prime numbers up to and including 1000,
* using the famous algorithm of Erathostenes. This is a C99 program, not
* a C90 program.
*
* The purpose of the program is only to illustrate arrays assuming one has
* not yet seen pointers or command line arguments, so it isn't very good.
*/
#include <stdio.h>
#include <stdbool.h>
// To get primes up to and including 1000, the sieve has to have a slot at
// index 1000. But indices must start at 0, so there have to be 1001 slots
// in the array.
#define SIZE 1001
// Fills the first n slots of array s with the given value.
void fillArray(bool s[], bool value, int n) {
for (int i = 0; i < n; i++) {
s[i] = value;
}
}
// This function writes false in each slot of the array corresponding to a
// nonprime number. First, we know 0 and 1 are not prime. Then for each
// value starting with 2, if the value is still thought to be prime, we
// write false in each slot corresponding to its multiples.
void checkOffComposites(bool s[], int n) {
s[0] = false;
s[1] = false;
for (int i = 2; i * i < n; i++) {
if (s[i]) {
for (int j = i + i; j < n; j += i) {
s[j] = false;
}
}
}
}
// This function writes out all the values which correspond to positions in a
// vector containing the value true. Each value is written to the standard
// output in a field of 8 characters.
void displayTrueIndices(bool s[], int n) {
for (int i = 0; i < n; i++) {
if (s[i]) {
printf("%8d", i);
}
}
printf("\n");
}
// main() just calls the worker functions.
int main() {
bool sieve[SIZE];
fillArray(sieve, true, SIZE);
checkOffComposites(sieve, SIZE);
displayTrueIndices(sieve, SIZE);
return 0;
}
What if you wanted to copy an array? You can write code to do it manually, element-by-element, or use a library function, like memcpy or memmove but we are not ready for such sorcery yet.
When assigning or passing structs, the whole struct is copied. When assigning or passing arrays, only the address is copied.
Pointers and arrays are closely related. The value of an array variable is a pointer to its first element (e.g., a == &a[0]), and
is the same as
*(e1 + e2)
For definitions pointers and arrays are different:
int *x; /* is totally different from: */
int x[100];
int *a[n]; /* is totally different from: */
int a[n][100];
But for declarations, at least in parameter declarations, you can blur the distinction:
void f(int* a) { ... }
void g(int b[]) { ... }
An array of ints, or pointer to an int, can be passed to either.
Strings
Definitions from ISO/IEC 9899
- A byte with all bits set to 0 is called the null character.
- A string (a.k.a. multibyte string) is a contiguous sequence of characters (of type char) terminated by and including the first null character.
- The length of a string is the number of bytes preceding the null character and the value of a string is the sequence of the values of the contained characters, in order.
So you can make a string with an array of characters with a zero at the end, or use string literals, which are sequences of (1) characters except \, ", and newlines, and (2) escapes (\a \b \f \n \r \t \v \' \" \? \\ \one-to-three-octaldigits \xhexdigits \ufour-hex-digits \Ueight-hex-digits). Let’s just do examples:
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#include <assert.h>
// Crazy! macOS does not follow the standard!
typedef __CHAR32_TYPE__ char32_t;
void inspect_8(const char* s) {
printf("\n%s\nUTF-8: ", s);
while (*s) {
printf(" %02x", (unsigned)(uint8_t)(*s++));
}
printf("\n");
}
void inspect_32(const char32_t* s) {
printf("UTF-32: ");
while (*s) {
printf(" %08x", (unsigned)(uint32_t)(*s++));
}
printf("\n");
}
void demo_the_basic_string_as_byte_array() {
char just_a_char_array[3] = {'d', 'o', 'g'};
char actually_a_string[4] = {'d', 'o', 'g', (char)0};
char this_is_also_a_string[4] = {'d', 'o', 'g', '\0'};
char s[4] = "dog";
// String literals are arrays with the zero at the end
assert(s[0] == 'd' && s[1] == 'o' && s[2] == 'g' && s[3] == (char)0);
// The string takes up one byte per character + one for the zero
assert(sizeof s == 4);
// strlen does not count the zero
assert(strlen(s) == 3);
}
void demo_char_stars_are_utf8() {
const char* correct = "año";
assert(strlen(correct) == 4); // Because ñ is encoded as C3 B1
assert(correct[0] == (char)0x61); // 'a'
assert(correct[1] == (char)0xc3); // First byte of 2-byte encoding of ñ
assert(correct[2] == (char)0xb1); // Second byte of 2-byte encoding of ñ
assert(correct[3] == (char)0x6f); // 'o'
}
void show_strings_as_different_sizes() {
// "" are utf-8 sequences; U"" are UTF-32 sequences
inspect_8("año");
inspect_32(U"año");
inspect_8("kōpa`a");
inspect_32(U"kōpa`a");
inspect_8("привет");
inspect_32(U"привет");
inspect_8("世界");
inspect_32(U"世界");
inspect_8("🐕🍱");
inspect_32(U"🐕🍱");
inspect_8("🇦🇽🏃🏽♀️");
inspect_32(U"🇦🇽🏃🏽♀️");
}
int main() {
demo_the_basic_string_as_byte_array();
demo_char_stars_are_utf8();
show_strings_as_different_sizes();
}
Here is the output for this program on my Mac:
año UTF-8: 61 c3 b1 6f UTF-32: 00000061 000000f1 0000006f kōpa`a UTF-8: 6b c5 8d 70 61 60 61 UTF-32: 0000006b 0000014d 00000070 00000061 00000060 00000061 привет UTF-8: d0 bf d1 80 d0 b8 d0 b2 d0 b5 d1 82 UTF-32: 0000043f 00000440 00000438 00000432 00000435 00000442 世界 UTF-8: e4 b8 96 e7 95 8c UTF-32: 00004e16 0000754c 🐕🍱 UTF-8: f0 9f 90 95 f0 9f 8d b1 UTF-32: 0001f415 0001f371 🇦🇽🏃🏽♀️ UTF-8: f0 9f 87 a6 f0 9f 87 bd f0 9f 8f 83 f0 9f 8f bd e2 80 8d e2 99 80 ef b8 8f UTF-32: 0001f1e6 0001f1fd 0001f3c3 0001f3fd 0000200d 00002640 0000fe0f
Signed and Unsigned Integers
C allows both! Be careful!
/*
* This is an example of three cases where mixing signed and unsigned values cause
* trouble.
*/
#include <stdio.h>
#include <string.h>
void expect(int condition) {
printf("%s\n", condition ? "Cool" : "Hey, WTF?");
}
/* FAIL! (Example from Bryant and O'Hallaron, page 77) */
int longerThan(char *s, char *t) {
return strlen(s) - strlen(t) > 0; /* FAIL */
}
int main() {
int x = -1;
int y = 1000000000;
unsigned z = 3000000000;
expect(x < y);
expect(y < z);
expect(x < z);
expect(!longerThan("Jen", "Jennifer"));
}
Commandline Arguments
You can write the main() function with zero arguments, like we've been doing, or with two:
int main(int argc, char** argv) {
/*
argc is the number of command line arguments
including the name of the program.
argv is an array of strings containing the command
line arguments. argv[0] is the program name,
argv[1] is the first argument (if present),
argv[2] is the second, etc.
*/
}
Files
A first example:
/*
* This is an inefficient program that takes two command line
* arguments -- the first is the name of a file that should exist,
* and the second the name of a file that should not exist ---
* and creates the second file with the "capitalized" content of
* the first. If the second file already exists, it will be
* overwritten.
*
* This program is slow because it uses fgetc and fputc. Also,
* it assumes the files are text files, so the file size of
* the output file might differ from that of the input file.
*/
#include <stdio.h>
#include <ctype.h>
int main(int argc, char** argv) {
if (argc != 3) {
puts("Exactly two commandline arguments needed");
return 1;
} else {
FILE* in = fopen(argv[1], "r");
if (!in) {
printf("File %s does not exist\n", argv[1]);
return 2;
}
FILE* out = fopen(argv[2], "w");
while (1) {
int c = fgetc(in);
if (c == EOF) break;
fputc(toupper(c), out);
}
fclose(in);
fclose(out);
return 0;
}
}
Most file operations are in <stdio.h>
f = fopen(name, mode)— opens a file, mode can be "r", "w", "a", "r+", "w+", "a+", "rb", "wb", "ab", "rb+", "wb+", or "ab+".fclose(f)c = fgetc(f)fputc(c, f)num_read = fread(buffer, object_size, num_objects, f)num_written = fwrite(buffer, object_size, num_objects, f)fscanf(f, format, args...)fprintf(f, format, args...)
fread and fwrite.
Standard Input and Standard Output
There are two special filehandles that are always open and
available to every C program: stdin and stdout.
By default these are the current console, but they can be redirected,
e.g.
$ myprogram < stuff.txt $ myprogram > junk.txt $ myprogram < stuff.txt > junk.txt
These functions automatically work on stdin and stdout:
int puts(const char* s)— writes s (without the \0) then a \n to stdout, returns a non-negative integer on success or EOF on error.char* gets(char* s)— DO NOT USEint putchar(int c)— writes c to stdout, returns c on success or EOF on error.int getchar()— reads next char from stdin, returning it on success or EOF on error.printf— print a formatted string to stdout.scanf— read into variables from stdin.
NOTE: No one I know seems to have any idea how to make stdin and stdout behave as binary files. WTF????
Data Structures
This example shows both the use of arrays and pointers, and how to package things up so as to create an abstract data type. Put the “interface” in a header file:
/*
* An abstract data type for sets-of-strings implemented as hashtables.
* This module defines a type called HashTable. The only way to hide
* the representation of a type in C is to say that it is a pointer
* to something, and define that something elsewhere.
*/
typedef struct H* HashTable;
/*
* A hashtable must keep track of the hash function being used.
* Since we are storing strings, the function must map strings to
* ints.
*/
typedef int (*HashFunction)(char*);
/*
* Hashtable operations.
*/
HashTable createHashTable(unsigned int capacity, HashFunction hash);
void addItem(HashTable table, char* item);
void removeItem(HashTable table, char* item);
bool containsItem(HashTable table, char* item);
void destroyHashTable(HashTable table);
Then, the implementation
/*
* Implementation of the abstract data type for sets-of-strings
* implemented as hashtables.
*/
#include <stddef.h>
#include <stdlib.h>
#include <string.h>
#include "hashtable.h"
/*
* The hashtable will be implemented as an array of linked
* lists of strings. Here is the linked list part:
*/
struct Node;
typedef struct Node* Link;
struct Node {
char* item;
Link next;
};
/*
* The table has the array of linked lists, its capacity (number
* of cells in the array, and the hash function. In the header file
* we defined a HashTable as a pointer to a "struct H", so here
* finally is the definition of struct H.
*/
struct H {
Link* data;
unsigned int capacity;
HashFunction hash;
};
/*
* Allocates a new node to hold the given initial values, and
* returns a pointer to that node. Returns nullptr if the node
* could not be allocated.
*/
Link newNode(char* item, Link next) {
Link result = calloc(1, sizeof(struct Node));
if (result == nullptr) return nullptr;
result->item = item;
result->next = next;
return result;
}
/*
* Creates a hashtable with the given capacity and hash function.
* Returns a pointer to the newly created table, or nullptr if the
* table could not be created.
*/
HashTable createHashTable(unsigned int capacity, HashFunction hash) {
HashTable table = (HashTable)calloc(1, sizeof(struct H));
if (table == nullptr) return nullptr;
table->data = (Link*)calloc(capacity, sizeof(Link));
if (table->data == nullptr) return nullptr;
table->capacity = capacity;
table->hash = hash;
return table;
}
/*
* Adds the given item to the table, unless the item is already in
* the table, in which case it does nothing.
*/
void addItem(HashTable table, char* item) {
/* Which bucket does the item hash to? */
int index = table->hash(item) % table->capacity;
/* Search the linked list - if already there, bail! */
Link p;
for (p = table->data[index]; p != nullptr; p = p->next) {
if (strcmp(p->item, item) == 0) {
return;
}
}
/* Didn't find it in the list - add it! */
table->data[index] = newNode(item, table->data[index]);
}
/*
* Removes the given item from the table. If the item isn't there,
* this function does nothing.
*/
void removeItem(HashTable table, char* item) {
/* Which bucket does the item hash to? */
int index = table->hash(item) % table->capacity;
/* Bail immediately if this bucket is empty */
if (table->data[index] == nullptr) return;
/* Special case: if the item to be removed is the
* FIRST one in the list, the array cell must be
* modified.
*/
if (strcmp(table->data[index]->item, item) == 0) {
Link nodeToRemove = table->data[index];
table->data[index] = table->data[index]->next;
free(nodeToRemove);
return;
}
/* Check all the nodes besides the first one in the list;
* remove immediately if found.
*/
Link p;
for (p = table->data[index]; p->next != nullptr; p = p->next) {
if (strcmp(p->next->item, item) == 0) {
Link nodeToRemove = p->next;
p->next = p->next->next;
free(nodeToRemove);
return;
}
}
}
/*
* Returns 1 (true) if item is in table, otherwise returns 0 (false).
*/
bool containsItem(HashTable table, char* item) {
/* Which bucket does the item hash to? */
int index = table->hash(item) % table->capacity;
/* Search the linked list */
Link p;
for (p = table->data[index]; p != nullptr; p = p->next) {
if (strcmp(p->item, item) == 0) {
return true;
}
}
/* Didn't find it in the list */
return false;
}
/*
* Cleans up any memory allocated when we created the hashtable.
*/
void destroyHashTable(HashTable table) {
/* First free the linked list nodes */
int i;
for (i = 0; i < table->capacity; i++) {
while (table->data[i] != 0) {
Link nodeToRemove = table->data[i];
table->data[i] = table->data[i]->next;
free(nodeToRemove);
}
}
/* Then free the table struct. */
free(table->data);
/* Free the table itself, because createHashTable allocated space */
free(table);
}
Unit Testing
A unit test for the hashtable module above
/*
* Unit test for the hashtable abstract data type. It isn't very complete.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
#include "hashtable.h"
int stupidHash(char* s) {
return (strlen(s) == 0) ? 20 : s[0] * s[strlen(s) - 1];
}
int main() {
HashTable table = createHashTable(6, stupidHash);
addItem(table, "dog");
addItem(table, "cat");
addItem(table, "ear");
addItem(table, "egg");
addItem(table, "bag");
addItem(table, "zoo");
addItem(table, "pig");
addItem(table, "cat");
addItem(table, "gag");
addItem(table, "bat");
assert(containsItem(table, "pig"));
assert(containsItem(table, "zoo"));
assert(containsItem(table, "cat"));
assert(containsItem(table, "ear"));
assert(containsItem(table, "bat"));
assert(containsItem(table, "pig"));
assert(!containsItem(table, "hog"));
assert(!containsItem(table, "fit"));
assert(!containsItem(table, "git"));
removeItem(table, "zoo");
removeItem(table, "fig");
assert(containsItem(table, "egg"));
assert(!containsItem(table, "zoo"));
assert(!containsItem(table, "fig"));
assert(!containsItem(table, "git"));
addItem(table, "zoo");
assert(containsItem(table, "zoo"));
destroyHashTable(table);
puts("All tests passed\n");
return 0;
}
Wizardry
The danger zone.
Non-converting Casts
This program shows off the kind of thing C is good for. It puts integers into 32-bit memory locations that interprets the data in those locations as floats and writes them (Gaaack! No, wait, it’s okay, this is what C is for!).
/*
* This program takes in two integer arguments (call them x and y) and writes
* all the values in between them (inclusive) in hex, decimal, and as floating
* point values. Yikes.
*/
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char** argv) {
int low;
int high;
int x;
if (argc != 3) {
printf("You need exactly two integer arguments");
return -1;
}
low = atoi(argv[1]);
high = atoi(argv[2]);
x = low;
do {
printf("%08X %10d %#16.7e\n", x, x, *((float*)&x));
} while (x++ != high);
return 0;
}
Something Cool
This is a cool self-printing program written in original C, back when you did not have to give a type to main nor return 0 nor include a library to be allowed to use printf. Interestingly, bypassing these supposed language rules are but warnings, so you can still get a compiler to run it if you disable warnings.
main(){char*c="main(){char*c=%c%s%c;printf(c,34,c,34);}";printf(c,34,c,34);}Here’s how I got gcc to run it:
$ gcc -w self.c && ./a.out
main(){char*c="main(){char*c=%c%s%c;printf(c,34,c,34);}";printf(c,34,c,34);}
$ gcc -w self.c && ./a.out | diff - self.c
Machine Code in a String
Here’s a fun one. It executes x86 machine code directly. Of course it will only work on an x86. C does not promise portability.
/*
* Illustration of executing machine code as a C string.
* Works only on most Intel processors.
*/
#include <stdio.h>
int (*f)() = "\xb0\x64\x0f\xb6\xc0\xc3";
int main() {
printf("%d\n", f());
return 0;
}
$ gcc -w onehundred.c && ./a.out 100
Understanding the Memory Layout
Memory for a C program in execution is generally divided up into a static portion, a stack portion, and a heap portion. Sometimes there might be a bss section, of interest, and a text section, which holds code, not data. Some resources that might help:
- A blog post on C memory layout
- Note from the CS 225 class at the University of Illinois
- The memory layout page from a large C tutorial
C and Security
C is known to be an insecure language, meaning the programmer, not the environment or runtime, does the vast majority of checking.
Many security issues are low-level issues that can never happen in other languages, such as buffer overruns.
Secure coding in C is such a massive topic that we’ll handle it later. Here are some links that might be of interest until then:
- Slides from an MIT lecture
- Article from CProgramming.com
- A recent article, which has some C++ covered as well
- SEI CERT C Coding Standard
Criticisms
Is C even a real programming language? Why do some even ask this question?
Read this discussion and the short linked article to see why.
Some Reference Material
Here is a very sparse collection of reference material.
Program Structure
A C program is spread over one or more files. Each file is a sequence of declarations. A declaration is either a (1) object declaration, (2) type declaration, (3) function declaration, or (4) a directive. Each file is compiled then the compiled units are linked together to form an executable program.
Reserved Words
Reserved words are those that cannot be used as identifiers.
alignasalignofautoboolbreakcasecharconstconstexprcontinuedefaultdodoubleelseenumexternfalsefloatforgotoifinlinelongnullptrregisterrestrictreturnshortsignedsizeofstaticstatic_assertstructswitchthread_localtruetypedeftypeoftypeof_unqualunionunsignedvoidvolatilewhile_Atomic_BitInt_Complex_Decimal128_Decimal32_Decimal64_Generic_ImaginaryTypes
C has several built-in types, one pseudo type, and five mechanisms to create user defined types.
- Built-in types
boolcharsigned charunsigned charshort(a.k.a signed short, short int, or signed short int)unsigned short(a.k.a. unsigned short int)int(a.k.a. signed, or signed int)unsigned(a.k.a. unsigned int)long(a.k.a signed long, long int, or signed long int)unsigned long(a.k.a. unsigned long int)long long(a.k.a signed long long, long long int, or signed long long int)unsigned long long(a.k.a. unsigned long long int)floatdoublelong doublefloat _Complexdouble _Complexlong double _Complex_Decimal32_Decimal64_Decimal128
- Pseudo type
void
- Type formers
enum*(pointer)[ ](array)( )(function)unionstruct
Declarations
In C you declare entities with declarators, which are pretty hideous in hindsight, though some people love them.
Examples:
int x, *y, z[5], *r[7], (*s)[7], ***q, a(int), *b(int), (*c)(int), **d[5][9];
These mean:
xis an int.*yis an int, thereforeyis a pointer to an int.z[i]for some i is an int, thereforezis an array of 5 ints.*r[i]is an int, soris an array of 7 pointers to ints.(*s)[i]is an int, sosis a pointer to an array of 7 ints.***qis an int, soqis a pointer to a pointer to a pointer to an int.a(i)is an int, soais a function taking in an int and returning an int.*b(i)is an int, sobis a function taking in an int and returning a pointer to an int.(*c)(i)is an int, socis a pointer to a function taking in an int and returning an int.**d[i][j]is an int, sodis an array of 5 arrays of 9 arrays of pointers to pointers to ints.
Statements
;(the null statement)- any expression is a statement (function calls and assignments happen to be expressions)
{statements}(this is a "block" of statements)if(can optionally have an else part)switch(very messy multiway branch)while(loop with termination test at the beginning)do...while(loop with termination test at the end)for(loop with built-in initialization, termination test, and iteration mechanism)return(to return from a function)goto(immediate, unconditional jump to some label)break(immediate exit from innermost enclosing loop or switch)continue(jump to end of innermost enclosing loop—not out of the loop)
Operators
Here are the C operators, presented from highest to lowest precedence.
| Operator(s) | Associativity | Comments |
|---|---|---|
[], (), ., ->
| L | subscript, call, structure field access, structure field access through pointer |
!, ~, +, -, &, *, ++, --, sizeof | R | logical-not, bitwise-not, unary-plus, unary-negation, address-of, dereference, increment, decrement, size |
(type)
| L | type conversion |
*, /, %
| L | multiply, divide, modulo |
+, -
| L | add, subtract |
<<, >>
| L | bitwise shifts |
<, <=, >, >=
| L | less-than, less-than-or-equal, greater-than, greater-than-or-equal |
==, !=
| L | equal-to, not-equal-to |
&
| L | bitwise-and |
^
| L | bitwise-xor |
|
| L | bitwise-or |
&&
| L | logical-short-circuit-and |
||
| L | logical-short-circuit-or |
? :
| R | conditional |
=,*=, /=, %=, +=, -=<<=, >>=,&=, ^=, |=
| R | assignment |
,
| L | comma |
Standard Library
C is a small language with an extensive standard library. The library features tons of global types and functions grouped into over a couple dozen library modules.
Here is a brief outline of the library. It lists all of the modules but only some of the contents. For a great summary of the library, see the documentation pages at cppreference.com. Here are some of the highlights from the library:
| Module | Description | Sample Contents |
|---|---|---|
| <assert.h> | Diagnostics | assert |
| <complex.h> | Complex numbers | complex, _Complex_I, I, CX_LIMITED_RANGE, c[a]cos[h][f|l], c[a]sin[h][f|l], c[a]tan[h][f|l], cexp[f|l], clog[f|l], cabs[f|l], cpow[f|l], csqrt[f|l], carg[f|l], cimag[f|l], conj[f|l], cproj[f|l], creal[f|l] |
| <ctype.h> | Character handling | islanum, isalpha, isblank, iscntrl, isdigit, isgraph, islower, isprint, ispunct, isspace, isupper, isxdigit, tolower, toupper |
| <errno.h> | Errors | errno, EDOM, EILSEQ, ERANGE |
| <fenv.h> | Floating-point environment | fenv_t, fexcept_t, FE_DIVBYZERO, FE_INEXACT, FE_INVALID, FE_OVERFLOW, FE_UNDERFLOW, FE_ALL_EXCEPT, FE_DOWNWARD, FE_TONEAREST, FE_TOWARDZERO, FE_UPWARD, FE_DFL_ENV, FENV_ACCESS, fclearexcept, fegetexceptflag, feraiseexcept, fesetexceptflag, fetestexcept, fegetround, fesetround, fegetenv, feholdexcept, fesetenv, feupdateenv |
| <float.h> | Characteristics of floating types | FLT_ROUNDS, FLT_EVAL_METHOD, FLT_RADIX, (FLT|[L]DBL)_DIG, DECIMAL_DIG, (FLT|[L]DBL)_MAINT_DIG, (FLT|[L]DBL)_MIN[_10]_EXP, (FLT|[L]DBL)_MAX[_10]_EXP, (FLT|[L]DBL)_MIN, (FLT|[L]DBL)_MAX, (FLT|[L]DBL)_EPSILON |
| <inttypes.h> | Format conversion of integer types | imaxdiv_t, imax(abs|div), strto(i|u)max, wcsto(i|u)max, PRI(d|i|u|o|x|X)([LEAST|FAST](8|16|32|64)|MAX|PTR), SCN(d|i|u|o|x)([LEAST|FAST](8|16|32|64)|MAX|PTR) |
| <iso646.h> | Alternative spellings | and[_eq], or[_eq], xor[_eq], not[_eq], bit(and|or), compl |
| <limits.h> | Sizes of integer types | CHAR_BIT, [S]CHAR_MIN, [S|U]CHAR_MAX, MB_LEN_MAX, SHRT_MIN, [U]SHRT_MAX, INT_MIN, [U]INT_MAX, LONG_MIN, [U]LONG_MAX, LLONG_MIN, [U]LLONG_MAX, BOOL_WIDTH, [U](CHAR|SHORT|INT|LONG|LLONG)_(WIDTH|MAX), SCHAR_WIDTH, BITINT_MAXWIDTH |
| <locale.h> | Localization | struct lconv, NULL, LC_ALL, LC_NUMERIC, LC_MONETARY, LC_COLLATE, LC_CTYPE, LC_TIME, setlocale, localeconv |
| <math.h> | Mathematics | float_t, double_t, HUGE_VAL[F|L], INFINITY, NAN, FP_INFINITE, FP_NAN, FP_NORMAL, FP_SUBNORMAL, FP_ZERO, FP_FAST_FMA[F|L], FP_ILOGB[0|NAN], MATH_ERRNO, MATH_ERREXCEPT, math_errhandling, FP_CONTRACT, fpclassify, isfinite, isinf, isnan, isnormal, signbit, [a]sin[h][f|l], [a]cos[h][f|l], [a]tan[h][f|l], atan2[f|l], exp[f|l], exp2[f|l], expm1[f|l], frexp[f|l], ilogb[f|l], ldexp[f|l], log[f|l], log10[f|l], log1p[f|l], log2[f|l], logb[f|l], modf[f|l], scalb[l]n[f|l], cbrt[f|l], fabs[f|l], hypot[f|l], pow[f|l], sqrt[f|l], erf[c][f|l], (l|t)gamma[f|l], ceil[f|l], floor[f|l], nearbyint[f|l], [l][l]rint[f|l], [l][l]round[f|l], trunc[f|l], fmod[f|l], remainder[f|l]. remquo[f|l], copysign[f|l], nan[f|l], nextafter[f|l], nexttoward[f|l], fdim[f|l], fmin[f|l], fmax[f|l], fma[f|l], isgreater, isgreaterequal, isless, islessequal, islessgreater, isunordered |
| <setjmp.h> | Nonlocal jumps | jmp_buf, setjmp, longjmp |
| <signal.h> | Signal handling | sig_atomic_t, SIGABRT, SIGFPE, SIGILL, SIGINT, SIGSEGV, SIGTERM, SIG_DFL, SIG_ERR, SIG_IGN, signal, raise |
| <stdarg.h> | Variable arguments | va_list, va_start, va_arg, va_end, va_copy |
| <stdatomic.h> | Atomics | ATOMIC_BOOL_LOCK_FREE, ATOMIC_CHAR_LOCK_FREE, ATOMIC_CHAR16_T_LOCK_FREE, ATOMIC_CHAR32_T_LOCK_FREE, ATOMIC_WCHAR_T_LOCK_FREE, ATOMIC_SHORT_LOCK_FREE, ATOMIC_INT_LOCK_FREE, ATOMIC_LONG_LOCK_FREE, ATOMIC_LLONG_LOCK_FREE, ATOMIC_POINTER_LOCK_FREE, ATOMIC_FLAG_INIT, memory_order, atomic_flag, atomic_init, kill_dependency, atomic_thread_fence, atomic_signal_fence, atomic_is_lock_free, atomic_store, atomic_load, atomic_exchange, atomic_compare_exchange, atomic_fetch, atomic_flag, atomic_flag_test_and_set, atomic_flag_clear |
| <stdbit.h> | Macros for bit and byte representations | stdc_leading_zeros, stdc_leading_ones, stdc_trailing_zeros, stdc_trailing_ones, stdc_first_leading_zero, stdc_first_leading_one, stdc_first_trailing_zero, stdc_first_trailing_one, stdc_count_zeros, std_count_ones, stdc_has_single_bit, stdc_bit_width, stdc_bit_floor, stdc_bit_ceil |
| <stdckdint.h> | Checked integer operations | ckd_add, ckd_sub, ckd_mul |
| <stddef.h> | Common definitions | NULL, offsetof, nullptr_t, ptrdiff_t, size_t, max_align_t |
| <stdint.h> | Integer types | [u]intN_t, [u]int_leastN_t, [u]int_fastN_t, [u]intptr_t, [u]intmax_t, INTN_MIN, INTN_MAX, UINTN_MAX, INT_LEASTN_MIN, INT_LEASTN_MAX, UINT_LEASTN_MAX, INT_FASTN_MIN, INT_FASTN_MAX, UINT_FASTN_MAX, INTPTR_MIN, INTPTR_MAX, UINTPTR_MAX, INTMAX_MIN INTMAX_MAX, UINTMAX_MAX, PTRDIFF_MIN, PTRDIFF_MAX, SIG_ATOMIC_MIN, SIG_ATOMIC_MAX, SIZE_MAX, WCHAR_MIN, WCHAR_MAX, WINT_MIN, WINT_MAX, INTN_C, UINTN_C, INTMAX_C, UINTMAX_C |
| <stdio.h> | Input/output | FILE, fpos_t, size_t, BUFSIZ, EOF, FILENAME_MAX, FOPEN_MAX, L_tmpnam, NULL, SEEK_CUR, SEEK_END, SEEK_SET, TMP_MAX, _IO(F|L|N)BF, stdin, stdout, stderr, remove, rename, tmpfile, tmpnam, fclose, fflush, fopen, freopen, set[v]buf, [v][f|s|sn]printf [v][f|s]scanf, [f]getc, [f]gets, [f]putc, [f]puts, getchar, putchar, ungetc, fread, fwrite, fseek, ftell, rewind, fgetpos, fsetpos, clearerr, feof, ferror, perror |
| <stdlib.h> | General utilities | EXIT_FAILURE, EXIT_SUCCESS, RAND_MAX, NULL, MB_CUR_MAX, div_t, ldiv_t, lldiv_t, wchar_t, size_t, ato(i|f|l|ll), strto(f|d|ld|l|ll|ul|ull), rand, srand, calloc, malloc, realloc, free, abort, exit, atexit, _Exit, system, getenv, bsearch, qsort, [l][l]abs, [l][l]div, mblen, mbtowc, wctomb, mbstowcs, wcstombs |
| <string.h> | String handling | NULL, size_t, str[n]cpy[_s], str[n]cat[_s], str[n]dup, str[n]cmp, strcoll, str[r]chr, str[c]spn, strpbrk, strstr, strlen[_s], strerror[_s], strerrorlen[_s], strtok[_s], strxfrm, memcpy[_s], memmove[_s], memcmp, memchr, memset[_s], memset_explicit, memccpy |
| <tgmath.h> | Type-generic math | acos, asin, atan, acosh, asinh, atanh, cos, sin, tan, cosh, sinh, tanh, exp, log, pow, sqrt, fabs, atan2, cbrt, ceil, copysign, erf, erfc, exp2, expm1, fdim, floor, fma, fmax, fmin, fmod, frexp, hypot, ilogb, ldexp, lgamma, llrint, llround, log10, log1p, log2, logb, lrint, lround, nearbyint, nextafter, nexttoward, remainder, remquo, rint, round, scalbn, scalbln, tgamma, trunc, carg, cimag, conj, cproj, creal |
| <threads.h> | Concurrency Support | thrd_t, thrd_create, thrd_equal, thrd_current, thrd_sleep, thrd_yield, thrd_join, thrd_detach, thrd_exit, thrd_success, thrd_busy, thrd_error, thrd_nomem, thrd_timedout, thrd_start_t, mtx_t, mtx_init, mtx_lock, mtx_trylock, mtx_timedlock, mtx_unlock, mtx_destroy, mtx_plain, mtx_recursive, mtx_timed, call_once, cnd_t, cnd_init, cnd_signal, cnd_broadcast, cnd_wait, cnd_timedwait, cnd_destroy, tss_t, TSS_DTOR_ITERATIONS, tss_create, tss_set, tss_get, tss_delete, tss_dtor_t |
| <time.h> | Date and time | CLOCKS_PER_SEC, clock_t, time_t, struct tm, struct timespec, clock, time, difftime, timespec_get, timespec_getres, mktime, asctime_s, ctime_s, gmtime, gmtime_s, gmtime_r, localtime, localtime_s, localtime_r, strftime |
| <uchar.h> | Unicode utilities | char(8|16|32)_t, mbstate_t, mbrtoc(8|16|32), c(8|16|32)rtomb |
| <wchar.h> | Wide character utilities | wchar_t, size_t, mbstate_t, wint_t, struct_tm, NULL, WCHAR_MAX, WCHAR_MIN, WEOF, [f|s|vf|vs|v]wprintf, [f|s|vf|vs|v]wscanf, fgetw(c|s), fputw(c|s), fwide, getwc[har], putwc[har], ungetwc, wcsto(f|d|ld|l|ul|ll|ull), wcs[n]cpy, wmemcpy, wmemmove, wcs[n]cat, wcs[n]cmp, wcscoll, wcsxfrm, wmemcmp, wcschr, wcscspn, wcspbrk, wcsrchr, wcsspn, wcsstr, wcstok, wmemchr, wcslen, wmemset, wcsftime, btowc, wctob, mbsinit, mbrlen, mbrtowc, wcrtomb, mbsrtowcs, wcsrtombs |
| <wctype.h> | Wide character classification and mapping utilities | wint_t, wctrans_t, wctype_t, WEOF, iswalnum, iswalpha, iswblank, iswcntrl, iswdigit, iswgraph, iswlower, iswprint, iswpunct, iswspace, iswupper, iswxdigit, iswctype, wctype, towlower, towupper, towctrans, wctrans |