Static Analysis
Motivation
It’s really hard to write a grammar that can determine all of the legality rules for a language. So in practice, we don’t put too much effort into the grammar. We let the grammar take care only of context-free rules that can reject, for example:
clask C {int y/-&&^while var xyz += ((((((((x;}
but leave rules like identifier uniqueness, type checking, parameter matching—and anything else that requires examining context—out of the grammar. So we say something like this:
class C {int y = x;}
is correct according to the grammar—some might even say it is syntactically correct. But the program still should not be allowed to run, as there is an error that can be detected by looking at the source code. Because the error is detectable before the program is executed, this is a kind of static error, known as a static semantic error or contextual error, emphasizing the fact that the rule violation is not detected by the (almost certainly context-free) grammar.
In order to enforce the contextual constraints, the parse tree or abstract syntax tree is transformed into a graph structure known as a program representation. Although the representation is a graph, many people speak of it as a decorated abstract syntax tree, where the “decorations” are contextual information such as types, access modifiers, and other semantic details.
Contextual rules are language-dependentStatic analysis applies to some languages more than others. “Dynamic languages” do very little (perhaps no) analysis at compile time. Some languages are super static, permitting almost every check to be done before execution. These notes try to consider tons of possible semantic checks, whether or not most languages implement them.
Examples of Contextual Constraints
The set of static constraints varies so much from language to language, so rather than focusing on a particular language, we’ll just lay out a few that you might see from time to time. This set of constraints is certainly incomplete, but it is a start.
- Identifiers have to be declared before they are used.
- Identifiers may not be used in a place where they may have not yet been initialized.
- Identifier declarations must be unique within a scope, unless a language (1) provides multiple namespace buckets (e.g., functions vs non-functions), or (2) permits overloading.
- If a local variable is declared, it must be subsequently read.
- If a private function is declared, it must be subsequently called.
- Identifiers must be used according to (1) their scope, (2) their access modifiers (private, protected, package, public, whitelist, blacklist, etc.), and (3) any other meta-level attributes (enumerable, configurable, writable, deletable, callable, etc.). Sometimes scope rules are obvious. Sometimes both explicit import and explicit export is required.
breakandcontinuestatements may only appear in a loop.returnstatements may only appear in a function. (It’s possible to encode these restrictions in the grammar, but it would be ugly).- All paths through a function must have a return (unless explicitly marked to allow infinite loops).
- All possible matches in a pattern match expression, or a switch statement, must be covered.
- When inheriting from a base class with abstract methods, or implementing an interface, all abstract methods must be implemented or the derived class must be declared abstract.
- When assigning expression $e$ to variable declared with type $t$ (or passing argument $e$ to a parameter $v$ of type $t$, or returning $e$ from a function with return type $t$), the type of $e$ must be compatible with type $t$. This may mean many things, with rules varying substantially from language to language.
- Arguments must match up with parameters in terms of number, order, name, mode, etc. Languages offer enormous flexibility here. Sometimes the number of arguments can be less or more than the number of parameters. Sometimes names are required for arguments and sometimes not.
- In an expression like
p.x, $p$ must have a dictionary type and the field $x$ must be a field of the type of $p$. Or $p$ is a module, package, or namespace, and $x$ is an identifier marked as exportable from it. - In an expression like
p[x], $p$ must have an array type and $x$ must have a type compatible with the index type of $p$’s type.
Formal Specification of Context Rules
We saw earlier that most languages define their contextual constraints, informally, in prose.
However, contextual constraints can be specified formally, just not in a context free grammar nor even in most analytic grammar formalisms. Many techniques exist. Let’s look at two: attribute grammars and static semantic inference rules.
Attribute Grammars
In an attribute grammar, we embed either action routines or semantic functions into a traditional (context-free) grammar. The idea is that each grammar variable can have attached to it any number of attributes (which can be whatever you like). When the grammar rules are being matched during a parse, the rules or actions fire, updating the attributes. Let’s learn via example.
S ⟶ skip | id "=" E | "while" E "do" S | S ";" S
E ⟶ E logop C | C
C ⟶ R relop R | R
R ⟶ R addop T | T
T ⟶ T mulop F | F
F ⟶ "-" P | P "**" F | P
P ⟶ "(" E ")" | numlit | true | false | id
addop ⟶ "+" | "-"
mulop ⟶ "*" | "/" | "%"
relop ⟶ "==" | "!=" | "<" | ">" | "<=" | ">="
logop ⟶ "&&" | "||"
When a rule fires, the preconditions are checked, and if they are not met, an error is generated. If met, the function associated with the rule is executed and the analysis continues.
| Grammar Rules | Preconditions | Semantic Rules |
|---|---|---|
S ⟶ skip |
None | None |
S ⟶ id "=" E |
id.type = E.type |
None |
S ⟶ "while" E "do" S |
E.type = "bool" |
None |
S ⟶ S1 ";" S2 |
None | None |
E ⟶ E1 logop C |
E_1.type = "bool" ∧ C.type = "bool" |
E.type := "bool"
|
E ⟶ C |
None | E.type := C.type
|
C ⟶ R relop R |
R.type = "int" ∧ R.type = "int" |
C.type := "bool"
|
C ⟶ R |
None | C.type := R.type
|
R ⟶ R1 addop T |
R_1.type = "int" ∧ T.type = "int" |
R.type := "int"
|
R ⟶ T |
None | R.type := T.type
|
T ⟶ T1 mulop F |
T_1.type = "int" ∧ F.type = "int" |
T.type := "int"
|
T ⟶ F |
None | T.type := F.type
|
F ⟶ "-" P |
P.type = "int" |
F.type := "int"
|
F ⟶ P "**" F1 |
P.type = "int" ∧ F_1.type = "int" |
F.type := "int"
|
F ⟶ P |
None | F.type := P.type
|
P ⟶ "(" E ")" |
None | P.type := E.type
|
P ⟶ numlit |
None | P.type := "int"
|
P ⟶ true |
None | P.type := "bool"
|
P ⟶ false |
None | P.type := "bool"
|
P ⟶ id |
None | P.type := id.type
|
See how it works? Each symbol gets some properties (called attributes) as necessary, and we make rules that show how to assign attribute values. In this example our attributes were sourceString (for the source code text of the construct) and post (for the postfix representation of the construct). There’s a lot of theory here that we won’t cover, like whether attributes are synthesized or inherited, but this example should work for introducing what attribute grammars look like.
Let’s apply the rules to an example we’ll come up with in class.
Now here is the specification using action routines. We don’t have to put the grammar into a simplified, standard form for these, but we should get rid of the left recursion. Let’s use the following grammar:
S ⟶ skip | id "=" E | "while" E "do" S | S ";" S
E ⟶ C (logop C)*
C ⟶ R (relop R)?
R ⟶ T (addop T)*
T ⟶ F (mulop F)*
F ⟶ "-" P | P ("**" P)*
P ⟶ "(" E ")" | numlit | true | false | id
addop ⟶ "+" | "-"
mulop ⟶ "*" | "/" | "%"
relop ⟶ "==" | "!=" | "<" | ">" | "<=" | ">="
logop ⟶ "&&" | "||"
Now our attribute grammar looks like this:
S ⟶ skip
| id "=" E {id.type := E.type}
| "while" E {if E.type != "bool" then error} "do" S
| S ";" S
E ⟶ C {if C.type != "bool" then error}
(logop C {if C.type != "bool" then error})*
{E.type := "bool"}
C ⟶ R {if R.type != "int" then error}
(relop R {if R.type != "int" then error})?
{C.type := "bool"}
R ⟶ T {if T.type != "int" then error}
(addop T {if T.type != "int" then error})*
{R.type := "int"}
T ⟶ F {if F.type != "int" then error}
(mulop F {if F.type != "int" then error})*
{T.type := "int"}
F ⟶ "-" P {if P.type != "int" then error else F.type := "int"}
| P {if P.type != "int" then error}
("**" P {if P.type != "int" then error})* {F.type := "int"}
P ⟶ "(" E ")" {P.type := E.type}
| numlit {P.type := "int"}
| true {P.type := "bool"}
| false {P.type := "bool"}
| id {P.type := id.type}
Let’s do some attribute computations.
Note how semantic functions are written separately from the grammar rules, while action routines are embedded directly within the grammar rules.
Note that Ohm feels a lot like writing attribute grammars with semantic functions (with the semantic operations completely outside of the grammar, which is amazing!) However Ohm allows arbitrary JavaScript code in its semantic functions, which is more flexible than just slapping attributes on to parse tree nodes.
The theory behind attribute grammars is pretty rich. In the compiler literature, much has been written about the order of attribute evaluation, and whether attributes bubble up the parse tree or can be passed down or sideways through the three. It’s all fascinating stuff, and worthwhile when using certain compiler generator tools. But you can always just use Ohm and enforce contextual rules with code.
Static Semantic Definitions
Another approach is to just treat contextual rules as part of the semantics of a language, albeit not the same semantics that defines the runtime effects of a program. It’s static semantics, and you can use the techniques of denotational or operational semantics to enforce the contextual rules, too.
For example, here’s a way to define the contextual constraints of the simple language Astro. Here $\vdash p$ means program $p$ is statically correct; $c \vdash e$ means expression $e$ is correct in context $c$, and $c \vdash s \Longrightarrow c'$ means that statement $s$ is correct in context $c$ and subsequent statements must be checked in context $c'$. Thinking imperatively, statically analyzing a statement “updates” the context.
The context used above was a function mapping identifiers to either (1) $\mathsf{undef}$, (2) a pair consisting of $\mathsf{num}$ and either $\mathsf{RO}$ or $\mathsf{RW}$, or (3) a pair consisting of $\mathsf{fun}$ and an arity.
Previously, we gave formal definitions of Astro and Bella in which static and dynamic semantics were defined together. If we do decide to make a static semantics on its own, then the dynamic semantics can become simpler, since we can assume all the static checks have already been done. This is, in fact, how real compilers and interpreters work.
Astro and Bella are fairly simple languages. Specifically, every legal expression has the type number, so we required only the simple notation $c \vdash e$ (meaning $e$ is legal in context $c$). In languages in which expressions may have multiple types, we often use the notation $c \vdash e : \tau$ (meaning $e$ has type $\tau$ in context $c$). There exist languages in which expressions “update” the context, so we require notations such as $c \vdash e : \tau \Longrightarrow c'$.
Implementing a Static Analyzer
Logically speaking we do static analysis by traversing the CST or AST, decorating it, and checking things. We do quite a few tasks here, such as name analysis, type analysis, control flow analysis, and data flow analysis. These tasks are often interleaved.
What do we mean by decorating? Suppose we had this source code:
function gcd(x: int, y: int) {
return y == 0 ? x : gcd(y, x % y);
}
print(gcd(5023427, 920311));
At syntax time, you only know that identifiers (of types, of variables, of functions, of whatever) are strings! You don't know what entities they refer to. You don’t really know the types of anything: you just have strings that identify the types for some parameters, but the types of expressions have to be inferred by the analyzer. All you get from the grammar is this:
Program
statements: [
FunDecl (name: "gcd", returnType: null)
params: [
Param (name: "x", type: "int")
Param (name: "y", type: "int")]
statements: [
ReturnStmt
expression: Conditional
test: Binary (op: "==", left: "y", right: 0),
consequent: "x",
alternate: FunCall
callee: "gcd",
args: [
"y",
Binary (op: "%", left: "x", right: "y")]]]
Print
args: [Call (callee: "gcd", args: [5023427, 920311])]]
Again, make sure you understand: There are no connections between the use of any identifier and the entity to which it should resolve. There are no types on any of the expressions, so they all have to be inferred. We do have type annotations on the parameters, though in some languages these are optional. There was no explicit type annotation for the return type of the function, so this would have to be inferred.
Static analysis is the process of transforming the syntax tree above into a program representation. For this example, the representation might look like this:
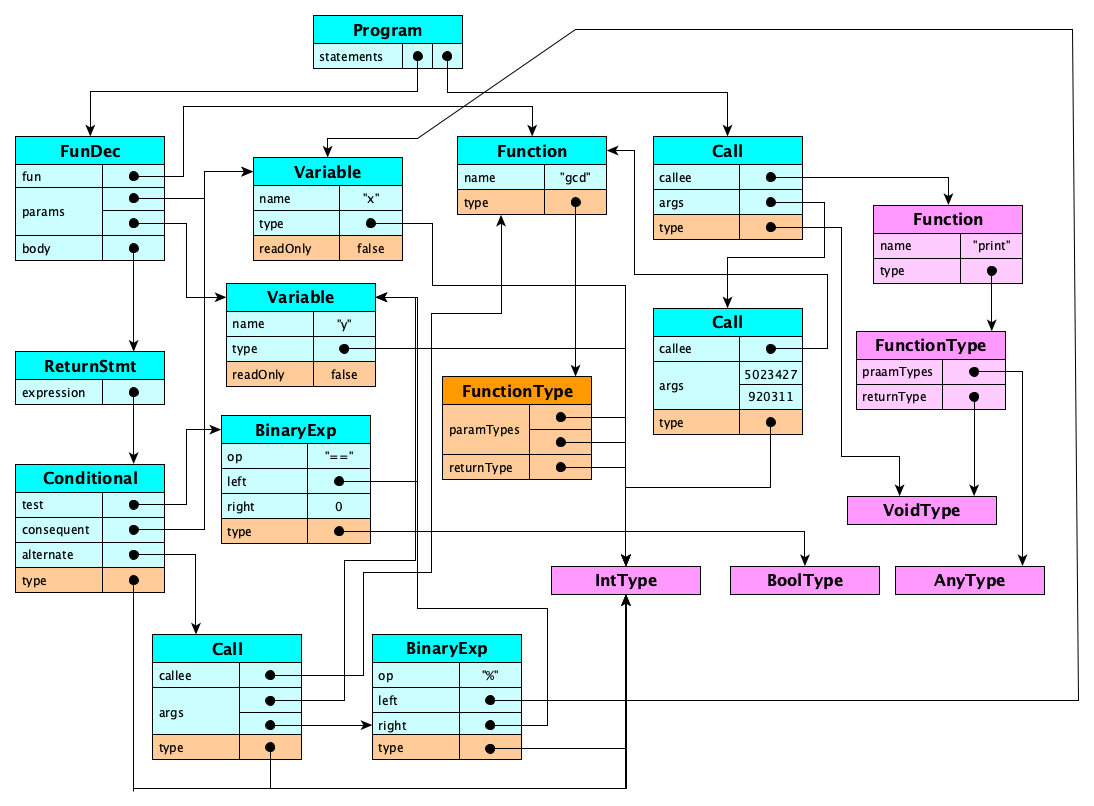
Let’s look at a high-level how-to.
Name Analysis
We have to figure out which names refer to which (declared) entities. The idea is somewhat simple: when an identifier is declared (or defined), you record it somewhere. The conventional term for the place you store the identifiers, and the entities they refer to, is symbol table.
A symbol table is a collection of mappings from names (identifiers) to entities. That is all.
How can we employ symbol tables? Should you (1) create a new symbol table for every scope, or (2) manage just one symbol table? What are the tradeoffs?
| Table per Scope | Single Table | |
|---|---|---|
| Basic Idea | There is a symbol table for every scope. Each identifier is mapped to single entity (unless overloading is permitted). | There is only one table. Each identifier is mapped to a list of entities, with each entity tagged with its scope. |
| On scope entry | Create a new, empty symbol table. Set this table’s parent to the current table. | Nothing really. Or you could increment a counter so you always have a nesting level associated with each entity. |
| On a declaration | Add identifier/entity pair to table. | Push entity onto list for the identifier. |
| On a use | Search current table; if not found, recursively search the parent table (and so on). | Search the list. |
| On scope exit | Nothing, really. | Pop all entities added in this scope. |
| Advantages | Easy to implement. Tables can be immutable. | Lookup is efficient. |
| Disadvantages | Search can be slow, especially for globals! | Mutable. Scope exit expensive. |
Every time an identifier is encountered, the symbol table(s) are consulted to determine (1) whether the entity was declared in scope, and if so, (2) what entity the identifier refers to.
Type Analysis
We also need to determine the type of every expression.
Type checking is a major component of static analysis! There are two major parts:
- Type inference: determining the type of every expression in the program.
- Type compatibility checking: checking that types are compatible where necessary (assignments, parameter passing, returns, etc.).
The rules vary widely from language to language. Some languages have a massively rich system of static types (e.g., 10 or more different distinct types for numbers alone). Some languages have incredibly intricate and detailed rules for which types are compatible with others.
Type Inference
Type inference is usually not so bad for literals.
Usually? Heh, let’s come up with examples in class where it isn’t always so easy.
For identifiers, many languages attach type constraints in different ways, including not at all. Sometimes the type constraint on the variable has to be inferred from context. You can imagine different degrees of type inference requirements on identifiers:
| How much? | Characteristics | Exemplars |
|---|---|---|
| Low | Very verbose. Pretty much every declaration (of every variable, every field, every parameter, every function) mentions its type. | Java, prior to version 10 |
| Medium | Generally variable declarations don’t need types (you can say var x = 100 or var message = "Hello"), but parameter types and function return types must be explicit.
| Go, Swift, Rust, C# |
| High | Virtually every identifier declaration can be given without a type. The inference engine has to do a ton of work. But the code looks so pretty and light, and we still get type safety guarantees before execution! Often uses a Hindley-Milner type system (with type variables) and perhaps, type classes. | Standard ML, OCaml, F#, Haskell, Elm |
Type Compatibility Checking
The rules for type compatibility vary widely from language to language. Some common considerations include:
- $e$.type is the exact same type as $t$, or
- $e$.type and $t$ have the same name, or perhaps the same structure, or
- $e$.type is a subtype of $t$, or
- The programmer has set up an implicit conversion, or coercion, from $e$.type to $t$, or
- $e$.type can be widened to $t$, e.g., byte→short→int→long→float→double... (though some languages notably disallow this!), or
- $e$.type is a bottom type, or
- $t$ is a top type.
Type checking also involves understanding overloading rules, the polymorphism mechanisms for the language, type inference rules, and how and when the language uses covariance, contravariance, invariance, and bivariance. What do those latter terms mean? Suppose Dog is a subclass of Animal:
Dog <: Animal
Now what is the relationship between List<Dog> and List<Animal>? There are four cases:
List<Dog> <: List<Animal>— covarianceList<Animal> <: List<Dog>— contravariance- Both are subclasses of the other — bivariance
- Neither are subclasses of the other — invariance
Then it gets more complicated. Do you remember, offhand, the relationships between List<Dog>, List<Animal>, and:
List<? extends Dog> List<? extends Animal> List<? super Dog> List<? super Animal> List<?> List<Object>
Control Flow Analysis
Contextual checks such as:
- Finding functions that are never called
- Detecting unreachable code
- Identifying (some) infinite loops
- Checking paths without return statements
can be systematically analyzed using the techniques of control flow analysis.
Read about CFA and CFGs at Wikipedia.
Control flow analysis generally requires a transformationTo do CFA, we will often want to first get all of the executable statements of the program into a control flow graph (CFG). You can find the details of how this is done in the Wikipedia article.
We’ll also have more to say about this when we look at Intermediate Representations later in the course.
Data Flow Analysis
Contextual checks such as:
- Finding variables that are used but not declared
- Finding variables that are used but not initialized
- Finding variables that are declared but never used
- Finding variables that are updated but never read
can be systematically analyzed using the techniques of data flow analysis.
Read about DFA at Wikipedia.
Languages like Rust also do ownership and borrowing computations as part of data flow analysis. We might cover this in class. If we don’t, read these three sections from The Rust Programming Language Book: Ownership, References and Borrowing, and Lifetimes.
Data flow analysis also requires a transformationDFA, like CFA, generally requires a control flow graph.
Security Analysis
A compiler’s static analyzer only needs to check whether programs violate language rules. But there are also many such statically ”correct” programs that are written weirdly, extremely error prone, under-performant, resource-leaking, subject to race conditions, vulnerable to attacks, or produce completely unexpected (in other words, wrong) results when run. These problems can be captured by a linter.
Look at these cool lists:
- List of (potential) Java bugs detectable by FindBugs™.
- List of (potential) Java bugs detectable by PMD.
- List of (potential) JavaScript bugs detectable by PMD.
- The rules of ESLint.
You should integrate a linter into your text editor or IDE. Seeing both language errors (from the compiler) and linter errors while you write your program is a Good Thing.
Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- What kinds of grammar rules do most programming languages stick to in their syntax definitions? Context-free rules.
- Why do most programming language syntax definitions separate their context-free rules from context-sensitive rules? Because context-free rules are massively easier to specify and parse, both in terms of human comprehension and efficiency. Context-sensitive rules are often ridiculously more complex and require more sophisticated analysis.
- What is a static semantic error? A violation of a language rule that can be detected before execution of the program, but not detected as an error by the language’s grammar.
- What is another name for a static semantic error? Contextual error.
- What is the process of looking for static semantic errors called? Static analysis.
- To perform static analysis, what must the output of the parser be transformed into? A program representation, more complex than an abstract syntax tree.
- Distinguish “static languages” and “dynamic languages”. Static languages are those with tons of legality rules (type checking, matching, counting, exhaustiveness, etc.) that have to be checked at compile time, so the compiler writer has to do a ton of work. Dynamic languages leave little for the compiler to do, as all those checks are pushed to run time.
- What kinds of rules about program legality cannot be captured in a context-free grammar (or even in Ohm)? Give as many as you can.
Here is an incomplete list:
- Type checking
- Redeclaration of identifiers within a scope
- Use of an undeclared identifier
- Matching arguments to parameters in a call
- Access checks (public, private, etc.)
- Identifiers must be used in all paths through their scope
- A return must appear in all paths through a function
- Pattern match exhaustiveness
- In a subclass, abstract methods must be implemented or declared abstract
- All private functions must be called within a module
- What are two different formalisms for defining static semantic constraints? Attribute grammars and static semantic inference rules.
- What are two approaches to structuring attribute grammars? Semantic functions and action routines.
- What are the structural differences between semantic functions and action routines? Semantic functions are specified separately from the grammar rules, while action routines are embedded directly within the grammar rules.
- What is the basic idea behind using semantic rules for defining contextual constraints? They allow us to infer properties about program constructs based on their context, enabling the detection of static semantic errors.
- What are four types of static analyses? Name analysis, type analysis, control flow analysis, and data flow analysis.
- What happens in name analysis? We determine the actual entities that each identifier refers to (and generate errors if a name does not refer to any entity).
- Type analysis is usually thought of as having two major, but intertwined, components. What are they called? Type inference and type (compatibility) checking.
- What is the purpose of type inference? To determine the type of every expression in the program.
- What kinds of constructs are often type-checked? Function calls, assignments, and return statements.
- What kinds of errors are detected in control flow analysis? Functions that are never called, unreachable code, infinite loops, paths without return statements, and more.
- What kinds of information are determined in data flow analysis? Identifiers that are used but not declared, used but not initialized, declared but never used, and so on.
- How is security analysis different from the other forms of static analysis? Security analysis focuses on identifying potential vulnerabilities in code that is legal according to the language rules.
- What is a linter? A tool that performs static analysis to identify vulnerabilities, code smells, and stylistic issues in source code.
Summary
We’ve covered:
- Examples of Contextual Constraints
- Formal Specification of Context Rules
- Attribute Grammars
- Static semantic rules
- Implementing a Static Analyzer
- Linting