Code Improvement
Motivation and Goals
We want a compiler to produce good code, at least we usually do. We may wish to “optimize” one or more of:
- Program size
- Program speed
- Resource usage (page swaps, caches, file handles, threads, etc.)
General optimization is undecidable, and many specific optimization tasks happen to take provably exponential time or are NP-Hard. So we normally speak of code improvement.
The general rule is to do those things that give the most improvement for the least amount of work, so for instance, you might see compilers that don’t bother doing any improvement outside loops. Still, there are different degrees of optimization aggressiveness:
- No improvements at all
- Only few basic simplifications on AST nodes, program graphs, or tuples (peephole optimization)
- Attempt near-optimal code within basic blocks (by removing redundancies like common subexpressions, doing smart instruction scheduling and register allocation, etc.)
- Intraprocedural optimization (improving across basic blocks, but still within a function, e.g., loop optimization using data flow analysis)
- Interprocedural optimization
Ideally, optimizations should satisfy two criteria:
Safety
The optimized code does the “same thing” as before
Profitability
The optimized code is actually smaller or faster
but as we’ll see, unsafe and unprofitable optimizations are sometimes done in practice.
Where Can Optimization Be Done?
There is no single optimization phase in a compiler. You improve code in many places:
- The programmer needs to find a better algorithm. Not many (if any) compilers can turn bubblesort into quicksort.
- The intermediate code generator can be smart about how it generates intermediate code.
- The compiler can make a pass or two or three (or more) over the intermediate code to improve it.
- The code generator can be smart, with clever instruction selection, by employing register tracking, etc.
- The compiler can make a pass or two or three over the target code to improve it.
- The run time system can adapt to the way a program is running, possibly recompiling and relinking on the fly.
- The programmer profiles the running code and finds out where the memory leaks and bottlenecks and excessive resource consumption are occurring, and rewrites the code accordingly.
Optimization Strategies
In general, you’ll try to:
- Use cheaper, more efficient operations
- Reuse results rather than recompute them
- Maximize the use of registers, caches, and memory
- Reduce the amount of code (e.g., remove dead and useless code)
- Reduce conditional jumps (they make branch prediction difficult)
- Optimize the use of pipelines and cores
But note the need for tradeoffs! You can get rid of some jumps by unrolling loops, but this makes more code.
A List of Optimization Techniques
Hundreds are known, but as Graydon Hoare points out in this most excellent presentation that you should study:

Here are some machine independent optimizations:
- Constant Folding
- Algebraic Simplification
- Operand reordering
- Strength reduction
- Unreachable Code Elimination
- Dead Code Elimination
- Copy Propagation
- Common Subexpression Elimination
- Loop Unrolling
- Loop Fission
- Loop Fusion
- Loop Inversion
- Loop Interchange
- Loop Invariant Factoring
- Jump Threading
- Induction Variable Simplification
- Tail Recursion Elimination
- Inline Expansion
And some we can call mostly machine independent optimizations:
- Efficient address computation
- Simplified stack frames
- Static allocation of frames
- Inlining
And some machine dependent optimizations:
- Careful instruction selection, using an understanding of specific register usage, caches, pipelines, branch prediction algorithms, scheduling rules, alignment requirements
- Smart register allocation
- Smart use of address modes
- Balancing across multiple CPUs
- Choosing CPUs vs GPUs for specific tasks
A Tour of Optimization Techniques
Learning-by-example time.
Constant Folding
Why wait until the target program is run to do simple computations? Let the compiler do it, directly on the program representation! Example:
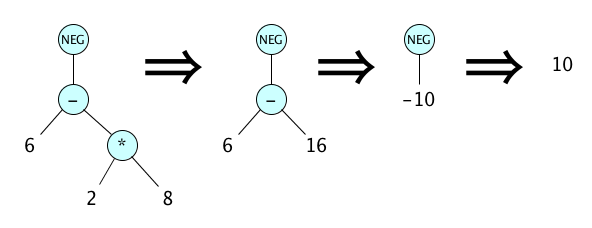
To save space on these notes, we’ll render or program representation trees as strings. The transformation above is more compactly written like this:
(NEG (- 6 (* 2 8)))
(NEG (- 6 16))
(NEG -10)
10
Algebraic Simplification
You can simplify expressions using algebraic identities such as replacing expensive operations with cheaper ones (known as strength reduction) or reordering operations to make evaluation more efficient on a target machine:
| Before | After |
|---|---|
| (+ x 0) | x |
| (- x 0) | x |
| (- x x) | 0 |
| (- 0 x) | (NEG x) |
| (+ x (NEG y)) | (- x y) |
| (- x (NEG y)) | (+ x y) |
| (* x 0) | 0 |
| (* x 1) | x |
| (/ x 1) | x |
| (/ x x) | 1 |
| (% x 1) | 0 |
| (% x x) | 0 |
| (/ 0 x) | 0 |
| (% 0 x) | 0 |
| (< x x) | false |
| (> x x) | false |
| (NOTEQ x x) | false |
| (EQ x x) | true |
| (<= x x) | true |
| (>= x x) | true |
| (AND x false) | false |
| (OR x true) | true |
| (NOT (NOT x)) | x |
| (NOT (<= x y)) | (> x y) |
| (>= (ABS x) 0) | true |
| (* x 4) | (SHL x 2) |
| (/ x 4) | (SHR x 2) |
You can even invent some powerful operations:
| Before | After |
|---|---|
| (+ (* x 90) y) | (MULADD x 90 y) |
| (AND (<= x 3) (>= x -10)) | (INRANGE x -10 3) |
By “inventing” powerful operations, we mean creating new program representation nodes representing operations that may not appear in your source language. That is, a language may not have INC, MULADD, INRANGE or a host of other operators, but during optimization there is nothing wrong with adding these new nodes! In fact, some can be created for the sole purpose of allowing better code to be generated.
Commutativity, associativity, and distributivity can both reduce the number of operations and do things like “put the more complex code on the left”:
| Property | Before | After |
|---|---|---|
| Commutativity | (+ x (- y z)) | (+ (- y z) x) |
| Associativity | (* x (* y z)) | (* (* y z) x) |
| Distributivity | (- (* x 5) (* y 5)) | (* (- x y) 5) |
Complex on the left simplifies register allocation on some machines.
But watch out: associativity and distributivity changes may not preserve overflow semantics.
$ swift
1> let x: Int8 = 70
x: Int8 = 70
2> let y: Int8 = 80
y: Int8 = 80
3> let z: Int8 = 30
z: Int8 = 30
5> (x + (y - z))
$R0: Int8 = 120
4> (x + y) - z
Execution interrupted. Enter code to recover and continue.
Enter LLDB commands to investigate (type :help for assistance.)
Assignment Simplification
As long as assignment doesn’t have hidden side-effects, you can do things like this:
| Before | After |
|---|---|
| (ASSIGN x x) | (NOP) |
| (ASSIGN x (+ x 1)) | (INC x) |
| (ASSIGN x (- x 1)) | (DEC x) |
| (ASSIGN x (+ x y)) | (+= x y) |
Beware of languages that allow for side effects or triggers to take place on assignment. For example Ada allows assignment triggers, and C++ allows you to overload the assignment operator. The optimizations above prevent those effects and triggers, hence those optimizations are strictly speaking unsafe.
Unreachable Code Elimination
If you can’t ever get to some code, don’t generate it:
| Before | After |
|---|---|
| (IF true T1 T2) | T1 |
| (IF false T1 T2) | T2 |
| (BLOCK T1 T2 RETURN T3 T4) | (BLOCK T1 T2 RETURN) |
| (WHILE false T) | (NOP) |
| (FOR i emptyrange T) | (NOP) |
Other general strategies:
- Remove all tuples after an unconditional control transfer (JUMP, RETURN, THROW), up to, but not including, the next LABEL.
- Remove all basic blocks with no predecessors
- Remove all private functions or methods that are never called
Dead Code Elimination
If a local variable or by-value parameter is assigned to but never subsequently used, you can delete the assignment. As usual, do this only if no implicit operations have side effects, and watch out for aliasing.
void f() {
int p = 5;
int* q = &p;
p = 3; // LOOKS LIKE DEAD CODE BUT IT IS NOT!!
cout << *q;
}
Copy Propagation
After an assignment x := y (i.e., (COPY y x)), replace all uses of x with y until such point that the values of x or y could be different. This might turn the copy into dead code which you can eliminate. Given the source code:
w := 4; a = w - 7 + (z * w)
then optimizing the program graph or AST proceeds as follows:
(BLOCK
(ASSIGN w 4)
(ASSIGN a
(+ (- w 7) (* z w)))
)
(ASSIGN a (+ (- 4 7) (* z 4)))
(ASSIGN a (+ (- 3) (* z 4)))
(ASSIGN a (- (* z 4) 3))
And with tuples:
(COPY,4,w) (MUL,z,w,t1) (SUB,w,7,t2) (ADD,t2,t1,a)
(MUL,z,4,t1) (SUB,4,7,t2) (ADD,t2,t1,a)
(MUL,z,4,t1) (COPY,-3,t2) (ADD,t2,t1,a)
(MUL,z,4,t1) (ADD,-3,t1,a)
(MUL,z,4,t1) (SUB,t,3,a)
Common Subexpression Elimination
If an expression appears multiple times, and its value cannot change between evaluations, then you can just evaluate it once:
| Before | After |
|---|---|
| x * 3 + x * 3 + 10 | _t = x * 3; _t + _t + 10; |
| a[i][j] = a[i][j] + 1 | _t = &a[i][j]; (*_t)++; |
CSE opens up opportunities for further optimizations, such as copy propagation and dead code elimination:
x = a[i]; a[i] = a[j]; a[j] = x;
_t0 = &a[i]; x = *_t0; _t1 = &a[j]; *_t0 = *_t1; *_t1 = x;
--After CP and DCE _t0 = &a[i]; _t1 = &a[j]; *_t0 = *_t1; *_t1 = *_t0;
Expressions that look common may not be, due to pointers, aliasing, references, arrays, etc.x = a[i] - 85; a[j] = 21; // a[i] is NOT common print(a[i]); // ... because maybe i == jIf your language has references, be very carefulx = j * 8 - y; q = 10; // Make sure you never had done c = j * 8 - y // ... something like int& q = j
Conditional Jump Tuple Compression
A naive translation into tuples for:
if (x < 3) { ... }
can be optimized like so:
| Before | After |
|---|---|
| (LT, x, 3, t0) (JZ, t0, L3) | (JGE, x, 3, L3) |
This can be very useful since the naive translation of the first tuple sequence to x86 assembly would be:
cmp x, 3 setl dl movzx eax, dl test eax, eax jz L3
and for the second:
cmp x, 3 jg3 L3
Loop Unrolling
Loops can have a performance issue, since time is required to execute those jumps, and conditional jumps can cause slowdowns because of the potential for branch misprediction.
| Before | After |
|---|---|
| for i in 1..4 { T } | i = 1; T; i = 2; T; i = 3; T; i = 4; T; |
| (FOR i (RANGE 1 4) T) | (BLOCK (ASSIGN I 1) T (ASSIGN I 2) T (ASSIGN I 3) T (ASSIGN I 4) T ) |
Loop unrolling is commonly followed by copy propagation!
for i in 1...4 {
print(i * 2)
}
i = 1; print(i * 2); i = 2; print(i * 2); i = 3; print(i * 2); i = 4; print(i * 2);
print(1 * 2); print(2 * 2); print(3 * 2); print(4 * 2);
print(2); print(4); print(6); print(8);
Look unrolling might conflict with cache issues, since the code is getting bigger.
Note: you can partially unroll, that works too.
Loop Fusion
Suppose you know that you had an array of structs:
struct {
int a;
int b;
} s[5000];
then two loops accessing the a’s and b’s independently could be fused into one to improve locality (and avoid destroying performance due to cache unloading and refilling):
| Before | After |
|---|---|
| for i in 0..<n { ... s.a[i] ... } for i in 0..<n { ... s.b[i] ... } | for i in 0..<n { ... s.a[i] ... ... s.b[i] ... } |
Loop Fission
Suppose you know that you had two parallel arrays in a struct:
struct {
int a[5000];
int b[5000];
} s;
then one loop that iterated both array could be split into two loops accessing the a’s and b’s independently to improve locality (and avoid destroying performance due to cache unloading and refilling):
| Before | After |
|---|---|
| for i in 0..<n { ... s.a[i] ... ... s.b[i] ... } | for i in 0..<n { ... s.a[i] ... } for i in 0..<n { ... s.b[i] ... } |
Loop Inversion
This interesting technique replaces a while loop with a do-while loop in an if statement, looking like this at the source code view (BUT DON’T REALLY DO THIS IN YOUR SOURCE CODE, LET THE COMPILER DO IT):
| Before | After |
|---|---|
| while (condition) { body } | if (condition) { do { body } while (condition); } |
This tends to generate better machine code, because there are fewer jumps. Here it is in tuples:
| Before | After |
|---|---|
| top: condition (JZ, bottom) body (JUMP top) bottom: ... | condition (JZ, bottom) top: body condition (JNZ, top) bottom: ... |
The last iteration of the loop has two jumps not taken in the optimized version compared to the unoptimized version. Pretty useful if this is a nested loop!
| For a loop executed n times |
Unoptimized Version | Optimized Version | |||
|---|---|---|---|---|---|
| Conditional Jumps | Unconditional Jumps Taken |
Conditional Jumps | |||
| Taken | Fallen Through |
Taken | Fallen Through |
||
| 0 | 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 | 0 | 2 |
| 2 | 1 | 2 | 2 | 1 | 2 |
| 3 | 1 | 3 | 3 | 2 | 2 |
| 4 | 1 | 4 | 4 | 3 | 2 |
| 5 | 1 | 5 | 5 | 4 | 2 |
| 100 | 1 | 100 | 100 | 99 | 2 |
Remember these are *compiler* optimizations
Don’t use the examples on this page as an example of how you, as a programmer, should be writing source code. The page discusses optimizations that a compiler can do for you. You (the programmer) are supposed to write clear, readable code. Let the compiler optimize. It’s generally much better at that than you are.
Loop Interchange
If you know that your matrices are laid out in row-major (as in C) or column-major (as in Fortran) order, and you detect that a matrix is being processed with nested loops in a manner that is opposite from the layout, and you can tell that the body of the loop is not modifying the matrix in any way dependent on the traversal order, you can switch the traversal order. Here is an example of switching from row order to column order:
| Before | After |
|---|---|
| for i in 0..<m { for j in 0..<n { ... a[i, j] ... } } | for j in 0..<n { for i in 0..<m { ... a[i, j] ... } } |
Loop Invariant Factoring
A loop invariant is an expression that is always the same for every execution of the loop. You might consider moving the evaluation of this expression just outside (just before) the loop, so that it evaluated only once. Example:
| Before | After |
|---|---|
| for i in 0..<n { for j in 0..<n { for k in 0..<n { a[i][j][k] = i * j * k } } } | for i in 0..<n { _t0 = a[i] for j in 0..<n { _t1 = _t0[j] _t2 = i * j for k in 0..<n { _t1[k] = _t2 * k } } } |
If t = 100, for example then:
- Without factoring: 3,000,000 array accesses and 2,000,000 multiplications
- With factoring: 1,010,100 array accesses and 1,010,000 multiplications
Factoring may be unsafe
You may factor an expression that throws an exception (or crashes), and if it does the exception would be thrown at the wrong place, perhaps before a side-effect which could completely change the program meaning.
A good compiler will only factor expressions it knows cannot throw.
Factoring may be unprofitable as well as unsafe
Factoring an invariant from a loop that is executed zero times causes unnecessary and potentially harmful execution of code that should not ever have been run.
Jump Threading
Sometimes a jump will land on a jump (or a throw or a return). Examples (for tuples):
| Before | After |
|---|---|
| (JGE, x, 3, L5) some code L5: (JUMP, L7) | (JGE, x, 3, L7) some code L5: (JUMP, L7) |
| (JGE, x, 3, L5) some code L5: (JGE, x, 2, L7) | (JGE, x, 3, L7) some code L5: (JGE, x, 2, L7) |
Here’s a nice Jump Threading article.
The basic idea of jump threading is to avoid conditional jumps that you know will always be taken or never be taken, and make sure they are never executed. The same theme appears in transformations such as these (at the AST level):
| Before | After |
|---|---|
| (BLOCK (IF c T1) (IF c T2)) | (IF c (BLOCK T1 T2)) |
| (BLOCK (IF c T1) (IF (NOT c) T2)) | (IF c T1 T2) |
Again, only perform these if you can prove execution of T1 will not affect c.
Induction Variable Simplification
An induction variable is any variable whose value is incremented by a constant each pass through the loop.
An induction expression has the form i*c1+c2 for induction variable i and invariants c1 and c2. You can get rid of the multiplication that it is the loop, replacing it with a much cheaper addition! Here’s an example:
| Before | After |
|---|---|
| for i in 1...n { a[i] = 80 * i + q } | _t = 80 + q for i in 1...n { a[i] = _t _t = _t + 80 } |
In general, replace induction expression i*c1+c2 by initializing a new variable to i0*c1+c2 and incrementing by s*c1 where s is the step size
Tail Recursion Elimination
A function that returns a call to itself can be transformed into a loop. The classic gcd example is:
| Before | After |
|---|---|
| function gcd(x, y) { if (y === 0) { return x; } return gcd(y, x % y); } | function gcd(x, y) { while (true) { if (y === 0) { return x; } [x, y] = [y, x % y]; continue; } } |
The continue is emitted just in case there is more code after the return, but of course if the optimizer can tell there is no code there, then it is unnecessary. Be careful that the return is not inside a nested loop!
With tuples, the transformation is like:
| Before | After |
|---|---|
| (JNZ, y, L2) (RET, x) (LABEL, L2) (STARTCALL, gcd) (PARAM, y) (MOD, x, y, t0) (PARAM, t0) (CALL, gcd, t1) (RET, t1) | (LABEL, L1) -- add this new label at the top (JNZ, y, L2) (RET, x) (LABEL, L2) (COPY, y, t0) -- compute new first param (MOD, x, y, t1) -- compute new second param (COPY, t0, x) -- load new first param (COPY, t1, y) -- load new second param (JUMP, L1) -- "call" by jumping to top |
For fun, here are the tail recursion elimination applications of Factorial (remember a should be primed with 1 here):
| Before | After |
|---|---|
| function fact(n, a) { if (n === 0) { return a; } return fact(n - 1, a * n); } | function fact(n, a) { while (true) { if (n === 0) { return a; } [n, a] = [n - 1, a * n]; continue; } } |
and Fibonacci (remember a and b should be primed with 0 and 1):
| Before | After |
|---|---|
| function fib(n, a, b) { if (n === 0) { return a; } return fib(n - 1, b, a + b) } | function fib(n, a, b) { while (true) { if (n === 0) { return a; } [n, a, b] = [n - 1, b, a + b]; continue; } } |
Inline Expansion
Inlining saves the overhead of a function call at runtime. In practice it often exposes many other optimizations. Here’s a trivial example to show the basic idea, where we inline the body of g into the point in f where it is called. (If this is the only call to g, or we inline all calls to g, then we don’t have to generate a separate function for it at all):
| Before | After |
|---|---|
| function g(x, y) { let z = x * y; console.log(z / 5); return z + 1; } function f(x) { if (x > 0) { console.log(g(10, x)); } return 1; } | function f(x) { if (x > 0) { let __g_x = 10; let __g_y = x; let __g_z = __g_x * __g_y; console.log(__g_z / 5); let __g_returnValue = __g_z + 1; console.log(__g__returnValue); } return 1; |
You should inline when the function is:
- Called only once in the program text
- Extremely small. Obvious candidates are those ridiculous getter methods like
int getX() { return x; }in Java and C++.
You should strongly consider inlining when the function is:
- Frequently called at runtime (i.e., called in a loop)
You probably don’t want to inline
- Recursive functions, but you can partially expand them (kind of like partial loop unrolling)
Further Reading
There’s nothing wrong with starting at the Wikipedia page for compiler optimizations and clicking from technique to technique to technique and getting lost and absorbed in this incredibly cool subdiscipline of compilers.
Also see Wikipedia’s Compiler Optimizations Category Page
For low level good stuff, see Agner Fog’s Software Optimization Resources
Thinking about these topics is good. It might help you see computation in a new way.
Also, read whatever you can about Fran Allen, the 2006 Turing Award winner who did so much of the seminal work in optimizing compilers.
Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- What kinds of measures do we try to improve during ”code optimization”? Size, speed, and general resource usage.
- Why do we often speak of code improvement instead of optimization? Optimization in general is undecidable or at least intractable. In practice, many optimizations are not strictly optimal, just better.
- What is the difference between intraprocedural and interprocedural optimization? Intraprocedural optimization happens within a single function or method, interprocedural optimization happens across function or method boundaries.
- What are the two main criteria for a good optimization? Safety and profitability.
- What is a safe optimization? One that preserves program semantics.
- What is a profitable optimization? One that improves some measure of program performance, such as speed or size.
- What is constant folding? Evaluating constant expressions at compile time rather than runtime.
- What is strength reduction? Replacing expensive operations with cheaper ones.
- What kinds of algebraic simplifications can be made during optimization? Commutativity, associativity, distributivity, identity elements, annihilating elements.
- What is copy propagation? Replacing uses of a variable with the value it was assigned, when safe to do so.
- What is common subexpression elimination? Evaluating an expression once and reusing the result when the same expression appears again, if its value cannot change in between.
- What is loop unrolling? Expanding the loop body multiple times to reduce the number of iterations and conditional jumps.
- Can loop unrolling ever be unsafe? Why or why not? Yes, if the loop body has side effects that depend on the number of iterations, unrolling could change program behavior.
- What is loop fusion? Combining multiple loops that iterate over the same range into a single loop to improve cache locality.
- What is loop fission? Splitting a single loop into multiple loops to improve cache locality by accessing independent arrays separately.
- What is loop inversion? Transforming a while loop into a do-while loop preceded by a conditional check to reduce jumps, especially in nested loops.
- What is loop interchange? Switching the order of nested loops when the traversal order doesn't match the memory layout of data structures.
- What is loop invariant factoring? Moving expressions that don't change during loop iterations outside the loop to evaluate them only once.
- Why can loop invariant factoring be unsafe? An expression being factored out might throw an exception or have side effects that would occur at the wrong point in program execution.
- What is jump threading? Redirecting jumps that land on other jumps to jump directly to their final destination, reducing unnecessary conditional branches.
- What is an induction variable? A variable whose value is incremented by a constant amount on each iteration of a loop.
- What is induction variable simplification? Replacing expensive multiplications in induction expressions with cheaper addition operations by tracking variable increments.
- What is tail recursion elimination? Transforming a function that returns a recursive call into a loop to eliminate function call overhead.
- What is inline expansion? Replacing a function call with a copy of the function's body to eliminate call overhead and expose further optimizations.
- When should you strongly consider inlining a function? When the function is frequently called at runtime, such as inside loops, or when it's extremely small like a getter method.
- Why is inlining often more beneficial than just removing function call overhead? It exposes the inlined code to further optimizations that wouldn't be possible across function boundaries.
- What is unreachable code elimination? Removing code that can never be executed, such as code after an unconditional return or the body of a while loop with a false condition.
- What is dead code elimination? Removing assignments to variables that are never subsequently used, provided the assignment has no side effects.
Summary
We’ve covered:
- Motivation
- Where optimizations happen in a compiler
- What we try to optimize
- A whole bunch of techniques
- Where to learn more