Introduction to Compilers

Programs, Interpreters and Translators
A program is a linguistic representation of a computation:
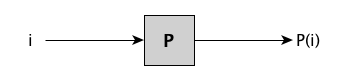
An interpreter is a program whose input is a program $P$ and some input data $x$; it executes $P$ on $x$:
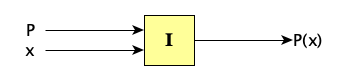
That is, $I(P,x) = P(x)$.
Interpreters can be implemented in hardware or software. For example, a CPU is a (hardware) interpreter for machine language programs.
The Universal Interpreter 🤯🤯🤯
The fact that there exists a single interpreter capable of executing all possible programs (those representable in a formal system) is a very deep and significant discovery of Turing’s. It was, and perhaps still, is, utterly mind blowing.
It’s too expensive (not to mention ridiculously difficult) to write interpreters for high-level languages, so we generally translate them into something more easily interpretable. A translator is a program which takes as input a program in some language $S$ and outputs a program in a language $T$ such that the two programs have the same semantics.
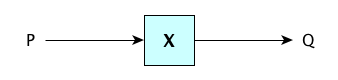
That is, $\forall x.\,P(x) = Q(x)$.
Some translators have really strange names:
- Assembler
- A translator from assembly language programs to machine language programs.
- Compiler
- A translator from “high-level” language programs into programs in a lower-level language.
- Transpiler
- A translator from high-level language programs into programs in a different high-level language.
If we translate the entirety of a program into something interpretable, we call this ahead-of-time (AOT) compilation. AOT compilers may be chained, the last of which is often an existing assembler, like this:

When we compile portions of a program while other previously compiled portions are running, we have just-in-time (JIT) compilation. JIT compilers will often remember what they already compiled instead of compiling the same source over and over again. They can even do adaptive compilation and recompilation based on runtime behavior.
It gets even more interesting
It actually isn’t true that compilation, whether AOT or JIT, is completely outside of your program. Many languages allow you to execute code during compilation time and compile new code at run time: think of macros in Julia or Clojure, Perl’s BEGIN block, or any language with the dreadedeval.
Writing Interpreters
Generally we write interpreters for simple, or low-level languages, whose programs tend to look like simple instruction sequences. As an example, let’s imagine a simple programming language for evaluating and printing the results of arithmetic expressions. Here are three example programs:
8 P2 3 + N P3 1 + P 0 15 * 100 25 2 * / P P
When you see a number, you push it on a stack. N negates the number on top. +, -, *, and / pop the two top elements, apply the operation, and push the result. P pops the value and prints it.
Before we implement the interpreter, execute the three programs above by hand so you understand the operation.
You did the classwork, right? Great! Now let’s write an interpreter:
function interpret(program) {
const stack = []
function push(x) {
stack.push(Number(x))
}
function pop() {
if (stack.length === 0) throw 'Not enough operands'
return stack.pop()
}
for (const token of program.trim().split(/\s+/)) {
let x, y
if (/^\d+(\.\d+)?$/.test(token)) push(token)
else if (token === 'N') (x = pop()), push(-x)
else if (token === '+') (y = pop()), (x = pop()), push(x + y)
else if (token === '-') (y = pop()), (x = pop()), push(x - y)
else if (token === '*') (y = pop()), (x = pop()), push(x * y)
else if (token === '/') (y = pop()), (x = pop()), push(x / y)
else if (token === 'P') (x = pop()), console.log(x)
else throw 'Illegal Instruction'
}
}
Since the interpreter is a JavaScript program, you can just copy-paste it into your browser’s console and invoke the function on any “program” of your choice, for example interpret("8 P").
Writing Translators
When thinking about more sophisticated languages, we generally go through layers of translation before getting things down to something simple enough to interpret. That’s fine, but we need to think deeply about what translation even is before attempting to implement a translator.
Translation Phases
First something inescapably true: translation consists of analysis and generation phases.

There are two reasons for this:
- We can’t really do it any other way. Word for word translation just doesn’t work.
Exercise: Give the most outrageous example you can think of where word-for-word translation between two natural languages comes out “so wrong.”
- It makes good engineering sense: if we need to write translators for $M$ source languages and $N$ target languages, we need only write $M + N$ simple programs (half-compilers) rather than writing $M \times N$ complex programs (full-compilers).
In practice it is rare for a conceptual representation to exist that is expressive enough and powerful enough to capture every imaginable source language and every imaginable target. Some systems do manage, at least, to get a lot of the common ones.
Natural Language Translation
How successful is machine translation for natural languages? Might it work best when the two languages are close cousins or siblings in an evolutionary language tree? Whether or not that’s the case, it’s often illuminating to play translation telephone. Here is one run I made using Google Translate:
- (English) She's feeling under the weather so will work from home today, with a laptop and cup of tea
- (Afrikaans) Sy gevoel onder die weer so sal werk van die huis af vandag, met 'n skootrekenaar en koppie tee
- (Hindi) वह मौसम के अंतर्गत महसूस किया तो एक लैपटॉप और एक कप चाय के साथ आज घर से काम करेंगे
- (Bulgarian) Той не се чувства добре с лаптоп и чаша чай ще работят от дома си днес
- (Filipino) Hindi niya pakiramdam komportable sa isang laptop at isang tasa ng tsaa ay trabaho mula sa bahay sa araw na ito
- (Sudanese) Anjeunna teu ngarasa nyaman jeung laptop jeung cangkir tea gawe ti imah ayeuna
- (Kazakh) Ол бар ноутбук жайлы сезінетін жоқ, бір кесе шай бүгін үйден
- (Chinese) 他不舒服的感覺與筆記本電腦,從家裡杯茶今天的工作
- (Telugu) ల్యాప్టాప్ తన అసౌకర్యం, నేడు ఇంటి నుండి పని, టీ ఒక కప్పు
- (English) His discomfort with a laptop, working from home today, a cup of tea
With idioms, sayings, and slang, you only need two languages to get something funny (the following really happened on Google Translate, but has since been fixed):
- (English) later alligator
- (Arabic) تمساح بيلحقك اركضي ولي هبلة
- (English) A crocodile hit you with my knees
“Screenshot or it didn’t happen”:
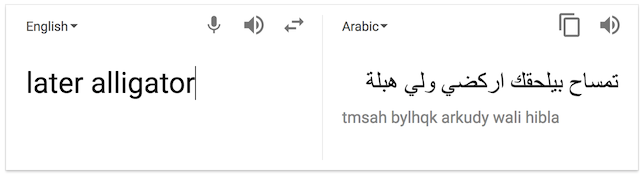
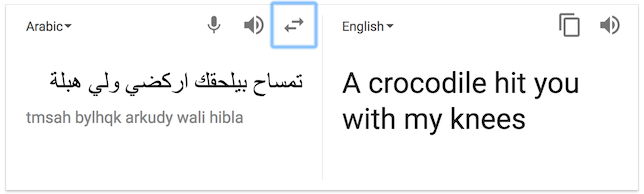
Machine translation for natural languages is getting much better. They use a lot of statistical methods, machine learning, dictionaries and lots of interesting techniques. We’re looking for great translations, because perfection is not always possible.
Fun read: Enjoy this article from December, 2016, about issues in natural language translation, and when computers started to get really good at it.
Programming Language Translation
Programming languages tend to be free of the ambiguities and nuances of natural languages, so translations can be in most cases 100% precise, and even formally verified. How do these systems look in practice? Decades of research into translation techniques have yielded some useful knowledge.
Compilers for programming languages go through a lot of phases, some have several dozen. In the so-called “classic compiler” (a standalone compiler that does everything from scratch), you tend to see the following major phases:
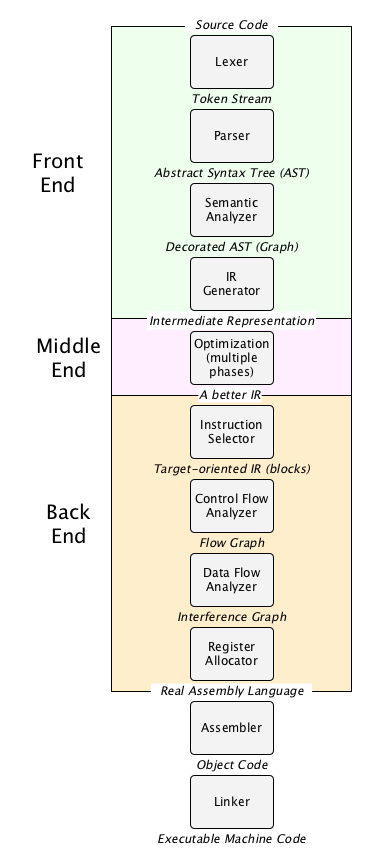
What do these phases look like in practice? Here’s a super-simplified example, just to get a taste for what is going on, using this C code:
#define ZERO 0
unsigned gcd( unsigned int // Euclid’s algorithm
x,unsigned y) { while ( /* hello */ x> ZERO
){unsigned oldx=x;x=y %x;y = oldx ;}return y ;}
Lexical Analysis
The lexer converts the source character stream into tokens. In doing this it needs to do things like remove comments, expand source-level macros, deal with indentation (for whitespace-significant languages like Python and Haskell), and remove whitespace. For the C code above, the lexical analyzer produces the token sequence:
unsigned
ID(gcd)
(
unsigned
int
ID(x)
,
unsigned
ID(y)
)
{
while
(
ID(x)
>
INTLIT(0)
)
{
unsigned
ID(oldx)
=
ID(x)
;
ID(x)
=
ID(y)
%
ID(x)
;
ID(y)
=
ID(oldx)
;
}
return
ID(y)
;
}
To build a token stream, lexers have to take into account case sensitivity, whitespace and newline significance, comment nesting, the actual source language alphabet, any weird limits on identifier lengths. They need to be able to detect whether character or string literals are unclosed, or whether a file ends while inside a comment. If a token stream cannot be formed, the lexer emits a lexical error.
Parsing
Next, the parser applies the grammar rules to the token sequence to produce the abstract syntax tree. In our running example, the AST is:
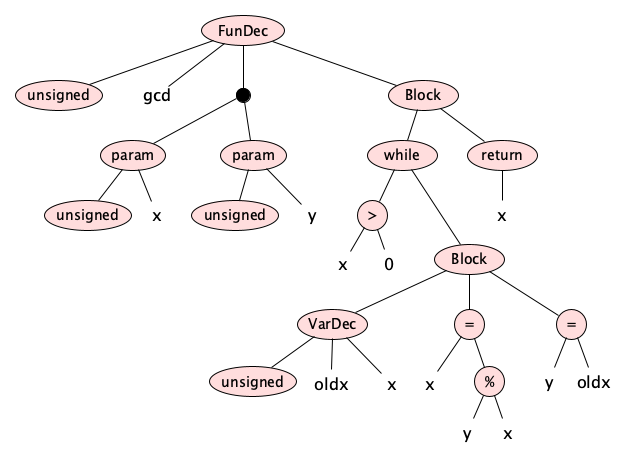
Parsers, like lexers, are often automatically generated from a grammar by special tools, called parser generators, but you can write them by hand if needed.
Errors that occur during parsing, called syntax errors arise from malformed token sequences such as:
j = 4 * (6 − x;i = /542 = x * 3
Static Analysis
Programming language grammars are almost always context free, so things like multiple declarations of a variable within a scope, referencing a variable before its (or without a) declaration, access violations, too many or too few arguments, or type checking failures, are checked after grammar matching, by the static analyzer. This produces the conceptual representation of the front end, which for our running example, is:
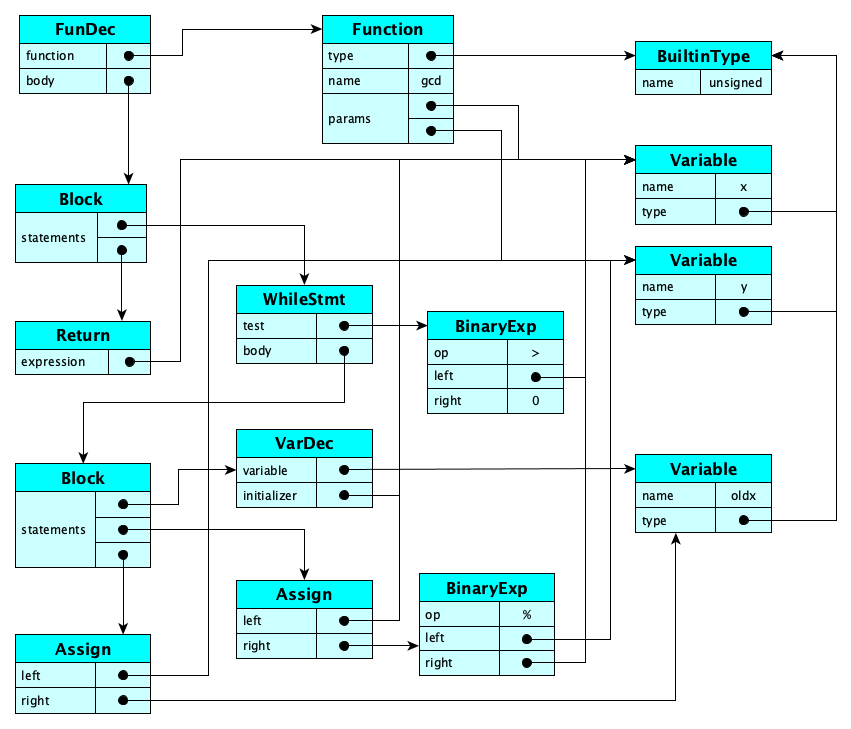
Intermediate Code Generation
Usually, an intermediate code generator transforms the graph representation of the program into something “flatter” like an abstract instruction list. For our running example, something like:
L1: if x > 0 goto L2 oldx := x t1 := y % x x := t1 y := oldx goto L1 L2: return y
Here t1, t2, ... are virtual registers. At this stage of compilation, we assume an infinite number of these.
Also at this stage, we can look for an apply various optimizations such as constant folding and strength reductions.
Control Flow and Data Flow Analysis
The intermediate code is often broken up into chunks known as basic blocks and assembled into a flow graph. Here’s our example:
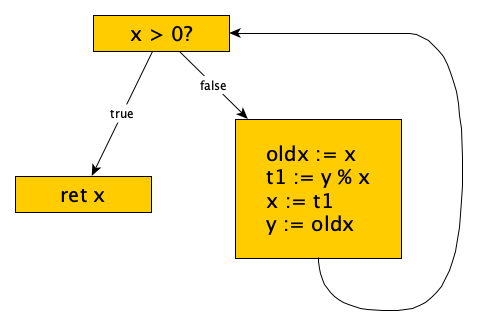
We use the flow graph for control flow and data flow analysis, which helps with fancier optimizations like copy propagation, dead code elimination, induction variable simplification, loop fission and fusion, and more.
Code Generation
Classic compilers target machines with limited registers and fancy instruction sets, which have all sorts of arcane conventions involving register usage, memory allocation to manage function calls, and so much more. Code generators need to have intimate knowledge of processor architecture, so they can generate good code. In practice, code generators can be tuned to produce raw code (that is as close as possible to the source code) or “optimized” code. Here is unoptimized and optimized code for our running example on the ARM processor:
gcd(unsigned int, unsigned int):
sub sp, sp, #32
str w0, [sp, 12]
str w1, [sp, 8]
.L3:
ldr w0, [sp, 12]
cmp w0, 0
beq .L2
ldr w0, [sp, 12]
str w0, [sp, 28]
ldr w0, [sp, 8]
ldr w1, [sp, 12]
udiv w2, w0, w1
ldr w1, [sp, 12]
mul w1, w2, w1
sub w0, w0, w1
str w0, [sp, 12]
ldr w0, [sp, 28]
str w0, [sp, 8]
b .L3
.L2:
ldr w0, [sp, 8]
add sp, sp, 32
ret
gcd(unsigned int, unsigned int): ; x in w0, y in w1
cbz w0, .L2 ; if x == 0 goto L2
.L3:
udiv w2, w1, w0 ; w2 := y / x
msub w2, w2, w0, w1 ; w2 := y mod x
mov w1, w0 ; y := x
mov w0, w2 ; x := w2
cbnz w2, .L3 ; if x != 0 goto top
.L2:
mov w0, w1 ; return y
ret
Compiler Writing in Practice
How simple is it to write a compiler?
Non-linearity of phases
If only each of the phases could be done one after the other! In many languages, they can, but others have design quirks, either intentional or not, that break the clean line. Brief examples:
- For example, in C, the expression
(x)-yhas two different syntactic interpretations: ifxrefers to a type, then it’s a cast of a negation, otherwise it is a subtraction. You can’t tell during parsing! - Many languages have “comptime” or sophisticated macros: ways in which code is supposed to be executed during compile time. Or maybe before.
Tooling
Now how many of these phases do people really write? Certainly not all of them, right? Aren’t there tools that can help?
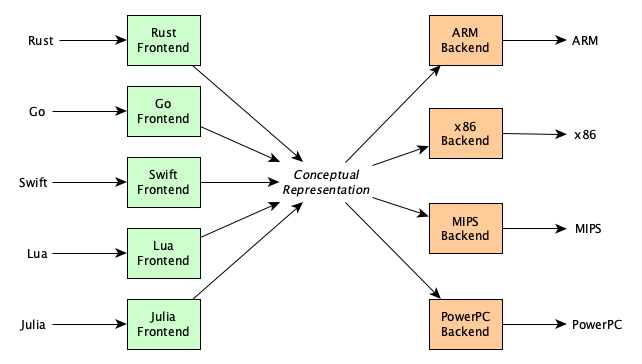
Unless you are a student or hobbyist looking for a deep understanding of compiler technology, you don’t duplicate all the hard work that people have already put into middle and back ends. Most people these days make their front end target the LLVM system, which supplies middle and backend functionality for a large number of architectures. LLVM is so popular these days that Andi McClure created a helpful diagram for y'all:
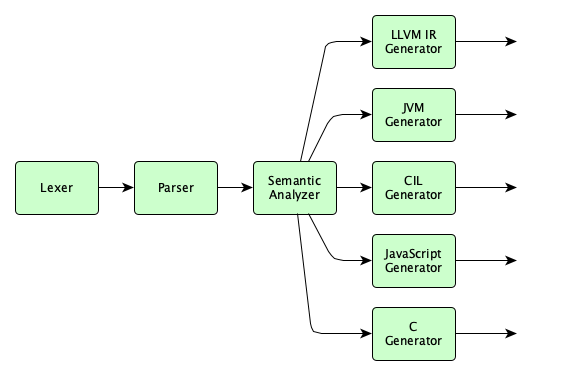
You don’t have to target LLVM of course. You can target other systems like JVM (the Java Virtual Machine) if you want to interoperate with the massive Java ecosystem, or CIL, an intermediate language on the .NET platform. Heck, you can even simply target C or JavaScript and take advantage of the amazing existing JavaScript engines and existing C compilers others have created already.
You might think just hitting C is the best. But why is LLVM so popular? LLVM is more than just a set of compiler phases, it’s a huge library of reusable components that allow all kinds of language processing. In fact, it’s generally preferable to use LLVM when implementing a language rather than simply translating to C:
... translate the input source to C code (or some other language) and send it through existing C compilers. This allows reuse of the optimizer and code generator, gives good flexibility, control over the runtime, and is really easy for front-end implementers to understand, implement, and maintain. Unfortunately, doing this prevents efficient implementation of exception handling, provides a poor debugging experience, slows down compilation, and can be problematic for languages that require guaranteed tail calls (or other features not supported by C). — Chris Lattner, from the LLVM chapter in The Architecture of Open Source Applications
Different types of compilers
There are three languages involved in translation: the source, the target, and the host. We show them in T-shapes, with source on the left, target on the right, and host below. Examples:
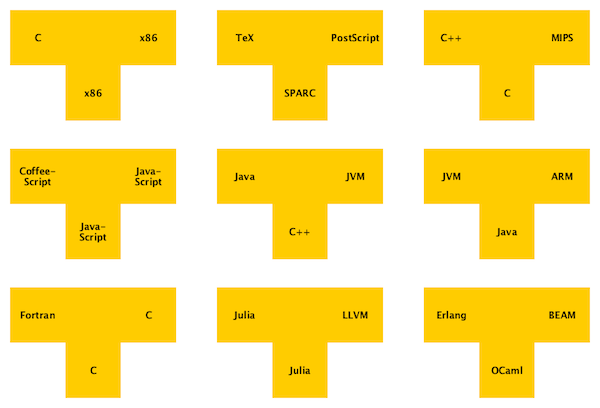
Here are three kinds of compilers you should learn to identify:
- Source language = Host language ⇒ Self compiler
- Target language = Host language ⇒ Self-resident compiler
- Target language ≠ Host language ⇒ Cross compiler
Real-life Examples
You’ll want to study existing compilers to get a feel for what’s involved. There are texts and tutorials about writing little languages, and there are real compilers for industrial-strength languages. Interested in the latter? Take a look at these:
- Rust. The Rust Playground (a.k.a. Rust Playpen). Type your code into a box and hit either the LLVM or ASM buttons.
- TypeScript. The TypeScript Playground. Your TypeScript code is compiled into JavaScript as you type!
- C, C++, Fortran, Ada, or any language compilable by GCC. Compile with
gcc -Sand view the generated assembly language in a.sfile. - Julia. Command line:
julia --output-bc hello.jlto see the LLVM. - Swift. Command line:
swiftc -emit-sil hello.swiftfor Swift Intermediate Languageswiftc -emit-ir hello.swiftfor LLVMswiftc -emit-assembly hello.swiftfor the assembly language
- Go. Command line:
go tool compile -S hello.goshows you the assembly language. - Java. Command line:
javap -c Helloshows you JVM code in the class fileHello.class.
And don‘t miss the AWESOME Compiler Explorer which does live translations from C++, Rust, Go, and D, to x86 assembly and machine code.
Compilers are not monolithic
Writing a traditional compiler will enter you into the elite club of compiler writers and make you feel accomplished. But remember: these days, compiler writing is more about language processing than building up that classic pipeline of phases, as explained in this video:
Why Should I Care?
Please do write a compiler! Writing a compiler will:
- Make you a better programmer in general, as you will better understand a language’s intricacies and obscurities. You will even start making sense of those ridiculous error messages from other people’s compilers.
- Help you write language tools such as preprocessors, linkers, loaders, debuggers, profilers, syntax highlighters, text formatters, code coverage analyzers, database query languages, and IDEs, or your very own command processors, message scanners, and more. Think you won’t ever write such things? A lot of people think that at first, but end up doing so.
- Improve your knowledge of many related technologies: generalized optimization tasks, advanced computer architectures, graphics interfaces, device controllers, virtual machines, and the translation of human languages.
- Make you a better computer scientist, because compiler technology spans so many areas of the discipline, including:
- Formal Language Theory
- Grammars
- Parsing
- Computability
- Programming Languages
- Syntax
- Semantics (both static and dynamic)
- Support for Paradigms (OOP, functional, logic, stack-based)
- Details of parallelism, metaprogramming, etc.
- Abstract languages and virtual machines
- Concepts, such as: sequencing, conditional execution, iteration, recursion, functional decomposition, modularity, synchronization, metaprogramming, binding, scope, extent, volatile, const, subtype, pattern matching, type inference, closures, prototypes, introspection, instrumentation, annotations, decorators, memoization, traits, streams, monads, actors, mailboxes, comprehensions, continuations, wildcards, promises, regular expressions, proxies, transactional memory, inheritance, polymorphism, parameter modes, etc.
- Computer Architecture
- Instruction sets
- RISC vs. CISC
- Pipelines
- Cores
- Clock cycles, etc.
- Algorithms and Data Structures
- Regular expressions
- Parsing algorithms
- Graph algorithms
- Union-find
- Dynamic programming
- Learning
- Software Engineering (because compilers are generally large and complex)
- Locality
- Caching
- Componentization, APIs, Reuse
- Synchronization
In other words, compiler writing is almost the perfect practical activity to bring the most fundamental theories of our discipline to life.
- Formal Language Theory
- Give you practice designing and building large systems, as you grapple with choices and weigh tradeoffs such as:
- Should I make a one-shot translator or make several layered independent “translation passes”?
- Should it be quick-and-dirty or take its time generating amazing (optimized) code?
- Should it stop at the first error? When should it stop? Should it...autocorrect?!
- What parts should I build myself and when should I use tools?
- Is retargetability important?
- Should I just write the front-end only (say, targeting LLVM, RTL, or the JVM)? Or maybe just do source-to-source transpilation to C or JavaScript? Or go all the way to assembly, or machine code?
- Make you a better language designer. People might not use your language, no matter how cool, if it can’t be implemented efficiently. You’ll learn the impact of type systems, preprocessors, garbage collection and the like on both compile-time and run-time performance.
- Give you cred in the Programming Languages Community. A compiler course is really just a Programming Languages II course. In Programming Languages I, you learn about specifying and using languages. In Programming Languages II, you learn about designing and implementing languages. Implementation is interpretation and translation.
- Give you cred on the street. “Woah, you wrote a compiler?!”
Convinced yet?
Some Good Reads
If you’re still a little nervous, here are some nice reads that might get you excited to write compilers because (1) they are cool, and (2) they might not be as hard to write as everyone thinks they are:
- Want to Write a Compiler? Just Read These Two Papers
- A Forgotten Principle of Compiler Design
- On the Madness of Optimizing Compilers
- Things That Turbo Pascal is Smaller Than
In addition, please browse this nice list of resources and select a few items from it for self-study.
Here’s a tutorial.
Should I Take A Compiler Class?
Good question. You are probably worried about lectures that look like this (found here):

Or maybe you are worried about following advice like these answers on StackExchange.
Don’t worry. It doesn’t have to be this way. You will learn by doing. With your friends. Here’s a testimonial from a successful alum:

Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- What is a program? A linguistic representation of a computation.
- What is an interpreter? A program that executes a program on some input data.
- What is a translator? A program that translates a program in one language to a program in another language, such that the meanings of the programs are the same.
- What is a compiler? A translator that translates high-level language programs into lower-level language programs.
- Name two kinds of translators other than a compiler. An assembler and a transpiler.
- Describe the difference between assemblers, compilers, and transpilers. An assembler translates assembly language to machine language; a compiler translates a anything into anything, but usually a high-level language into something lower level; a transpiler translates one high-level language into another high-level language.
- What is the difference between AOT and JIT? AOT translates the entire program before execution, while JIT translates portions of the program while other portions are running.
- What are informal names for a compiler’s front end and its back end? The front end is the analyzer and the back end is the generator.
- What are the two main reasons translators split into analyzers and generators? Because (1) analysis into some conceptual representation is an inherent (inescapable) part of translation and (2) it makes good engineering sense by separating concerns and drastically reducing the effort into writing multiple translators.
- What happens in the “middle end” of a compiler? Optimization.
- What are the three forms of analysis of the compiler front-end?
- Lexical Analysis (tokenization)
- Syntax Analysis (parsing)
- Contextual Analysis (static, semantic)
- What happens in lexical analysis? The source character stream is converted into tokens.
- What happens during parsing? The grammar rules are applied to the token sequence to produce a syntax tree.
- What is the difference between a lexical error and a syntax error? A lexical error occurs when a token stream cannot be formed, while a syntax error occurs when the token sequence is malformed.
- What happens during static analysis? Context-free grammar rules are applied to the internal program representation (usually an AST) to check for errors.
- What is the difference between a syntax error and a static semantic error? A syntax occurs when the program (after tokenization) cannot be derived by the grammar. A static semantic error occurs when the program is correctly matched by the grammar, but the compiler is able to deduce a violation of a legality rule, such as a type mismatch.
- What is (usually) meant by intermediate code generation? The graph representation of the program is transformed into an abstract instruction list.
- What are basic blocks? Chunks of the intermediate code that are broken up and assembled into a flow graph.
- What does a control flow graph look like? A graph representation of the program that shows the flow of control.
- What is a self-hosting compiler? A compiler written in the same language it compiles (i.e., the host language is the same as the source language).
- What is a cross-compiler? A language in which the host and target languages are different (i.e., it runs on one machine but generates code for a different machine).
- Give two reasons why compilers are often written in the language they compile. 1. It helps in the process of porting a compiler to a new architecture. 2. If the compiler is an optimizing compiler, it can optimize...itself!
- What is the really, really popular middle- and back-end compiler infrastructure called? LLVM.
- Who was the initial creator of LLVM? Chris Lattner.
- What is LLVM? A set of tools to help you write compilers, perhaps the most visible feature of which is its intermediate representation to which many popular programming languages have been targeted to, and for which many code generators for popular computer architectures have been produced.
- What is the JVM? A virtual machine that runs Java bytecode. Java bytecode is a hugely popular; compilers for dozens of different languages have been written to produce it.
- Why might one use LLVM as a compiler target instead of just targeting C? LLVM is much richer than C in that it natively supports exceptions, coroutines, and atomic operations (among others). It also support JIT compilation.
- How has compiler technology changed since the first edition of Dragon Book came out? There is now more focus on language processing than building up the classic pipeline of phases.
- Name five reasons why writing a compiler is likely to positively impact your career. Writing a compiler will make you a better programmer, help you write language tools, improve your knowledge of related technologies, make you a better computer scientist, and give you practice designing and building large systems.
- What has traditionally scared people away from taking compiler construction courses? The fear of lectures that look like the one shown in the image.
Summary
We’ve covered:
- What a program is, what an interpreter is, and what a compiler is
- The difference between AOT and JIT compilation
- Why translation has analysis and generation phases
- A simplified architecture of a classic compiler
- Real compilers often use pre-existing solutions for their middle and back ends
- Places you can go to study and experiment with real compilers
- Many good reasons to learn about compilers and write your own