Language Design

Designing a Language
Of course you want to design (and implement!) your own programming language! It’s fun. It’s creative. It’s empowering.
How do we do it? In a nutshell, the process is iterative, cycling between four phases:
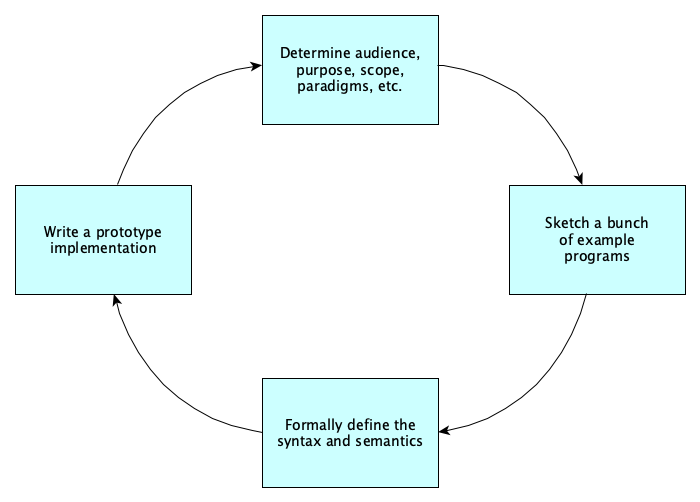
Doing the phases over and over is important; for example, while writing the compiler, you may be like “woah this is impossible” and then realize “oh shoot this part of the language wasn’t designed right!”
Prerequisites
It helps to be experienced. If you’re not, that’s okay, actually—you might get lucky!
But don’t mistake creativity for luck that shows up without pre-existing knowledge. The most creative people are those with a lot of knowledge and experience. So you should still study and practice!
Your success as a language designer will be massively aided by knowledge in three main areas:
- Programming Paradigms. You should know a number of different ways that computations can be structured. These include: imperative declarative structured object-oriented functional applicative concatenative logic protocol-oriented aspect-oriented array event-driven dataflow agent-based etc.
See Wikipedia’s list of programming paradigms.
- Programming Language Concepts. You should have a good sense of most, if not all, of the following things: Sequencing, conditional execution, iteration, recursion, functional decomposition, modularity, synchronization, metaprogramming, binding, scope, extent, volatility, subtyping, pattern matching, type inference, closures, prototypes, introspection, instrumentation, annotations, decorators, memoization, traits, streams, monads, actors, mailboxes, comprehensions, continuations, wildcards, promises, regular expressions, proxies, transactional memory, inheritance, polymorphism, parameter modes, type classes, generics, reflection, concurrency, parallelism, distribution, persistence, transactions, garbage collection, and many more terms.
I’m working on a glossary of such terms that may be helpful to review.
- Existing ProgrammingLanguages. It’s nice to have a feel for a variety of languages. Here are a few that are good to be familiar with (and the reasons why they are good to study):
- Python, for basic imperative programming and scripting
- Smalltalk, for OOP done beautifully
- JavaScript, for event-driven features, async, and promises
- Io, for ideas on building up everything from a minimal semantics
- Julia, for multiple dispatch
- Clojure, Racket, Scheme, and Common Lisp, for Lispiness (macros, etc.)
- Standard ML, OCaml, F#, and Elm, for Hindley-Milner typing and more
- Haskell, for typeclasses and functional purity
- eToys, Scratch, Snap!, and GP for the blocks approach
- Java and C#, for use in enterprise software
- Kotlin, Ceylon, and Scala, as examples of evolving Java
- Erlang, Elixir, and Gleam, for expressing concurrent processes in a distributed fashion
- Fortran, Chapel, and Parasail, for expressing multicore and parallel programming
- TypeScript, PureScript, and ClojureScript, as examples of evolving JavaScript
- C, because it is the quintessential systems language
- C++, Rust, Zig, Odin, and Mojo for making systems programming less painful and more secure
- Go and Swift, for more examples of modern, but generally mainline, ideas
- Verse, for massive concurrency in real-time multiplayer games in the metaverse
- J and K, for array programming
- Idris, for dependent typing
- Prolog and Mercury, for logic programming
- Forth and Factor, for concatenative programming
- Quipper, because it’s a language for quantum computing
- Brainfuck, Malbolge, LOLCODE, Whitespace, and other classic esoterics
- GolfScript, CJam, Pyth, Jelly, and other golfing languages, because this gives you a good sense of putting power into small syntactic constructs
- Piet and Hexagony, for, well, check them out....
Also check out this mini-encyclopedia of over 100 languages.
Here are some excellent cross-language comparisons that help you to hone your understanding of how different syntaxes can express the same ideas:
These are really good too:
Getting Ready
Remember, many people have designed languages before you. They made mistakes. They came up with brilliant ideas. Many were wildly successful. Some never made it big. Some people have brought in years of research on how people think and learn to come up with principles for language (and environment) design.
You should learn form their experiences.
Study classic papers. Read web essays. Visit online courses. Here is a small sampling of things to study and places to look for more information:
- Hints on Programming Language Design by Tony Hoare
- Learnable Programming by Bret Victor
- Five Questions about Language Design by Paul Graham
- For early classic papers, check out the massive bibliography of this paper
- Also look at the papers from Kathleen Fisher’s Programming Language Design class
Think about the future:
And understand that traditional, mainstream programming languages, are not at all the epitome of computational expression. Languages can be much more:
Getting Started
Ready to strike out on your own? Here are some things to think about, in the form of a, you guessed it, a checklist:
- Do you have a specific audience in mind? Artists? Graphic designers? AI researchers? Numeric and Scientific nerds? Natural language types? Game developers? Machine learning people? Animators? High performance folks? System programmers? Or do you want a general purpose language? Or do you just want to do what you want?
- Understand the audience that the language is designed for, and what kinds of things they want to create with it (or problems they want to solve with it).
- Determine if your language is to be (1) a reasonable, usable language or (2) an esoteric/joke/golfing language.
- Determine if it is to be pragmatic, idealistic, researchy, or evil.
- Determine whether you want your language firmly in one camp—OO, functional, logic, concatenative, plain-imperative—or be a multiparadigm symphony. Or a multiparadigm cacophony.
- Determine whether it is to be built on a single characteristic building block (a crystallization of style) or one with a huge variety of syntactic forms for multiple semantic aspects (an agglutination of features).
- Determine your concurrency model. Do you want all your programs to be single-threaded and sequential? Or are you looking for something event-driven and async? Or multithreaded? Or distributed?
Choosing a Starter Set of Features
Come up with a list of capabilities, or features. Make sure they enable programmers to express their creations by following the suggestions and principles in the Learnable Programming essay, including:
- Make meaning transparent
- Explain in context
- Make flow and time tangible and visible
- Show the data, and avoid hidden state
- Use metaphor
- Allow easy decomposition and recomposition
- Allow the programmer to write readable code—you do support mentioning parameter names in calls, right?
What kind of questions might you have here? Here are some totally random ideas:
- If your language supports functions:
- Must you pass the exact number of arguments the function expects?
- Can you specify parameter names in the call?
- Do you have rest parameters? optional parameters? keyword parameters? default parameters?
- Are the parameters typed?
- Can parameters be modified? Are they passed by value, value-result, reference, name, etc?
- Are arguments evaluated L-R, R-L, in parallel, or in arbitrary order?
- How does a function return a value? Can it return zero or more values or just one?
- Are functions first-class? If so, do you use deep binding or shallow binding?
- Is recursion allowed?
- Can you test functions for equality?
- Can functions be anonymous?
- What is your type system like?
- Static vs. dynamic, strong vs. weak, manifest vs. implicit?
- Do you distinguish primitive types from reference types?
- Do you have all those different numeric types based on bit size? What about decimals and ratios?
- Do you have a separate character type? A separate boolean type?
- Can you get the type of an expression at runtime?
- Are types objects?
- Do you have supertypes and subtypes? Multiple-inheritance? If so, how do you handle name collisions?
- Are types the same as classes? Can you add new types?
- Do you have both sum and product types?
- Do functions have a type?
- Are there pointer types?
- Are there parameterized types? If so, are they (mostly) covariant, contravariant, or invariant?
- Any dependent types?
- What do your expressions look like?
- And does your runtime follow eager or lazy evaluation? Or both?
- Do you have only prefix, only postfix, only infix, or a wild mix of operators?
- Can you overload operators? If so, how?
- Can you change the precedence of operators? Even the built-in ones? At runtime?
- How much type inference do you have?
- Can you mark variables as mutable or immutable?
- Are your variables bound or assigned? Can they be assigned more than once?
- Do you have destructuring and/or pattern matching?
- How do you determine scope? Do you implicitly or explicitly import into inner scopes?
- Are there keywords that define access like
public,private, andprotected, or are there conventions, like in Go, where capitalized entities are implicitly exportable and lower-cased entities are private? - Is there a
let-expression for super-local scopes? - Is shadowing allowed?
- Do you have anything like JavaScript’s
thisexpression?
- How do you express control flow?
- Do you like expression-orientation or do you have real statements?
- How do you express sequential flow vs. nondeterministic flow vs. parallel flow?
- If you have nondeterminism, how do you ensure fairness?
- Must guards in a multiway selection be executed in any particular order?
- Do you have short-circuit operators? Iterator objects? Generators?
- Do you have all the loops: (1) forever, (2) n times, (3) while/until a condition, (4) through a numeric range (with an optional step size), or (5) through a collection?
- Do you have
breakandcontinue? Anything like Ruby’sretryandredo? - Do you have exceptions? Or do you need Go-style constructs? Or do you have nullables everywhere?
- Do you have a timer for sleeping, delaying execution, or running on intervals?
- Can I haz
goto?
- How do you support concurrency?
- Threads, or events?
- Shared memory only? Message passing only? Or both? If shared memory, is it mutable? If so, do you have locks, higher-level synchronization devices, or some kind of transactional memory?
- Do you support different levels of granularity of concurrency?
- Are tasks spawned implicitly when their enclosing block begins, or do they require explicit invocation?
- Do tasks die when the enclosing block or spawning task terminates? Or does the spawner wait for all internal tasks to terminate?
- Do taks know who started them?
- If an asynchronous task is launched, how is a result obtained? Callback, promise, or some other mechanism?
- Is message passing done via named channels, named processes, or bulletin board?
- Is message passing always synchronous, asynchronous, or both?
- Is there timed or conditional synchronization mechanisms?
- Can tasks detect their own state?
- How meta are you?
- Can a program get a list of its global variables, loaded classes, top-level functions, etc.? Can a class get a list of its fields, methods, constructors, superclass(es), subclasses, etc.? Can a function get its parameters, locals, return types, etc.?
- Can a function find out who called it?
- Can a variable be read or set via its name (a string) only? Can a function or method be invoked by its name (a string) only? Can new variables or types or functions be created at run time, given only their name and some indication of how they should look?
- Does the language have a macro system? If so, is it string-based or AST-based?
- Is it possible to unquote within a macro?
- Are macros hygienic? What syntactic devices are provided to explicitly capture in- scope variables, if any?
What did I just read?Feeling like only about 20% of the questions above made any sense? Feeling like that vocabulary came out of nowhere? That’s fine for now. Learning about programming languages can be a never-ending lifelong journey, but you can use the questions you don’t quite understand now as a place to start some research.
Oh, I have a glossary you might find helpful.
From Features To Abstract Syntax
When you have a good idea of your language features, you’ll want to figure out a good way to organize them, structurally. This is known as your language’s abstract syntax. In an abstract syntax we don’t worry much about punctuation and parentheses and such microscopic details. We are interested in the overall structure. Here’s a look at abstract syntax trees in JavaScript:
When defining your language, you will want to specify exactly what the AST Nodes are, how they are related to each other, and what their properties are. For JavaScript, the AST Node types come from a specification called EsTree. I've summarized the main interfaces here:
Program sourceType:["script"|"module"] body:[Statement|ModuleDeclaration]
Statement
Declaration
FunctionDeclaration(Function) id:Identifier
VariableDeclaration declarations:[VariableDeclarator] kind:("var"|"let"|"const")
ClassDeclaration(Class) id:Identifier
EmptyStatement
DebuggerStatement
ExpressionStatement expression:Expression
BlockStatement body:[Statement]
ReturnStatement argument:Expression?
LabeledStatement label:Identifier body:Statement
BreakStatement label:Identifier?
ContinueStatement label:Identifier?
IfStatement test:Expression consequent:Statement alternate:Statement?
SwitchStatement discriminant:Expression cases:[SwitchCase]
WhileStatement test:Expression body:Statement
DoWhileStatement body:Statement test:Expression
ForStatement init:(VariableDeclaration|Expression)? test:Expression? update:Expression? body:Statement
ForInStatement left:(VariableDeclaration|Pattern) right:Expression body:Statement
ForOfStatement await:boolean
ThrowStatement argument:Expression
TryStatement block:BlockStatement handler:CatchClause? finalizer:BlockStatement?
WithStatement object:Expression body:Statement
Function id:Identifier? params:[Pattern] body:BlockStatement generator:bool async:bool
VariableDeclarator id:Pattern init:Expression?
SwitchCase test:Expression? consequent:[Statement]
CatchClause param:(Pattern?) body:BlockStatement
Expression
ThisExpression
Identifier(Pattern) name:string
Literal value:(string|bool|number|Regexp|bigint)?
RegExpLiteral regex:{pattern:string flags:string}
BigIntLiteral bigint:string
ArrayExpression elements:[(Expression|SpreadElement)?]
ObjectExpression properties:[Property|SpreadElement]
FunctionExpression(Function)
ArrowFunctionExpression(Function) body:(BlockStatement|Expression) expression:bool
UnaryExpression operator:UnaryOperator prefix:bool argument:Expression
UpdateExpression operator:UpdateOperator argument:expression prefix:bool
BinaryExpression operator:BinaryOperator left:Expression right:Expression
AssignmentExpression operator:AssignmentOperator left:Pattern right:Expression
LogicalExpression operator:LogicalOperator left:Expression right:Expression
MemberExpression(ChainElement) object:(Expression|Super) property:Expression computed:bool
ChainExpression expression:ChainElement
ConditionalExpression test:Expression consequent:Expression alternate:Expression
CallExpression(ChainElement) callee:(Expression|Super) arguments:[(Expression|SpreadElement)]
YieldExpression argument:Expression? delegate:bool
TemplateLiteral quasis:[TemplateElement] expressions:[Expression]
TaggedTemplateExpression tag:Expression quasi:TemplateLiteral
NewExpression
SequenceExpression expressions:[Expression]
ClassExpression(Class)
AwaitExpression argument:Expression
ImportExpression source:Expression
MetaProperty meta:Identifier property:Identifier
Class id:Identifier? superClass:Expression? body:ClassBody
ClassBody body:[MethodDefinition]
MethodDefinition key:Expression value:FunctionExpression kind:("constructor"|"method"|"get"|"set") computed:bool static:bool
SpreadElement argument:Expression
Property key:Expression value:Expression kind:("init"|"get"|"set") method:bool shorthand:bool computed:bool
AssignmentProperty value:Pattern kind:"init" method:false
Pattern
ObjectPattern properties:[AssignmentProperty|RestElement]
ArrayPattern elements:[Pattern?]
RestElement argument:Pattern
AssignmentPattern left:Pattern right:Expression
Super
TemplateElement tail:boolean value:{cooked:string? raw:string}
ChainElement optional:boolean
enum UnaryOperator {"-"|"+"|"!"|"~"|"typeof"|"void"|"delete"}
enum UpdateOperator {"++"|"--"}
enum BinaryOperator {"=="|"!="|"==="|"!=="|"<"|"<="|">"|">="|"<<"|">>"|">>>"|"+"|"-"|"*"|"/"|"%"|"**"|"|"|"^"|"&"|"in"|"instanceof"}
enum AssignmentOperator {"="|"+="|"-="|"*="|"/="|"%="|"**="|"<<="|">>="|">>>="|"|="|"^="|"&="}
enum LogicalOperator {"||"|"&&"|"??"}
ModuleDeclaration
ImportDeclaration specifiers:[ImportSpecifier|ImportDefaultSpecifier|ImportNamespaceSpecifier] source:Literal
ExportNamedDeclaration declaration:Declaration? specifiers:[ExportSpecifier] source:Literal?
ExportDefaultDeclaration declaration:(Declaration|Expression)
ExportAllDeclaration source:Literal exported:(Identifier?)
ModuleSpecifier local:Identifier
ImportSpecifier imported:Identifier
ImportDefaultSpecifier
ImportNamespaceSpecifier
ExportSpecifier exported:Identifier
I’ve built an interactive application for you to explore AST generation. Please try it out!.
Too much detail?You may notice that the EsTree specification has a lot more detail than the hand-drawn ASTs in the video above. This is okay. The specification is used to build actual compilers and interpreters, while for hand-drawn ASTs we just like to give the big picture and can take some “shortcuts.”
From Abstract Syntax to Concrete Syntax
Now it’s time to think about what your language will really look like! Remember that design is creative and iterative, so you will want to begin, like all artists do, with sketches:
- Sketch programs or program fragments in your language.
- Sketch fragments that are not in your language.
- Come up with a nice, consistent, syntactic theme.
Do a lot of experimentation here! You will probably want to put creative effort into designing languages people like to use! What kind of syntax issues do they deal with? Dozens, actually, and we can’t cover them all. But how about a taste of just a few. We’ll peek at just a few issues that sometimes generate strong opinions.
Overall Phrase Structure
You will need to adopt a scheme for showing structure. The popular approaches are: Curly-brace (JavaScript, Java, C++, C#), Terminal-end (Ruby, Ada), Nested parentheses (Lisp, Clojure, Racket), Indentation (Python), Blocks (EToys, Scratch, Snap!), Pictures (Piet), Other (Haskell, Erlang, Prolog).
The important idea here is that a single abstract syntax can be realized with many different concrete syntaxes. A concrete syntax specifies exactly which strings of characters make up structurally valid programs. For example, the AST:
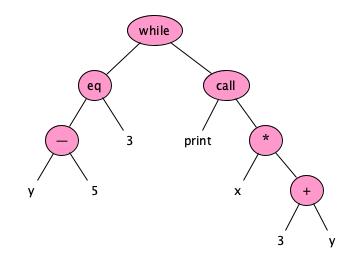
represents each of the following (and more!):
while y - 5 == 3:
print(x * (3 + y))
while y - 5 == 3 {
print(x * (3 + y))
}
while y - 5 == 3 loop
print(x * (3 + y))
end
(while (= (- y 5) 3)
(print (* x (+ 3 y))))
y 5 - 3 == [x 3 y + * print] while. Do you know of, or can you find, any languages which have that kind of syntax?
In addition to structure, your choice of keywords, operators, punctuation (or lack thereof) are part of your design. Here’s an abstract syntax:
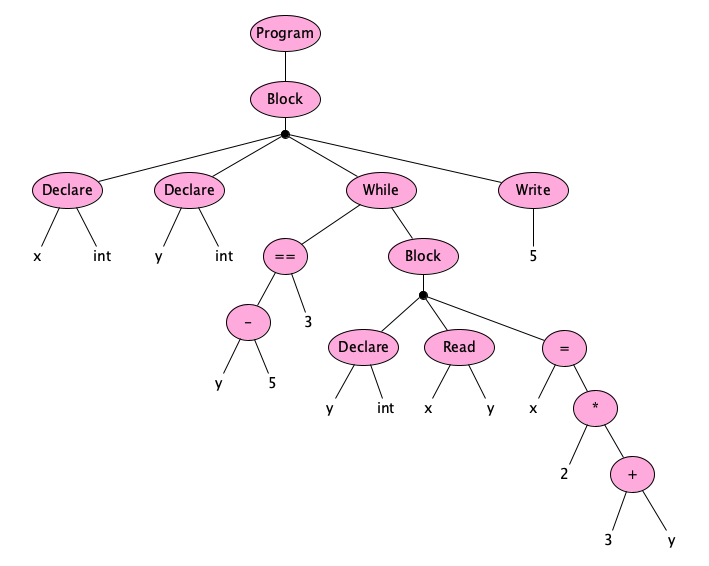
Let’s try out a few things:
program:
var x, y: integer
while y - 5 == 3:
var y: integer
get(x)
get(y)
x = 2 * (3 + y)
put(5)
int x, y;
while y - 5 = 3 {
int y;
STDIN -> x;
STDIN -> y;
x <- 2 * (3 + y);
}
STDOUT <- 5;
COMMENT THIS LOOKS LIKE OLD CODE
DECLARE INT X.
DECLARE INT Y.
WHILE DIFFERENCE OF Y AND 5 IS 3 LOOP:
DECLARE INT Y.
READ FROM STDIN INTO X.
READ FROM STDIN INTO Y.
MOVE PRODUCT OF 2 AND (SUM OF 3 AND Y) INTO X.
END LOOP.
WRITE 5 TO STDOUT.
(program
(declare x int)
(declare y int)
(while (= (- y 5) 3)
(define (y int))
(read x y)
(assign x (* 2 (+ 3 y)))
)
(write 5)
)
Delimiters
How to separate one construct from another is a really big issue in syntax design, believe it or not. We can identify two main classes of languages: those in which newlines are significant and those in which they are not.
“Insignificant” Newlines
In many languages, newlines are just like any other whitespace character (except for minor exceptions such as single-line comments and single-line string literals. Then, unless you have an S-Expression-based syntax as in LISP, Scheme, and Clojure, you’ll need semicolons to terminate (or separate) statements. This means you can (but shouldn’t) write code like:
#define ZERO 0 unsigned gcd( unsigned int // Euclid's algorithm x,unsigned y) { while ( /* hello */ x> ZERO ){unsigned temp=x;x=y %x;y = temp ;}return y ;}
“Significant” Newlines
Where you place your newlines matters greatly in, let’s see, Assembly languages, Python, Ruby, JavaScript, Elm, Haskell, Go, Swift, and yes, many others. The rules can get pretty technical.
Python scripts are defined as sequences of logical lines, delimited by the token NEWLINE. A statement may not cross logical lines, except in the case of compound statements in which each constituent simple statement ends with a NEWLINE. Logical lines are made up of one or more physical lines according to line joining rules. Lines are implicitly jointed within parentheses, brackets, or braces; lines can be explicitly joined by ending with a backslash. These rules are somewhat exclusive of comments and string literals.
Ruby looks at the end of each line and says “well, if up to here it looks like we’ve completed a statement, then we have completed a statement.” This means you have to be careful where you break lines:
puts 5 + 3 puts 5 + 3
prints 5 then 8.
“Possibly Significant” Newlines
JavaScript requires most statements to be terminated by semicolons, but the compiler will put one in for you if it looks like you might have missed one. The rules by which this automatic semicolon insertion (ASI) is done have to be learned and they might be hard to remember.

If you are going to be a serious JavaScript programmer, you need to learning the rules of ASI whether you choose to use semicolons or not.
Some people feel very strongly whether to use or not to use semicolons:
Function Calls
Most programming languages have functions. Seriously. But there are a lot of ways to work them into your design. Basic questions include: Must functions have exactly one argument, or zero or more arguments? Parens or no parens? Positional or keyword arguments? Argument labels? If no arguments, can we omit parentheses?
You can play around and see what you can come up with:
push(myStack, 55)push myStack 55[push myStack 55](push myStack 55)push(on: myStack, theValue: 55)push(theValue: 55, on: myStack)push on:myStack theValue:55push({ on: myStack, theValue: 55 })push { on: myStack, theValue: 55 }push({ theValue: 55, on: myStack })
You might want to consider an ultra-low precedence function application, like they have in Haskell and F#:
sum (filter even (map square a))sum $ filter even $ map square $ asum <| filter even <| map square <| aa |> filter even |> map square |> sum
The flip side of function calls is function definitions. You’re likely familiar with default parameters, and rest parameters. Python has cool mechanisms for requiring arguments to be positional or keyword, based on the definition. Examples:
def sqrt(x, /)def line(*, x1, x2, y1, y2, width, style, color)def f(a, b, /, c, d, *, e, f)
Syntactic Sugar
Syntactic sugar refers to forms in a language that make certain things easier to express, but can be considered surface translations of more basic forms.
This is best understood by example. There are zillions of examples out there. Here are a few. (Disclaimer: Some of these are just examples I made up and are not part of any real language.)
| Construct | Desugared Form | Description |
|---|---|---|
x += n | x = x + n | Compound assignment |
a + b | operator+(a, b) or"+"(a, b) or__add__(a, b) | Common in languages that allow overloading |
a[i] | *(a + i) | (C, C++ pointer arithmetic) And i[a] works too!
|
p -> x | (*p).x | (C, C++) Field of struct being pointed to |
f | f() | Some languages let you leave off parentheses in calls with no arguments |
f x | f(x) orx.f() | Some languages let you leave off parentheses in calls with one argument |
x op y | op(x, y) orx.op(y) | Some languages let you leave off parentheses in calls with two arguments |
let x=E1 in E2 | (x => E2)(E1) | Let-expression (in functional languages) |
(E1 ; E2) | (() => E2)(E1) | Expression sequencing (in eager functional languages) |
r = [s | r = [] | List comprehension |
x orelse y | if x then x else y | (Standard ML) short-circuit disjunction |
x andalso y | if x then y else x | (Standard ML) short-circuit conjunction |
[x, y, z] | x :: y :: z :: nil | Lists in Standard ML |
"a${x}b" | "a" + x + "b" | String interpolation |
When the sugared form is completely gratuitous or actually makes the code less readable, you sometimes hear the term syntactic syrup or syntactic saccharin.
Syntactic Salt
Here’s the definition from The New Hacker’s Dictionary:
The opposite of syntactic sugar, a feature designed to make it harder to write bad code. Specifically, syntactic salt is a hoop the programmer must jump through just to prove that he knows what’s going on, rather than to express a program action. Some programmers consider required type declarations to be syntactic salt. A requirement to write “end if”, “end while”, “end do”, etc. to terminate the last block controlled by a control construct (as opposed to just “end”) would definitely be syntactic salt. Syntactic salt is like the real thing in that it tends to raise hackers’ blood pressures in an unhealthy way.
Candygrammars
Some people love verbose code, because explicit is better than implicit. But if you are language designer, be pragmatic: there is such a thing as code that is too verbose. What about trying to make the code like human language? Here’s an example in Hypertalk (taken from Wikipedia):
on mouseDown
answer file "Please select a text file to open."
if it is empty then exit mouseDown
put it into filePath
if there is a file filePath then
open file filePath
read from file filePath until return
put it into cd fld "some field"
close file filePath
set the textStyle of character 1 to 10 of card field "some field" to bold
end if
end mouseDown
And here’s an example from a language that some students developed, and regretted:
to get the truth value prime of whole number n:
return no if n < 2
for each d in 3 to n - 1 by 2:
return no if d divides n
end
return yes
end
for each k in 1 to 100:
write k if prime(k)
end
In practice this kind of verbosity is worse than it sounds. Here’s what the New Hacker’s Dictionary has to say about this:
candygrammar /n./ A programming-language grammar that is mostly syntactic sugar; the term is also a play on “candygram.” COBOL, Apple’s Hypertalk language, and a lot of the so-called “4GL” database languages share this property. The usual intent of such designs is that they be as English-like as possible, on the theory that they will then be easier for unskilled people to program. This intention comes to grief on the reality that syntax isn’t what makes programming hard; it’s the mental effort and organization required to specify an algorithm precisely that costs. Thus the invariable result is that candygrammar languages are just as difficult to program in as terser ones, and far more painful for the experienced hacker.
[The overtones from the old Chevy Chase skit on Saturday Night Live should not be overlooked. This was a "Jaws" parody. Someone lurking outside an apartment door tries all kinds of bogus ways to get the occupant to open up, while ominous music plays in the background. The last attempt is a half-hearted "Candygram!" When the door is opened, a shark bursts in and chomps the poor occupant. There is a moral here for those attracted to candygrammars.]
Terseness
Some languages pride themselves on doing a whole lot with few characters:
An example from Ruby (do you see what this does?):
c = Hash.new 0 ARGF.each {|l| l.scan(/[A-Z']+/i).map {|w| c[w.downcase] += 1}} c.keys.sort.each {|w| puts "#{w}, #{c[w]}"}
An example from APL (The 99 bottles of beer program taken from Rosetta Code):
bob ← { (⍕⍵), ' bottle', (1=⍵)↓'s of beer'} bobw ← {(bob ⍵) , ' on the wall'} beer ← { (bobw ⍵) , ', ', (bob ⍵) , '; take one down and pass it around, ', bobw ⍵-1} ↑beer¨ ⌽(1-⎕IO)+⍳99
Here’s APL again, with an expression to find all the prime numbers up to R:
(~R∊R∘.×R)/R←1↓⍳R
Some people love terse, concise code, because it says only what it needs and reduces the cognitive load, leaving you with less useless noisy syntax to learn. But if you are language designer, be pragmatic: there is such a thing as code that is too terse. Unless...that’s your goal....
Golfing Languages
Golfing languages take terseness to the next level. A golfing language is a kind of esoteric programming language (a non-practical language created to experiment with weird ideas, be hard to program in, or be humorous) that allows programs to be written in an insanely small number of characters (or bytes).
Here are some CJam programs:
"Hello, world!"
5{"Hello, world"oNo}*
0X{_2$+}A*]N*
l~@-@@-mh
1{_B<}{_'**N+o)}w;
Here are some Pyth programs (taken from the documentation):
"Hello, world!
FNrZhTN
FNUhTN
VhTN
K1FNr1hQ=K*KN;K
.!Q
WtQ=Q?%Q2h*Q3/Q2Q
A(Z1;VhhTGA(H+GH
Defining Your Language
Traditionally, real world language definitions come in three main flavors:
- An official document, with a mix of formal notation and informal descriptions (Very common)
- An official document, with 100% of the definition specified in a formal notation (Very rare)
- A “reference implementation,” namely a compiler or interpreter, so that the language “definition” is simply “whatever this program does” (Typical for some scripting languages). An advantage if this approach is that there are never any compiler bugs!
An official definition will have three parts:
| Syntax (Structure) | Semantics (Meaning) | |
|---|---|---|
| Statics (before execution) | Dynamics (during execution) | |
| What are the structural entities (e.g., declarations, expressions, statements, modules) and how do they fit together, perhaps with punctuation? | What are the non-structural rules that define a legal program (e.g., type checks, argument-parameter matching rules, visibility rules, etc.)? | What does a program do? What effects do each of the forms of a well-structured, legal program have on the run-time environment? |
Why are there three parts instead of two? That is, why can’t syntax be completely aligned with statics? Here’s why. While everyone might agree that the following is structurally malformed:
#<include > stdio.h
main() int }
printf["Hello, world!\n");]
{
the following program looks good in terms of “structure” but it’s actually meaningless since it violates a contextual rule that says identifiers must be declared before use:
int main() {
printf("%d\n", x);
}
We say the latter program has static semantic errors because they can be detected by a compiler before the program is ever run. This is in contrast to a dynamic semantic error, which can only be detected at run time.
Statics and DynamicsYou’ve probably heard the distinction between “static” and “dynamic” before. Perhaps you know that “static typing” involves type checking is done prior to program execution and “dynamic typing” involves checking during program execution. Most languages do a little of both, but one or the other usually predominates. Sometimes you get a good deal of both: in TypeScript for example, you have a set of static types which is much larger and completely different than the eight dynamic types. Fun.
Defining the Syntax
Let‘s see how we would formally specify the syntax for a trivial language of numbers, variables, simple arithmetic, assignment statements, and print statements. Assume we’ve gone through the first two design phases: we‘ve (1) identified the audience and scope, and (2) and sketched out example programs. Let’s say this is one of the programs that shows all the features:
radius = 55.2 * (-cos(2.8E-20) + 89) % 21; // assignment statement
the_area = π * radius ** 2; // a built-in identifier
print hypot(2.28, 3 - radius) / the_area; // print statement
The first part of phase three is the syntax definition. Let’s begin by putting our ideas into words. A first pass: “Programs are structured as a sequence of one or more statements, each of which is an assignment or print statement, with expressions formed with numbers, variables, function calls, and the usual arithmetic operators, which can have parentheses when needed. Assignment statements are simple, with only an identifier on the left-hand side. The print statement begins with the special keyword print and prints only a single expression. Comments look like the slash-slash comments of C-like languages.”
Natural language isn’t super precise, so let’s try to tighten this up. Let’s get started by defining the structure of programs, statements, and expressions:
Program = Statement+
Statement = id "=" Exp ";"
| print Exp ";"
Exp = numeral
| id
| id "(" (Exp ("," Exp)*)? ")"
| "-" Exp
| Exp ("+" | "-" | "*" | "/" | "%" | "**") Exp
| "(" Exp ")"
An identifier is the computer science word for a name you attach to an entity (a variable, constant, function, type, parameter, or similar thing). Let’s decree that identifiers begin with a letter, and can have letters, digits, and underscores (examples: x, last_attempt, p1, p2, overTheLimit, bot8675309_jEnNy). We will call letters, digits, and underscores identifier characters (idchars). But let’s also decree that print is not allowed to be an identifier (so we don’t confuse people)!
This means we have to carefully define the print keyword very carefully. It’s not just the five letters p, r, i, n, and t. If it were then the program:
printy;
would be legal! A compiler would immediately match the first five characters as the keyword print then match a legal expression, namely the identifier $y$. Not what we want! We want the character sequence print to not bleed into any following characters that might be part of an expression. In other words, print must not be immediately followed by an identifier character. Also, it’s good to explicitly exclude print from our category of identifiers, otherwise we could write:
print = 5;
print print;
That’s ugly. So we have to both prevent print from being an identifier and prevent it from bleeding into potential expressions. Here’s how we do it. Let’s use the ~ symbol in our notation to exclude things:
print = "print" ~idchar idchar = letter | digit | "_" id = ~print letter idchar*
print followed by the identifier y.
Now time for numerals. We’ll keep things in decimal only (no worries about hex or binary), and use the times-ten-to-the notation from popular programming languages:
numeral = digit+ ("." digit+)? (("E" | "e") ("+" | "-")? digit+)?
Looking good. But what about things like letter and digit? Should we define these? Nah, let’s say that in our definition schema that these things are built-in. Let’s in fact “build in” all of the following:
letter, for any Unicode letterdigit, for"0".."9"alnum, forletter | digitupper, for any Unicode uppercase letterlower, for any Unicode lowercase letterhexDigit, fordigit | "a".."f" | "A".."F"any, for any Unicode character at all
Lexical vs. Phrase Syntax
Did you notice that some of our syntax categories (Program, Statement, Exp) were capitalized and others (id, numeral, letter, digit) were not? Why did we do this?
The latter things are very primitive. They can not have internal spaces. We call these tokens. Think of these as basic “words”. The former, called phrases, are more complex. Think of them as sentences. They are made up of tokens that can be separated by spaces. Tokens and phrases are very different, so we should denote them differently.
So what are spaces—those characters that can separate tokens from each other? We’ll take them to be any Unicode space character, and assume space is predefined. But we also want to separate tokens with comments. Let’s define how tokens should look in our language, and add them to the special space category:
space += "//" (~"\n" any)*
Let’s take a deeper look into how the lexical and phrase syntaxes differ. As a specific example, this program:
print( // ⿇🌿 420 );
is made up of these characters:
SPACE SPACE LATIN SMALL LETTER P LATIN SMALL LETTER R LATIN SMALL LETTER I LATIN SMALL LETTER N LATIN SMALL LETTER T LEFT PARENTHESIS TAB SOLIDUS SOLIDUS SPACE KANGXI RADICAL HEMP HERB LINEFEED DIGIT FOUR DIGIT TWO DIGIT ZERO SPACE RIGHT PARENTHESIS SEMICOLON
Following the lexical syntax, skipping the spaces (and comments), we get the token stream:
print
(
num(420)
)
;
Following the phrase syntax, we can uncover the underlying parse tree:
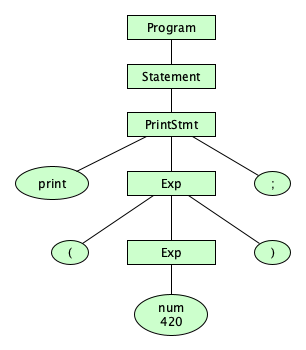
A very important thing to note: The frontier of the parse tree is the token stream.
The parse tree ends at tokens, not characters
Please take the time to consider how silly it would be if the parse tree expanded all of the lexical rules down to characters. Having the parse tree stop at tokens is a good example of what we would call “breaking a complex problem down into simpler parts.”
Another term for “parse tree” is concrete syntax tree (CST).
Ambiguity
How are we doing so far? We are able to distinguish well-structured programs from all other Unicode strings. But there are some things we haven’t dealt with yet. For one, we have some strings with multiple structural forms. For example, the phrase 9-3*7 can be parsed in two ways:
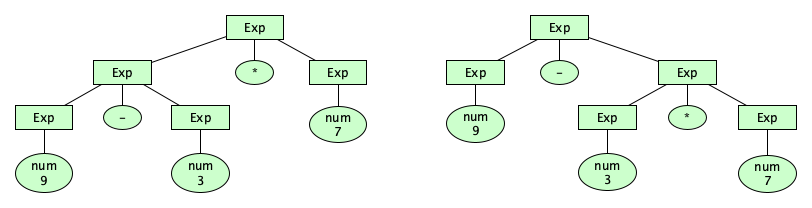
Having more than one parse tree for a given input string means that our syntax description is ambiguous. It’s possible to remove this particular kind of ambiguity in the syntax. Here’s how.
Precedence
We can create rules that force certain operators to be applied before others; that is, the precedence of operators can be enforced in our syntax definition. To do so, we define additional syntactic categories. We say:
- An expression is a sequence of one or more terms, separated by additive operators.
- A term is a sequence of one or more factors, separated by multiplicative operators.
- A factor is made up of primaries, separated by exponentiation operators, or a factor can just be a negated primary.
- A primary is the most basic expression possible: either a simple identifier, a numeral, a call, or a parenthesized expression. Parentheses allow unlimited nesting.
So let’s revise our syntax specification:
Exp = Term ( ("+" | "-") Term )*
Term = Factor ( ("*" | "/" | "%") Factor )*
Factor = Primary ( "**" Primary )*
| "-" Primary
Primary = numeral | id | id "(" (Exp ("," Exp)*)? ")" | "(" Exp ")"
Great! Now there is one and only one parse tree for that previously problematic expression:
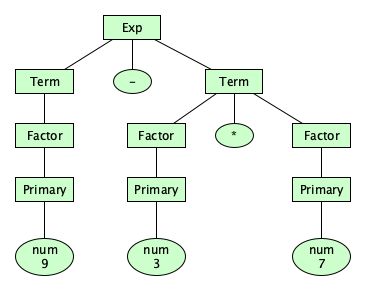
Note that the new syntax has forced the binary operators into a precedence hierarchy!
+and-have the lowest precedence.*,/, and/have the next higher precedence.**has the highest precedence.
Of course, you can think of parenthesized expressions as being done before anything else, though we don’t usually think of these as operators.
-3**2 be parsed? In Python exponentiation precedes negation, like -(3**2). In Elm, negation precedes exponentiation, like (-3)**2. We’ll followed JavaScript and simply disallow this expression (forcing programmers to use parentheses in this case)! Show how our syntax captures this design.
-3**2 as an expression, but it does allow -3+2 and -3*2. Why did we care only enough to ensure negation did not mix with exponentiation, but we were fine with it mixing with addition and multiplication?
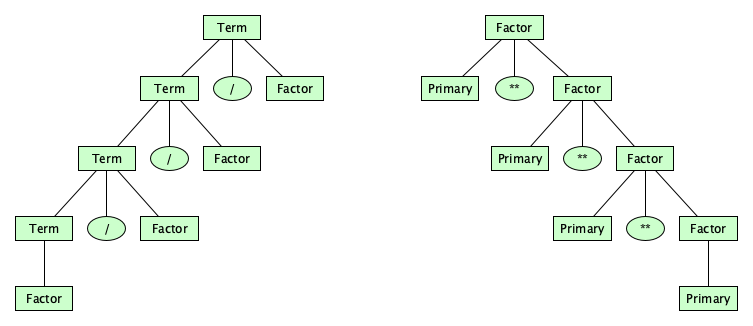
Associativity
Wait, we are not done with structuring our operators just yet. The way things stand now, the parse tree for 3-8-5 looks pretty flat:
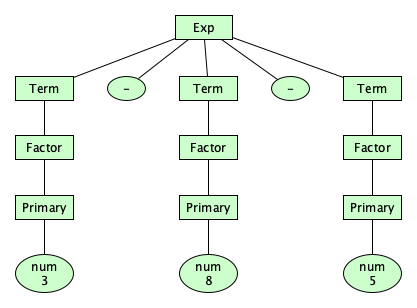
It doesn’t suggest whether we mean to compute (3-8)-5 (which would be -10) or 3-(8-5) (which would be 0). We can give a syntax that makes this clear. In our design, let’s make the additive and multiplicative operators left-associative and the exponentiation operator right-associative:
Exp = Exp ("+" | "-") Term
| Term
Term = Term ("*" | "/" | "%") Factor
| Factor
Factor = Primary "**" Factor
| "-" Primary
| Primary
How the heck does this work? Study these parse trees, and hopefully the insight will come to you! (Hint: remember the syntax is designed to force the tree to “come out” a certain way.
Grammars
The notation we’ve been using to precisely describe our syntax is a kind of a grammar. In fact, it is very close to a specific kind of grammar called an Ohm Grammar. Ohm requires a bit more ceremony than what we’ve been using so far, but it has a ton of convenient features. We’ll just jump right in and extend our work so far to a complete and working Ohm grammar. Ohm requires us to name our grammars, so let’s go ahead and name this programming language Astro:
Astro {
Program = Statement+
Statement = id "=" Exp ";" --assignment
| print Exp ";" --print
Exp = Exp ("+" | "-") Term --binary
| Term
Term = Term ("*" | "/" | "%") Factor --binary
| Factor
Factor = Primary "**" Factor --binary
| "-" Primary --negation
| Primary
Primary = id "(" ListOf<Exp, ","> ")" --call
| numeral --num
| id --id
| "(" Exp ")" --parens
numeral = digit+ ("." digit+)? (("E" | "e") ("+" | "-")? digit+)?
print = "print" ~idchar
idchar = letter | digit | "_"
id = ~print letter idchar*
space += "//" (~"\n" any)* --comment
}
When you are designing your language, you will build up your grammar iteratively, from increasingly more complex examples, and test the grammar as you go. Tools will help you here! If you are using Ohm, and you should, take advantage of the use the Ohm Editor. This is an amazing tool for experimenting with programming languages.
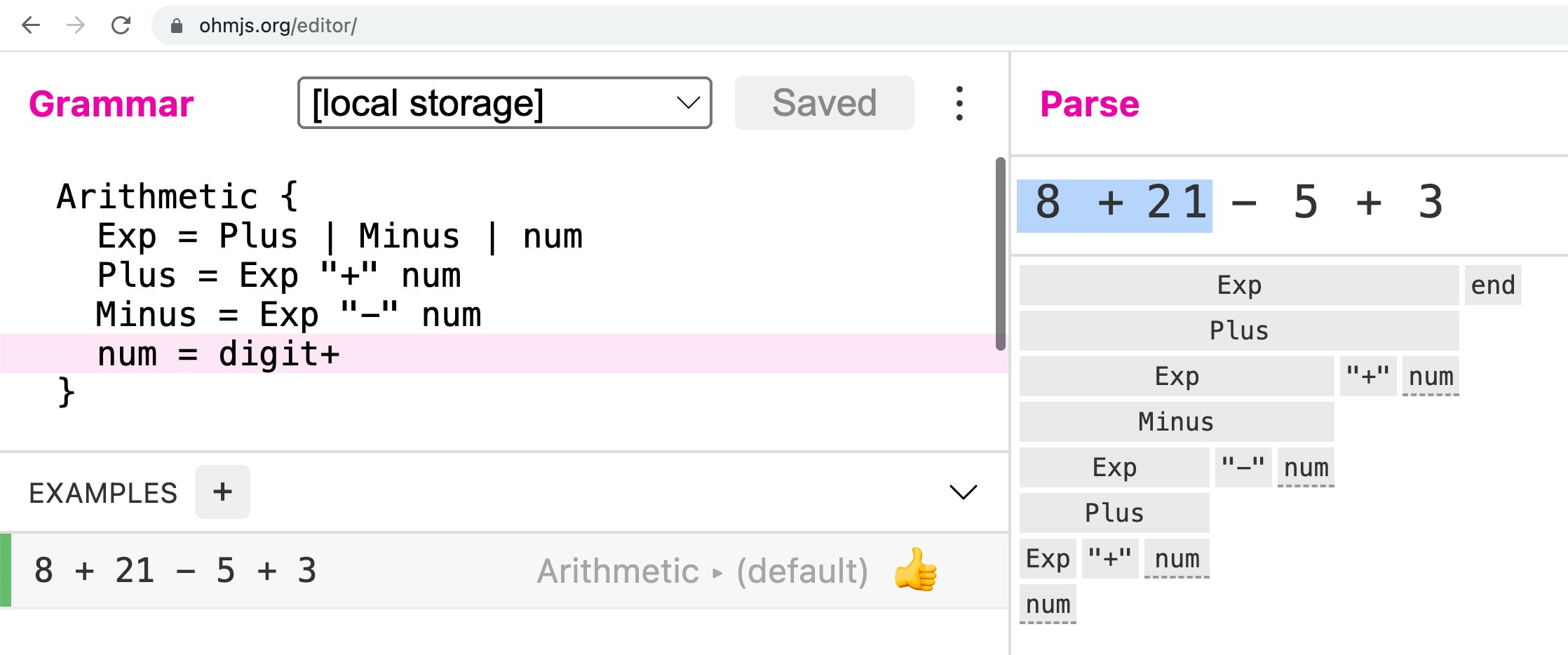
In the upper left panel, design your grammar. You can load/save from your browser’s local storage, and even publish gists to GitHub. In the lower left panel, enter test cases: both tests you want to succeed (thumbs up) and those you want to fail (thumbs down). The right panel is an interactive concrete syntax tree for the currently selected test case.
This tool will save you a lot of time.
It is an essential component of your language design toolbox.
How essential is it?Unless your language is trivial, tools like the Ohm Editor are very important! Design is an iterative process, and creativity is enabled and enhanced with immediate feedback. So you should design with tools that allow you to experiment and test your ideas.
That said, it is true that in practice, many production-level compilers do not use Ohm or related tools like ANTLR, Bison, etc.—they do everything by hand. But developers that go this route will write their grammar tests concurrently with their design.
Let’s do a code-along with the Ohm Editor for developing the Astro grammar. During the code-along, note how examples are done first, and note how we will evolve from the basics to more complex features, bringing in notions such as a precedence and associativity where needed.During the code-along, bits of Ohm will be introduced as needed. In a subsequence course unit, we will cover Ohm in detail.
Defining the Statics
Question: Does the grammar we defined above for Astro capture the following (desirable) rule:
“You can only use an identifier if it has been previously assigned to.”
Answer: It does not.
print x; a legal program according to the grammar?
Enforcing this rule requires knowledge of context. That is, the syntactic rule for producing expressions such as calls and arithmetic operations would need to somehow know which identifiers appeared on the left hand side of some previous assignment statement. This turns out to be so hard that even designers of real programming languages omit enforcement of contextual rules from the grammar! In fact, while the official grammar for Java will not derive this program:
class A {2 / == {{;
and report a syntax error, a Java compiler will say that this program:
class A {int x = y;}
is structurally well formed according to the official syntax of the Java language! The compilation unit consists of a type declaration that is a class declaration whose body consists of a field declaration with a type, a name, and an initializing expression which is an identifier. But we know this program is not legal, since the identifier y has not been declared. It’s not only Java that has grammars overspecifying things: pretty much every programming language uses a grammar to define structural rules only, and specifies contextual rules in prose, or in a separate semantic definition.
For Astro, we will “define” the following contextual rules:
- The following identifiers are built-in:
π, a numbersqrt, a function of exactly one argumentsin, a function of exactly one argumentcos, a function of exactly one argumenthypot, a function of exactly two arguments
- An identifier cannot be used in an expression unless it is one of the built-in identifiers or has been previously assigned to.
- All function calls must accept the proper number of arguments.
- The built-in identifiers cannot be assigned to.
- Identifiers declared as functions can only be called, not used in any other context. Identifiers declared as numbers cannot be called.
For more complex languages, the statics definition (contextual rules) can be quite large. Here are some things that might appear:
- Identifiers have to be declared before they are used.
- Identifiers may not be used in a place where they may have not yet been initialized.
- Identifier declarations must be unique within a scope, unless a language provides overloading.
- All expressions must be used according to their type.
- Identifiers must be used according to (1) their scope, (2) their access modifiers (private, protected, package, public, whitelist, blacklist, ...), and (3) any other meta-level attributes (enumerable, configurable, writable, deletable, callable, ...).
- Arguments must match up with parameters in terms of number, order, name, mode, and type.
breakandcontinuestatements may only appear in a loop.returnstatements may only appear in a function it’s possible to encode these restrictions in the grammar, but it would be ugly).- All paths through a function must have a return.
- All possible matches in a pattern match expression, or a switch statement, must be covered.
- When inheriting from a base class with abstract methods, or implementing an interface, all abstract methods must be implemented, or the derived class must be declared abstract.
- All declared local variables must be subsequently read, and declared private functions must be called.
Defining the Dynamics
The dynamics for most programming languages are given in prose. If your language is simple enough, a formal semantic definition is possible. We’ll not be studying formal semantics at this time, but feel free to study the formal definitions of the small languages Astro and Bella on your own. These language definitions also have an informal semantics, so check those out too. For a more complex language, informal semantics is generally the way to go; check out the definition of Carlos for ideas.
Prototyping
During your language design, you will want to whip up a simple interpreter to at the very least make sure your design is reasonable. You may wish to developer your interpreter in parallel with your language design.
Ohm was designed for prototyping programming languages, so it is a natural choice. The Ohm Editor, as we just saw, helps you design the syntax. To write an actual interpreter, we’ll have to go much deeper into Ohm. We’ll be doing this in our next unit of study in this course, which is, indeed, a deep study of Ohm.
Examples
Many well-known programming languages have published, formal definitions. You can find them by searching the web.
For this class, we will be studying five little languages crafted especially to help you in your study of language design and implementation. We will be studying them in order, building upon previous languages and learning new things as we progress. This will allow us to introduce the huge topic of language processing in a practical setting, writing real compilers for real languages. The languages are Astro, Bella, Carlos, Dax, and Ekko.
Astro

We all begin as a white belt in every new endeavor. We will start, then, with a very simple, almost trivial, language. All it has are numbers, arithmetic operators, variables, and a few pre-defined constants and functions. Here’s an example program:
rAd1uS = 55.2 * (-cos(2.8E-20) + 89) % 21; the_area = π * rAd1uS ** 2; print(hypot(2.28, 3 - rAd1uS) / the_area); // woohoo 👻
There are only two kinds of statements: assignments and print statements. Expressions include numbers, variables, function calls, arithmetic expressions with +, -, *, /, %, and **, and can be parenthesized. We will cover the official definition of the language, and use the language to motivate a formal study of syntax.
When studying this language, we’ll learn about the separation of context-free syntax from contextual rules. Contextual rules include such things as: having to match the number of arguments in a call with the number of defined parameters, rudimentary type checking, and not allowing assignments to read-only variables.
As Astro will be our first language, we will use it as a case study to learn the amazing Ohm Language Library to build an interpreter. The details of how the interpreter is constructed are covered in the course notes on Ohm.
Bella

Our second language has a few things Astro does not: a richer set of operators, variable declarations, and user-defined functions. The contextual rules for Bella are much richer than that of Astro, since we now have actual declarations, and scope! Here’s an example program:
let dozen = 12;
print dozen % 3 ** 1;
function gcd(x, y) = y == 0 ? x : gcd(y, x % y);
while dozen >= 3 || (gcd(1, 10) != 5) {
dozen = dozen - 2.75E+19 ** 1 ** 3;
}
We will first look at the official specification, introducing all sorts of interesting concepts. Then we’ll study a real, actual Bella compiler. Here we learn about designing and architecting a compiler, building the components (analyzer, optimizer, and generator), and getting 100% test coverage. The compiler source code is on GitHub.
Carlos
In our third language, we encounter arrays, structs, and optionals: our first language that is basically useful. If you are taking the compiler course for which these notes were written, Carlos is a good example of the minimal language complexity you will need for your term project.
const languageName = "Carlos";
function greeting() {
return random(["Welcome", "こんにちは", "Bienvenido"]);
}
print("👋👋👋");
repeat 5 {
print(greeting() + " " + languageName);
}
We’ll be visiting the language’s official specification and a compiler on GitHub. The compiler (of course!) uses the Ohm Language Library.
There’s no separate page of notes describing the compiler. After studying the Astro and Bella compilers, you’ll be able to find your way around the code on GitHub (there’s documentation). And don’t worry, it’s development and usage will be covered in class, and the teaching staff can help you with any questions you might have.
Dax

Language number four is a functional language, that is, a language with no assignments! The only bindings of names to entities happens when passing arguments to parameters, though there is that famous let declaration which nicely sugars a function call: it’s nicer to say let x = 5 in x * y end than {x => x * y}(5).
Here’s a sample program to get the feel for the language:
let
gcd = {x => {y ==> y == 0 ? x : gcd y (x % y)}};
z = 5
in
[1, 3, z] |> filter {x => x > 2} |> map {x => x ** 2} |> print
then
"hello" |> substring 2 5 |> print
then
print (gcd 33 99) // This is fine, you don't HAVE to use |>
end
If you have not yet seen languages with the awesome |> operator, here’s your chance to be wowed.
We will discuss the language design and compiler later in the course.
Ekko

Our fifth language, Ekko (starting with E like Erlang and Elixir, which greatly influence it), is a kind of experimental language that deals quite a lot with time.
Ekko mixes styles of asynchronous programming from JavaScript and the distributed process-orientation of Erlang and Elixir: Ekko’s future objects are based on JS promises, and its processes communicate via messages as in Erlang. There’s also quite a bit more temporal goodness, including timeout calls, value histories with time travel (influenced by older versions of Elm), and even explicit parallelism.
More Examples
Students in previous iterations of the course have designed and implemented their own languages. Here’s a sampling of language over the past decade or so. (Please note that there is a very wide variety of quality in these examples. They are presented here without any evaluative commentary as to whether they are suitable building blocks for one’s own project.)
- NOPE
- SALAMIS
- Groovy
- RexScript
- Pipethon
- Swatch
- Rimere
- DungeonScript
- TEMP_JS
- WebRogue
- AniScript
- DinarScript
- Fe
- Funk
- CubeScript
- InfantJS
- Forge
- Brainrot
- 3DTee
- Hexlang
- Piece+
- Crit
- Moss
- Pulsar
- Fling
- Ye Olde Dragon
- Lion Code
- Melody
- Leibniz
- SnackScript
- Funktion
- JohnLang
- IdolScript
- Gitz
- NOOL
- Misc
- Hooper
- NewLang
- Harmony
- Quanco
- Ante
- PANIC
- Convaneo
- Storm
- Glyph
- CloudScribe
- Snake
- Logos
- RiyalScript
- Boum
- Blvd
- Sous
- River
- Rat
- Cod
- GLHF
- BuildLang
- Banana
- Pyth-on-Point
- Dino
- Sanscript
- Kis
- YALL*E
- Jazz
- Barista
- LangY
- MODE
- Bang
- Squishi
- SussyScript
- CoffeeMaker
- YeeHaw
- Gullienne
- ElectricScript
- Barista
- Shrek--
- Chinese Baozi
- IcedCoffee
- Chloe
- T.O.A.L.
- Pirates Code
- Leg
- Kobe
- Cringe--
- Bismath
- Plumb
- PokerScript
- Pandemonium
- Easi
- Palet
- VikingScript
- Speare
- Ahtohallan
- VineScript
- Big Mama’s Kitchen
- Medley
- Custom
- LemonScript
- Aegis
- Midi-Cholorian
- qcq
- HYPER!
- RealHotGirlScript
- Pivot
- SnekQL
- Respec++
- r0b0p
- uwuScript
- PawvaScript
- Cuttlefish
- Inkling
- Casper
- StoneScript
- FUZZ++
- Goof3
- Scriptofino
- 101Script
- Jen
- Olive
- Nebula
- J4
- Alula
- Pycante
- Whiteboard
- Favascript
- Queen
- MemeScript
- Skrt
- JCaml
- Boozie
- Deeg
- AvaJava
- Yah
- Roo
- Agate
- AboveAverageScript
- TeaScript
- YACBL
- Yoda
- Spitfire
- Derpodile
- GollumScript
- Singularity
- KobraScript
- Min
Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- What are the four phases of programming language design? (1) Working out the desired context (audience, purpose, scope), (2) sketching example programs, (3) formalizing the syntax and semantics, and (4) prototyping.
- Name five programming language paradigms. A few are: imperative, declarative, structured, object-oriented, functional, applicative, concatenative, logic, protocol-oriented, aspect-oriented, array, event-driven, dataflow, agent-based. There are others
- What were the four big ideas in programming languages mentioned in Bret Victor’s Future of Programming talk? (1) Direct manipulation of data rather than showing the code, (2) Goals and constraints rather than procedures, (3) Spatial representation of code rather than textual representations, and (4) Concurrent computation rather than sequential
- What language did Alan Kay feature in his Programming Languages video? eToys
- What are some things to decide upon while undertaking language design? The audience, the purpose, the scope, the problem domain it is target to, whether it is reasonable or esoteric, whether it has a simple foundation or favors pragmatism, its concurrency model.
- In what essay did Bret Victor lay out several principles that languages and programming environments should follow to aid their users’ learning? Learnable Programming
- What is abstract syntax? The structure of a program without regard to the specific syntax used to represent it.
- Draw the abstract syntax tree for the expression
8 * (13 + 5).* / \ 8 + / \ 13 5 - What is the name of the specification of JavaScript’s abstract syntax? ESTree
- At what web address can you find and interactive JavaScript AST builder? https://rtoal.github.io/js-ast/
- What are five approaches of showing (concrete) syntactic structure in popular programming languages? Curly braces, indentation, terminal-ends, parentheses, postfix
- What is an example of a programming language for which newlines are significant? Answers include Python and Ruby
- What is syntactic sugar? Syntax within a programming language that is designed to make certain phrases more clear, concise, or elegant than the basic forms defined in the language.
- What is syntactic salt? Syntax within a programming language that is designed to make certain phrases more confusing, verbose, or awkward than the basic forms defined in the language.
- What is a candygrammar? A syntax that looks sweet and natural language-like that appears good but turns out to be bad for you.
- What is a golfing language? A language designed to be as terse as possible, often for the purpose of helping you win shortest-possible code challenges.
- What are some examples of golfing languages? CJam, Pyth, Stax, GolfScript, 05Ab1E
- What are three styles of programming language definition? Informal, formal, and executable
- What is the difference between syntax and semantics? Syntax deals with program structure. Semantics deals with program meaning.
- What is the difference between a language’s statics and its dynamics? Statics refers to the rules that can be checked at compile time. Dynamics refers to the rules that can only be checked at run-time.
- What are syntax definitions generally split into lexical and phrase syntaxes? Lexical syntax defines how individual characters are grouped in to words (tokens), while phrase syntax defines how these tokens are combined to form larger structures.
- What is a parse tree? A tree that describes the syntactic structure of a program as defined by the language’s syntax.
- The frontier of the parse tree is the program’s __________. Token stream
- A parse tree is also called a __________. Concrete syntax tree
- What does it mean for a syntactic specification to be ambiguous? There exists at least on program that has more than one parse tree.
- What attributes of operators are generally used to disambiguate a syntactic specification? Precedence and associativity
- Why do most language definitions provide a formal syntax but not a formal semantics? Syntax is normally context free and very easy to mathematically formalize; semantic definitions often feature quite a few ad-hoc constraints and lots of contextual information which is more clunky to formalize.
- What tool is provided by the authors of the Ohm library to help you prototype a new language design? The Ohm Editor
- What was the title of Alex Warth’s dissertation? Experimenting with Programming Languages
- What are some examples of legality rules that are considered too hard to be captured in a grammar and are thus typically defined within a program’s static semantics? You can only use an identifier if it has been previously assigned to, all function calls must accept the proper number of arguments, the built-in identifiers cannot be assigned to, identifiers declared as functions can only be called, not used in any other context, identifiers declared as numbers cannot be called, type checking, access checking (private, public), declared identifiers must be initialized or must be read. (There are many more.)
- What example programming languages have been designed for this course? Astro, Bella, Carlos, Dax, Ekko
Summary
We’ve covered:
- The cycle of language design phases
- What to know before undertaking language design
- Pointers to excellent articles and essays about language design
- Two videos (one by Alan Kay, one by Bret Victor) on languages and language design
- How to begin the language design process
- Questions to ask while designing your language
- Concepts and features to think about when sketching during design
- Abstract Syntax
- Concrete Syntax
- The use of the Ohm Editor in language prototyping
- (Formal) Language Definition
- Brief notes on five example languages