Secure Coding Constructs
Goals
Building secure software needn’t be any harder or take any longer than building insecure software. With training and disciplined practice, programmers will:
- Develop a security-built-in mindset
- Be able to use tools and best practices for vulnerability prevention
- Be able to spot weaknesses in code
Secure Programming Best Practices
Developers must (1) know technology-specific risks and weak points in the software, and (2) program carefully (and defensively) to make the software as secure as possible. There are plenty of style guides and collections of security guidelines out there from consortiums, private companies, governmental agencies, non-governmental organizations, or even individuals publishing their own blog articles or course notes. Some are language-specific and some are general. Some are super famous, like the CWE and the OWASP Projects.
While there are hundreds of secure coding guidelines (remember CERT-C, CERT-C++, CERT-Java, OWASP), these notes focus on six extremely general programming principles that help maintain confidentiality, integrity, and availability. They apply to most if not all programming languages:
Manage Sharing
Avoid unintended sharing by using immutable objects, defensively copying, or preventing copying
Define Contracts
Modules and functions should maintain integrity through preconditions and postconditions
Control Failures
Handle failures securely so state does not get corrupted
Validate Everything
Validate callers, inputs, and the current context
Reduce Complexity
Complexity is the enemy of security (as someone once said)
Tighten Visibility
Design for least privilege and don’t leak anything
Immutability
Ah, immutability, often a programmer’s best friend. When used properly, this idea can improve correctness, efficiency and security. How so? Since immutable objects can not be changed:
- They can never get (accidentally or maliciously) corrupted
- We never have to make copies (in fact, we just need one per value!)
- We can safely share them in function calls or across threads—No locking, no blocking!
- It’s impossible to “forget” to re-validate on change
No surprise errors from things changing out from under you, no race conditions, less memory required, programs running faster without copies. Faster means less waiting and fewer timeouts. Sounds good! How do we do this?
Immutable Variables vs. Immutable Objects
First, be very clear what you mean by immutable. It’s contextual. An immutable variable cannot be reassigned; an immutable object cannot have any of its properties reassigned (nor can you add properties, remove properties, nor reconfigure it in any way by making properties writable).
Here is a JavaScript example of an immutable variable holding a mutable object:
const a = [1, 2, 3] a[1] = 55 // This is legal! console.log(a) // prints [1, 55, 3]a = [] // NOT legal, throws a TypeErrorconsole.log(a) // still prints [1, 55, 3]
How can we make objects immutable? This varies from language to language.
JavaScript
Given an object x, invoke Object.freeze(x). Freezing an object:
- Prevents adding any new properties from being added to the object
- Prevents any properties from being deleted
- Prevents getter properties from being anything but getters
- Prevents setter properties from being anything but setters
- Makes all data properties non-writable
- Freezes the status of the enumerable attribute
Normally, you place Object.freeze(this) at the end of constructors.
$ node --use-strict
> class Point { constructor(x, y) {this.x=x; this.y=y; Object.freeze(this)} }
> let p = new Point(3, 5)
> p.x = 2
Uncaught TypeError: Cannot assign to read only property 'x' of object '#<Point>'

Java
In a class, make each field private and final. You can use a record, which automatically makes the fields private and final.
$ jshell
| Welcome to JShell -- Version 16.0.1
| For an introduction type: /help intro
jshell> record Point(double x, double y) {}
| created record Point
jshell> var p = new Point(3, 5)
p ==> Point[x=3.0, y=5.0]
jshell> p.x()
$3 ==> 3.0
jshell> p.x = 100.0
| Error:
| x has private access in Point
| p.x = 100.0
| ^-^

Python
Many of the built-in types of Python are already immutable: all the numeric types are, as are bool, str, bytes, tuple, frozenset, and range. (A few are mutable, including list, set, dict, and bytearray.)
If you want to create a type of your own that produces only immutable objects, check out this StackOverflow question and several of its answers for various approaches. TL;DR you want namedtuple.
Here’s the normal, mutable form of a user-defined class:
$ python >>> import math >>> class MutablePoint: ... def __init__(self, x, y): ... self.x = x ... self.y = y ... def distance_to_origin(self): ... return math.hypot(self.x, self.y) ... >>> p = MutablePoint(-4, 3) >>> p.x -4 >>> p.y 3 >>> p.distance_to_origin() 5.0 >>> p.y = 23 >>> p.distance_to_origin() 23.345235059857504 >>> type(p) <class '__main__.MutablePoint'> >>> isinstance(p, MutablePoint) True >>> type(MutablePoint) <class 'type'>
Now, let’s use namedtuple to make immutable points:
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> type(Point)
<class 'type'>
>>> p = Point(x=3, y=5)
>>> type(p)
<class '__main__.Point'>
>>> isinstance(p, Point)
True
>>> p.x
3
>>> p.y
5
>>> p.x = 2
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: can't set attribute

PHP
I don’t know PHP well enough, but I could not resist the opportunity to include a screenshot from my favorite blog, Melissa Elliott’s PHP Manual Masterpieces:

Persistent Data Structures
There are languages in which all (or almost all) objects are immutable. Wait what? ALL objects? Okay some lists and trees can be immutable, but what if we want to keep track of data that grows and shrinks at runtime? How would we add to a list? Insert into a tree? Remove an element from a set? Replace a value in a dictionary?
If these structures are immutable, YOU DON’T! Add, delete, and update operations return a new data structure! Adding to a list returns a new list. Inserting into a tree returns a new tree. Removing an element from a set returns a new set. Even replacing (updating) returns a new object. More formally:
add_to_front([3, 5, 7], 1) ==> [1, 3, 5, 7]
add_to_set(3, {5, 1}) ==> {5, 3, 1}
update({'x': 1, 'y': 3}, 'y', 10) ==> {'x': 1, 'y': 10}
delete({7, 3, 2, 1}, 3) ==> {1, 7, 2}
If we return a new structure, the old one still hangs around; we have what are called persistent data structures. But is it efficient to keep the old ones around? What do you think happens here?
a = make_persistent_list_with_filled_value("dog", 50)
b = add_to_front(a, "cat")
print(a)
print(b)
Do you think we copy all the nodes of list a? Actually no, the add_to_front operator is efficient. This happens:
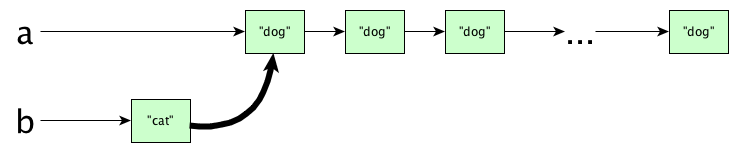
But, but, aren’t a and b sharing internal data? What would happen if we mutate a? Wouldn’t b get mutated too? Isn’t this bad?
ANSWER: Calm down, we are talking about immutable data structures, remember?. Since both a and b are immutable, their contents can’t change, so this sharing is quite alright.
We’re going to do successive insertions and deletions on a the binary search tree on a whiteboard. It will be fun. Also, we’ll discuss advantages and disadvantages of these things. Surely immutability has advantages, but do they outweigh the cost of the extra storage needed to support them?
You do need to be aware of these inner workings, because efficiency matters. Inserting at the front of a list is fine, but appending to the end is a totally different story: the assignmentb = a.append("cat")would need a complete (and expensive) copy ofa, provided we actually usedaorblater.
Non-extensibility
Just a quick note: related to the idea of immutability is the idea that in some languages you can lock-down more than just objects. In Java, for example, you can make methods final, meaning they can not be overridden in subclasses, and classes final, meaning they can not be subclassed.
If you can’t have immutability...
Sometimes you need mutable data, right? Of course. Not every language will give you persistent data structures; in fact well over 99% are going to let you mutate. It’s simpler! If you do use mutable structures, though, you need to manage and control these objects. Don’t share them on different threads. Don’t accept them from untrusted sources, and don’t leak them to untrusted targets. What programming constructs should you employ to do these things?
- Ensure all mutable components are encapsulated and accessed and modified only by methods; never expose a mutable field directly.
- If the language allows it, prevent copying! For example, in C++, you can make the copy constructor and the assignment operator
private. - If it is not possible to prevent copying, do defensive copying. If a mutable component is initialized by an object of the same type, or is supposed to be sent out, it should be copied on the way in and copied on the way out.
Design by Contract
Ensure that each function, each method, each module, each operator, each everything states precisely:
- What must be true before being called (Preconditions)
- What arguments it must take
- What is guaranteed to be the case while running (Invariants)
- What is true when at the end (Postconditions)
Writing good contracts takes some skill. You need to write these at the right level of abstraction.
Some languages allow contracts to be written declaratively.
- Static typing is a kind of precondition, right?
- Check out dependently-typed languages, woah
- Eiffel allows some crazy complex constraints to be written declaratively
Validation
Techniques like using immutable objects and employing languages with static program analysis tools detect possible errors before the program is ever run, they can’t check everything. Errors may still happen at run time. Validation is the checking for problems at run time. During validation, you can either reject (preferred) or sanitize (only if you know what you are doing and then only 0.00000000001% of the time) input.
There are three broad categories of validation
Validate Callers
Is this caller allowed to do this?
Validate Inputs
Does this parameter make any sense?
Validate State
Can this operation be done now (in the current context)?
The general approach is:
- At the beginning of an operation, make sure objects are in the proper state to carry out the operation (i.e., that all preconditions are satisfied). For example, in an add operation for a container, make sure the container isn’t already full.
- Also at the beginning, validate the inputs (the arguments) entering the system, as they cannot be trusted. For example, don’t accept negative quantities, null things, objects that are too large, or malformed things.
- During the operation, ensure any internal consistency rules or other invariants do not get violated.
- On exit, check that all postconditions are satisfied.
There are three best practices for validation:
- Validate in a meaningful order
- Validate in the domain model
- Validate in an assertion style
Whitelisting and Blacklisting
A whitelisting approach “enumerates” (possibly with patterns) which inputs are valid and a blacklisting approach says which ones will be rejected. In practice you might use a combination of both. Probably you want to start with a whitelisting approach where possible.
Ordering Validations
Why do we validate in a specific order? It’s more important that you might think. Layer the validation so that the easiest checks come first, so you might not even need to get to the expensive checks.
Here’s a way to approach validation. What do we validate? We validate operations. When an operation is called, we validate the (1) source, the (2) requestor, the (3) context, and the (4) operands. In more detail, the order is generally:
- ORIGIN Is the request coming from a legal source/sender?
Many requests are tagged with an origin, or source (can be an IP address in a network-based application, or a requesting object or module can be tracked even in a single application). Certain origins can be whitelisted or blacklisted, often with the help of security groups, virtual private clouds (VPCs) or access control lists (ACLs). Origin checks happen before you even read the data!
- AUTHENTICATION Is the caller properly authenticated (who they say they are)
Caller may be required to present valid credentials, or a valid access key, or a valid token. Keys and tokens should generally be signed, and the signature has to be verified against a secret, and must not be expired, etc.
Admittedly, there is a fine line between origin checks and authentication checks, but basically origin checks are done outside of your app (either on the router or some kind of gateway), while authentication checks are normally done in-app, albeit well factored out into some nice middleware.
- AUTHORIZATION Does the caller have permission to do this operation?
It is often important to set up a permission system for every operation. Permissions can be things like CanDeleteRecord, CanUpdateTaskMetadata, CanCreateUser, etc. There can be tens of thousands of these in large systems. Sometimes we group big sets of permissions into user roles.
- STATE Is the system in a state in which operation can even be called?
You should not push onto a full stack, nor pop from an empty stack, nor initialize something that has already been initialized, nor send a message over a connection that has not been established, nor pause a thread that is not already running, nor close a file that has not already been opened.
- SIZE Is an argument negative, zero, too small, too large?
Negative quantities or prices can mess up an e-commerce application, and massive data payloads can cause a denial of service. PUT BOUNDS ON ALL THE THINGS.
Sometimes do a size check even if a regex subsumes it. If you are taking in SSNs or ISBNs or custom IDs of any kind with a known length, check the length first before even engaging the regex engine.
- LEXICAL Is an argument lexically well-formed?
Usually these are quick checks, e.g., is the data from the right character set, is the encoding valid (e.g., some byte sequences are not valid UTF-8). Regex matching is common here. Oh, and if you are taking in XML, don’t expand entities. In general, whatever you are taking in, make sure it can’t be executed. Don’t allow injection attacks of any kind!
- SYNTACTIC Is and argument syntactically well-formed?
These checks often require parsing, though you may get away with a simple checksum or hash computation.
- SEMANTIC Is and argument semantically well-formed?
These checks apply formal business rules, which are often programmatic in nature and might have to hit external resources like databases.
Some of these concerns may appear to overlap a little, but that’s fine.
The ordering of state and semantic can be messy. If state validation requires a database lookup, do it last. Only do early state checks on in-memory objects.
Validating In the Domain Model
Define constraints within an object where possible; it’s generally better for an object to check itself (or better, not even get created in a bad state). Example: use a UserId class, rather than passing around user ids as strings. All legality rules on these ids are managed inside the UserId class, never elsewhere.
This is a powerful idea because:
- It is easier to put the same validation checks in constructors and mutators if it is all localized in a class
- It’s easy to deal with things like what is required and what is optional in the model. For example, the fact that a person must have an id but need have a supervisor is better to capture in the Person class rather than having notNull checks spread all over the rest of the code base.
Validating without if-statements
One way to validate is to pollute your code with a whole bunch of if-statements all over the place checking for this and that and every little thing. This is bad because it clutters the code and focuses on the negative cases...sometimes leading you to write with double negatives. These are BAD:
void searchPhotos() {
if (!loggedIn()) {
throw new AuthenticationError("Not logged in");
}
// do the search ...
}
void chooseItems(int quantity) {
if (quantity < 1) {
throw new IllegalArgumentException("Too small");
} else if (quantity > 50) {
throw new IllegalArgumentException("Too big");
}
// choose the items ...
}
Better is to be more positive, using a validator (which internally can throw), something like:
void searchPhotos() {
Validate.loggedIn();
// do the search ...
}
void chooseItems(int quantity) {
Validate.inInclusiveBounds(1, 50, "Quantity is out of range");
// choose the items ...
}
We can still do so much better!! We could use a decorator:
@Authenticated
void searchPhotos(Query query) {
// do the search ...
}
and we can encapsulate type and bounds checks inside a domain object (here the Quantity class ensures that quantity objects can’t even represent values out of the accepted range):
void chooseItems(Quantity quantity) {
// choose the items ...
}
These are powerful ideas.
Try to come up with good names for your validation functions. Some examples:
Validate.isNotNull(expression) Validate.isTrue(expression) Validate.matchesPattern(pattern, expression) Validate.isGreaterThan(threshold, expression) Validate.isLessThan(threshold, expression) Validate.isInclusivelyBetween(low, high, expression) Validate.isExclusivelyBetween(low, high, expression) Validate.isNotEmpty(expression) Validate.isNotFull(expression)
Don’t be afraid of writing validations that are highly domain-specific! In a compiler, you might validators like:
isNumeric isNumericOrString isBoolean isInteger isAType isAnOptional isAnArray hasSameTypeAs allHaveSameType isNotRecursive isAssignableTo isNotReadOnly areAllDistinct isInTheObject isInsideALoop isInsideAFunction isCallable returnsNothing returnsSomething isReturnableFrom matches matchesParametersOf matchesFieldsOf
Sanitizing Inputs?
One more note about validation. We validate for many reasons, but one specific one is to ensure that an input can never be executed (or interpreted). If an input is ever passed into an executable context, it must be sanitized or defanged.
Actually, it’s best not to pass input into executable contexts in the first place, e.g., use textContent rather than innerHTML in a browser, or whitelist the heck out of inputs so that no characters with special meaning to an interpreter are even allowed. But sometimes you can’t, so you have to sanitize. After all, SQL uses apostrophes for strings and D'Andre and O'Brien are indeed person names.
But there is a huge warning:
That’s right, if you have to sanitize, get a library that’s been tested to death. Sanitization is ridiculously hard: how do you know you covered every case? How do you know you’ve called the sanitizer everywhere? How can you avoid over-sanitizing and messing up valid data? How do you know if your sanitization as changed a user’s intended meaning?
Your first thought should be how to avoid the need for sanitization. To recap:
- If user input will be controlling some part of program execution through an interpreter (e.g., JavaScript, SQL, etc.), then if at all possible, restrict the domain model of the input so that it does not contain any
- If the input domain must allow all characters, use a library to perform the sanitization and execution behind the scenes. That is not your job.
Further reading on sanitization.
Speaking of Names
All developers need to read Falsehoods Programmers Believe About Names and Why Your Form Only Needs One Name Field. Please. Be a good person. Do the right thing. Inclusion matters.
Secure Error Handling
If an operation cannot be carried out, for whatever reason, it is said to fail. What should the programmer arrange to do on failure?
- Ignore the error and keep on computing? 🙅🏽♀️
- Write the error information somewhere and hope the caller checks it? 🙅🏽♀️
- Disrupt the caller so the caller has no choice at all but to handle it? ✅
- Crash immediately? 🤔
The problem with the first two approaches is that a system is likely left in an inconsistent (corrupted) state, and something terrible is going to occur long after the initial problem occurred—by that time it’ll be hard to go back and figure out what happened. The cost at this point might be catastrophic.
Some thoughts to start your discussion: a banking system that is down cannot clear out your account, and flight control software that isn’t running cannot, um, ... (does that help?)
We must:
- Fail fast (right away!)
- Fail loudly (so everyone knows!)
- If in the middle of something, Rollback (to avoid corruption)
Other best practices:
- Handle exceptions as close to where they might happen as possible
- If applicable, top-level handling can be good (esp. in web servers)
- If your language has a
finallyclause, use it for cleaning up resources, closing connections, resetting things, etc. - If your language requires you to declare which errors can happen, be precise (e.g., in Java, don’t be overly general it in the
throwsclause.
There’s another big part of error handling we have to mention:
- When reporting on errors, don’t disclose too much information, as an attacker can use what you reported to gain insight into the system, and attack it.
Okay, now let’s look at how to manage control flow in the presence of error handling.
Error Objects
An error object represents, well, an error. You can use error objects just like any other object, you can assign them to variables and return them from functions. But in many languages, you can throw them. Throwing disrupts the caller, forcing it to abandon its normal control flow and transfer control to an error handler.
If you can’t throw (some languages *cough* C *cough* don’t allow this), you can return a structure with both an error object and the success value, or a union of the error object and success value. The language Swift allows both throwing and union-style result objects:
import Foundation
struct Song {
let songId: String
let lyrics: String
let price: Int
}
struct User {
let userId: String
var name: String
var currency: Int
}
let songs = [
"1": Song(songId: "1", lyrics: "Lalala", price: 10),
"2": Song(songId: "2", lyrics: "Dumdumdum", price: 50),
]
let validTokens = [
"ABC": User(userId: "alice", name: "Alice", currency: 30),
"XYZ": User(userId: "bob", name: "Bob", currency: 15),
]
enum SongFetchError: Error {
case illegalToken
case noSuchSong
case insufficientCurrency(shortBy: Int)
}
/*
* Example of a fetch that throws an error on failure.
*/
func retrieveSong(token: String, songId: String) throws -> Song {
guard var user = validTokens[token] else {
throw SongFetchError.illegalToken
}
guard let song = songs[songId] else {
throw SongFetchError.noSuchSong
}
guard user.currency >= song.price else {
throw SongFetchError.insufficientCurrency(shortBy: song.price - user.currency)
}
user.currency -= song.price
return song
}
/*
* Example of a fetch that returns a Result instance.
*/
func getSong(token: String, songId: String) -> Result<Song, SongFetchError> {
guard var user = validTokens[token] else {
return .failure(.illegalToken)
}
guard let song = songs[songId] else {
return .failure(.noSuchSong)
}
guard user.currency >= song.price else {
return .failure(.insufficientCurrency(shortBy: song.price - user.currency))
}
user.currency -= song.price
return .success(song)
}
// ---------------------------------------------------------------------------------------
// HANDLING ERRORS THAT ARE THROWN
// ---------------------------------------------------------------------------------------
// General way: do-catch statement with try
do {
let song = try retrieveSong(token: "ABC", songId: "2")
print("Sing along: \(song.lyrics)")
} catch SongFetchError.illegalToken {
print("Sorry, bad token")
} catch SongFetchError.noSuchSong {
print("Sorry, that's not there")
} catch SongFetchError.insufficientCurrency(let need) {
print("You need \(need) more currency units")
} catch {
print("I don't know what's going on")
}
// If you don't care about the error, you can make it an optional with "try?"
let lyrics = (try? retrieveSong(token: "ABC", songId: "2"))?.lyrics ?? "Nothing to sing"
print(lyrics)
// If you KNOW IT WILL WORK you can force it with "try!" but beware
let song = try! retrieveSong(token: "XYZ", songId: "1")
print(song.lyrics)
// ---------------------------------------------------------------------------------------
// HANDLING ERRORS IN RESULT INSTANCES
// ---------------------------------------------------------------------------------------
// General way: switch on .success and .failure
switch getSong(token: "ABC", songId: "2") {
case .success (let song):
print("Sing along: \(song.lyrics)")
case .failure(SongFetchError.illegalToken):
print("Sorry, bad token")
case .failure(SongFetchError.noSuchSong):
print("Sorry, that's not there")
case .failure(SongFetchError.insufficientCurrency(let need)):
print("You need \(need) more currency units")
}
// You can ignore failure by just binding to .success
if case .success = getSong(token: "XYZ", songId: "1") {
print("Sing along: \(song.lyrics)")
}
// Invoking .get() on a result makes it throw on error, so
// try result.get() can be used in a do-catch
// try? result.get() ---> makes an optional
// try! result.get() ---> will force
When might you prefer errors to throwing? One case is async code, where throwing an exception would go...where?
The Let-It-Crash Philosophy
The programming language Erlang has been used to build systems with seven-nines availability: down only three seconds per year, or two minutes every forty years. How?! A big part of the reason is the Let-It-Crash philosophy. Instead of polluting the code with a lot of error checking and handling, a process just dies. This works because (1) Erlang processes are independent of each other (they share nothing and communicate only via message passing) and (2) the Erlang runtime is such that processes are extremely cheap to restart.
This whole concept is fascinating so learn more:
When are errors errors?
Consider these scenarios:
- You are looking for a possible value in an array that meets a condition, but you don’t find one. Does the find operation fail?
- You are trying get an employee’s supervisor, but the employee does not have one. Does
getEmployee()fail? - You read a value from an input form, where the user was expected to enter a quantity, but the form input was
"Screw you!". Doesstring_to_int()fail?
The first two scenarios are not errors at all, as they not unexpected. Often, things may or may not exist (not every employer has a supervisor, and sometimes you might go to store and they are out of what you are looking for). But whether the scenario is expected or not: your code must never attempt to operate on the missing value!
When something is truly “optional,” its absence is not an error, and you should take advantage of your language’s support for optionals. Most modern languages (even Java!) directly support optionals via a generic type, usually with a nice syntax. JavaScript doesn’t have a type, but it does have the common ?. and ?? operators. Python has type hints for optionals but no dynamic optional type.
We are going to explore the use of optionals in Swift, Java, and JavaScript.
Reducing Complexity
Complexity is an enemy of security. If you have many moving parts, many interacting subsystems, many computation paths through a function (too many ifs and switches and loops), really clever dense code (that you don’t understand immediately), instances of duplicate code, functions with way too many parameters, or you accept massive or intricate inputs, you have more ways for something to go wrong, not to mention a bigger attack surface. Readability and understandability and maintainability are crucial! if you can’t read, understand, or maintain your code, how can you argue it is secure? How can you even go about fixing it if something goes wrong?
There are ways to measure the complexity of code. One way is cyclomatic complexity. Give the Wikipedia article on it a read. How can we reduce this kind of complexity? The short answer appears to be “less if-statements”! How do we do that?
Answer: Think in terms of state diagrams.
Thinking in terms of state
Too many if-statements in various places throughout the code is generally not a good sign. This code is horrifying:
def add_item_to_order(item, order):
if order.get_status() == "SHIPPED": # (1) WAIT, is this the right check?
raise OrderAlreadyShippedError()
else:
order.add_item(item) # (2) Also, did we miss anything?
Ugh! First of all, this “service method” is asking about the order’s status then trying to apply business logic. Did we get all the right checks in place? What is our order rules change? Did we forget any other checks? These checks belong in the Order class, where all of the knowledge of how orders behave are kept, or, if you require a multithreaded environment with immutable order snapshots so all writes are on a single thread, you can encapsulate business logic in a special order service.
But orders can be in so many states: new, open, paid, payment_rejected, cancelled, shipping, delivered, lost, returned, credited_after_return, etc. How can we handle all these states while minimizing the risk of getting things wrong?
If you have too many checks, create a state diagram, giving a name to each state, and include outgoing transitions only for the legal operations in each state. You might end up making a state object with all the transitions. Here’s a description of the famous State Design Pattern in Java.
Subclasses
The state pattern is great when there are more than a couple states an entity can go between. But sometimes an object’s state is inherent. For example, a shape object may be a circle or a rectangle or a polygon and never change. In this case, subclasses defining their own method implementations are often much cleaner and less error-prone than if-statements using run-time type checking code.
Clean Code
There’s another angle to “simplicity.” We want our code to be easy to read, otherwise it is confusing and hence complex. If readers and coworkers don’t understand the code, or are confused by its lies, ambiguities, and sloppy structure, exploitable flaws might be introduced. Therefore, good programming practice is demanded for security reasons. Do all the good things, including:
- Avoid redundant comments
- Delete obsolete comments
- Remove commented-out code
- Use as few function parameters as possible
- Return values rather than manage mutable arguments
- Functions should do one obvious thing and do it well
- Avoid boolean paramters
- Remove dead code
- Refactor duplicate code (stay DRY)
- Keeps levels of abstraction consistent
- Where possible, keep usage of entities close to their declaration
- Don’t implement features just because you think you might need them in the future
- Names should leave no doubt as to what they mean or are supposed to do
- Replace magic numbers with named constants (except perhaps 0, 1, and 2)
- Variable name length should be proportional to their scope size, but function name length should be inversely proportional to scope size
- If a function has a side-effect, consider putting that in the function name
These items were taken from this larger list which is worth a look, even though it comes from a book that is opinionated, controversial, and not intended to be complete.
Many language-specific style guides define rules and heuristics for clean code, and many static analyzers enforce these rules.
Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- What are three ways to avoid data corruption via shared references? Immutable objects, defensive copying, or prohibiting copying
- Why is immutability a main pillar of secure software development? Immutable objects free us from worrying about data corruption via shared references, or forgetting to revalidate on update.
- How can favoring immutability allow for more efficient software? Immutable objects can be shared, so they don’t incur the overhead of being copied. They don’t have to be locked to access them, so concurrent programming is faster and safer too.
- What is a persistent data structure? A data structure that always preserves its “history”, used when we want immutability of structures that we want to give the appearance of changing.
- Validations should be done in order from cheapest to most expensive. List as many as you can 1. Origin, 2. Authentication, 3. Authorization, 4. State, 5. Size, 6. Lexical, 7. Syntactic, 8. Semantic.
- One secure coding rule is “The only good global variable is an immutable one.” Is this okay then, in Java?
public static final int[] primes = new int[]{2, 3, 5, 7, 11, 13};No, you can update the elements of the array. - How is complexity an enemy of security? The more complex the software, the more error-prone it is, and the harder it is to reason about its correctness and its security. Every bit of added complexity is a new attack vector.
- Why should validations be done in the domain model? Improved readability and understandability because behavior is localized and more cohesive.
Less prone to errors of omission.
If left outside, the same checks may be required in a number of service functions, which is not DRY. - Why should programmers not write their own sanitization code? There are often too many edge cases. Leave sanitization to well-tested libraries.
- What is the worst thing you can do with errors in software? Ignore them, as this will likely lead to a corrupted state and loss of data integrity, which can just magnify over time to the point where you cannot recreate a proper state.
- What is the meaning of “fail fast”? Reporting errors and taking action immediately (never continuing normal operation)
- What does it mean to “throw” an error? The existing control flow is disrupted; control is transferred to a designated place where the error is “caught” and handled.
- Instead of throwing an error, we can return an error object from an operation. How can this be done safely? As a typesafe discriminated union object, summing the error type with the type of the function’s successful return value.
- Why is it not a good idea to indicate errors through mutable arguments? The caller might forget to check them.
- What condition in programming is often misunderstood by programmers to be an error that actually isn’t? An optional value that isn’t present.
- What is one of the most common ways to reduce the cyclomatic complexity of software? Replacing if-statements with a more declarative dispatch architecture.
Summary
We’ve covered:
- Goals of Secure Programming
- Secure Programming Best Practices
- Immutability
- Design by Contract
- Validation
- Secure Error Handling
- Reducing Complexity