Language Theory
Motivation
Why would we even want a theory of languages?
Languages are the means by which we communicate information (and computation). A formal theory of language allows us to rigorously define what language is, and from that, determine exactly what various languages can represent and say.
Preliminaries
Theories of computation, including language theory, start from the idea that information can be represented as a string of symbols.
Information is that which informs. In information theory, it is the resolution of uncertainty. The more you know, the less uncertain you are.
Information theory and language theory both use a fair amount of logical and mathematical notation. If you need to brush up, see these logic notes and these math notes.
Symbols
A symbol is a primitive unit of data representation. Information can be represented with strings of symbols. For example:
91332.3e-81
⚠️ Stay BEHIND the yellow line! ⚠️
<ul><li>你好</li><li>ᎣᏏᏲ</li><li>ᐊᐃᓐᖓᐃ</li></ul>
/Pecs/Los Angeles/Berlin/Madrid//1 2/3 0/2 2/2 0/3 2///
(* (+ 88 3) (- 9 57))
int average(int x, int y) {return (x + y) / 2;}
{"type": "dog", "id": "30025", "name": "Lisichka", "age": 13}
∀α β. α⊥β ⇔ (α•β = 0)
1. f3 e5 2. g4 ♛h4++
Alphabets
Symbols are chosen from an alphabet, such as $\{0,1,2,3,4,5,6,7,8,9\}$ for the language of natural numbers, or $\{0,1,2,3,4,5,6,7,8,9,.,\textrm{e},\textrm{E},+,-\}$ for the language of floating-point numbers.
Here are some examples of alphabets:
- $\mathsf{BinaryDigits} = \{ 0, 1 \}$
- $\mathsf{DecimalDigits} = \{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 \}$
- $\mathsf{HexDigits} = \mathsf{DecimalDigits} \cup \{ a,b,c,d,e,f,A,B,C,D,E,F \}$
- $\mathsf{Suits} = \{ ♠️,♥️,♦️,♣️ \}$
- $\mathsf{PropositionalLogicSymbols} = \{ p, q, r, \prime, (, ), \neg, \wedge, \vee, \supset, \equiv \}$
- $\mathsf{Unicode} = \{ \sigma \mid \sigma \textrm{ is a Unicode character} \}$
Strings
A string is a finite sequence of symbols over some alphabet. Here are three example strings over the alphabet $\{a,b,c\}$:
- $abbcbabb$
- $b$
- $aaa$
When talking about strings, often might use variables to represent them. Variable names must be symbols outside the alphabet. For example:
- Given the alphabet $\{a,b,c\}$, we can choose as variables $w$, $x$, and $y$, and bind them to strings, say, by writing $w = abbcbabb$, $x = b$, $y = aaa$.
The length of a string is the number of symbol occurrences in the string. It is denoted by the outfix operator $|\ldots|$. Examples:
- $|aba| = 3$
- $|b| = 1$
- If $w = abbac$, then $|w| = 5$
The empty string, denoted $\varepsilon$, is the (unique) string of length 0.
The concatenation of two strings $x$ and $y$ is the string obtained by appending $y$ to the end of $x$. This is written $xy$. Repeated concatenation uses superscript notation defined as follows: $w^0 = \varepsilon$, $w^1 = w$, $w^2 = ww$, $w^3=www$, and $w^{k+1} = ww^k$. Examples:
- If $x = abb$ and $y = ca$ then $xy = abbca$.
- $w\varepsilon = \varepsilon w = w$.
- $(abc)^5 = abcabcabcabcabc$.
Unfortunate NotationString concatenation looks like numeric multiplication, and string repetition looks like numeric exponentiation, but behaviorally, concatenation is like numeric addition and repetition is like numeric multiplication. Python gets this right:
$ python >>> "abc" + "def" 'abcdef' >>> "abc" * 3 'abcabcabc'Python’s notation is way better! The mathematical notation is inconsistent with typical uses of concatenation and superscripts, so you have to get used to it. Booooo, math.
The reversal $w^R$ of a string $w$ is the string formed by reversing $w$; formally $\varepsilon^R = \varepsilon$ and $(\sigma w)^R = w^R \sigma$ for some symbol $\sigma$.
$x$ is a substring of $y$ iff $\exists v. \exists w. y = vxw$.
Because we are defining languages with an eye toward modeling computation, we almost always require alphabets to be non-empty and finite, and require all strings to have a finite (but unbounded) length. Even with a finite alphabet and finite-length strings, you can still have an infinite number of strings!
Importantly, the set of strings is enumerable, and the infinity of strings is countable.
Formal Languages
A formal language is a set of strings over some alphabet. That’s it. That’s the definition. If a string $w$ is a member of a language $L$ we say $w$ is an utterance of $L$.
Here are some example languages:
- $\{ w \in \{ a, b \}^* \mid w \textrm{ has the same number of $a$’s as $b$’s} \}$
- $\{ w \in \{ a, b \}^* \mid w \textrm{ has more $a$’s than $b$’s} \}$
- $\{ w \in \{ a, b \}^* \mid \textrm{the first and last symbol of $w$ are the same} \}$
- $\{ a^nb^n \mid n \geq 0 \}$
- $\{ a^ib^j \mid j = 2^i \}$
- $\{ a^ib^jc^k \mid k = i + j \}$
- $\{ a^ib^jc^k \mid k = \mathsf{Ackermann}(i,j) \}$
- $\{ ww \mid w \in \{a,b\}^* \}$
- $\{ ww^R \mid w \in \{a,b\}^* \}$
- $\{ 1^n \mid \textrm{$n$ is prime} \}$
- $\{ w \in \{ 0, 1 \}^* \mid w \textrm{ is a binary numeral greater than 55} \}$
- $\{ w \in \{ 0, 1 \}^* \mid w \textrm{ is a binary numeral divisible by 5} \}$
- $\{ w \in \textsf{DecimalDigit}^* \mid w \textrm{ is a valid MasterCard number} \}$
- $\{ w \in \mathsf{Unicode}^* \mid w \textrm{ contains the substring } \textit{dog} \}$
- $\{ w \in \mathsf{Unicode}^* \mid w \textrm{ is a valid Python program} \}$
- $\{ w \in \mathsf{Unicode}^* \mid w \textrm{ is a valid JavaScript program} \}$
- $\{ w \in \mathsf{Unicode}^* \mid w \textrm{ is a valid Swift program} \}$
- $\{ w \in \mathsf{Unicode}^* \mid w \textrm{ is a valid Swift program that prints the integers from 1 to 10} \}$
Why are languages sets?A language as a set of strings is actually quite useful. It distinguishes strings “in” the language from those not in the language. A language is a set of (its legal) utterances.
Now it’s true that this definition does not say anything about the “meaning” of each utterance. That has to be handled separately. But we are off to a good start.
Language Operations
Because languages are sets, $\varnothing$ is a language, and the union ($L_1 \cup L_2$) and intersection ($L_1 \cap L_2$) of languages make perfect sense. So does the cardinality of a language, $|L|$, the number of strings in the language. In addition:
- The concatenation of two languages $L_1$ and $L_2$ is $L_1L_2 = \{xy \;|\; x \in L_1 \wedge y \in L_2\}$. Repeated concatenation uses superscripts: $L^0 = \{\varepsilon\}$, $L^1 = L$, $L^2 = LL$, $...$, $L^{k+1} = LL^k$.
- The Kleene Closure of $L$ is $L^* = L^0 \cup L^1 \cup L^2 \cup ... = \{w_1w_2...w_k \;|\; w_i \in L \wedge k ≥ 0\}$.
- The Positive Closure of $L$ is $L^+ = L^1 \cup L^2 \cup L^3 \cup ... = \{w_1w_2...w_k \;|\; w_i \in L \wedge k > 0\}$.
Therefore, given an alphabet $\Sigma$, the following are languages over $\Sigma$:
- $\varnothing$, the empty language, the language of no strings
- $\{ \varepsilon \}$, the language containing the empty string and nothing else
- $\Sigma$, the language of all possible one-symbol strings
- $\Sigma^2$, the language of all possible two-symbol strings
- $\Sigma^3$, the language of all possible three-symbol strings
- $\Sigma^*$, the language of all possible strings over the alphabet $\Sigma$
The Infinite Library
The language $\Sigma^*$ (the language of all possible strings over an alphabet) is fascinating. It’s basically the infinite library, which contains every book that has ever been written and that could possibly ever be written, i.e., every single possible arrangement of symbols. It contains solutions to climate change and world hunger, the cures for all cancers, and all human histories and futures (yours included). It also contains an infinite amount of misinformation. The problem is, you can’t distinguish what is right from wrong.
When you “know” everything, you know nothing.
For any language $L$ over the alphabet $\Sigma$, we have $L \subseteq \Sigma^*$. Since we must specify an alphabet for each language, the complement of a language makes sense. It is defined as follows: $\overline{L} = \Sigma^* - L$.
Let’s see the language operations in use. Suppose we are given the alphabet $\Sigma = \{a,b\}$, and two languages over $\Sigma$, which we’ll define as $L_1 = \{ba, b\}$ and $L_2 = \{abb, bb\}$.
Then:
- $\Sigma^* = \{\varepsilon,a,b,aa,ab,ba,bb,aaa,aab,aba,abb,baa,bab,...\}$
- ${L_1}^* = \{\varepsilon,ba,b,baba,bab,bba,bb,...\}$
- ${L_1}^+ = \{ba,b,baba,bab,bba,bb,...\}$
- $L_1L_2 = \{baabb, babb, bbb\}$
- $L_1 \cup L_2 = \{ba, b, abb, bb \}$
- $L_1 \cap L_2 = \varnothing$
Random Language Facts
Here are some interesting theorems about languages. Ready? Let $\Sigma$ be an alphabet and $A$, $B$, $C$, and $D$ be languages over $\Sigma$ (i.e., subsets of $\Sigma^*$). Then:
- $A\varnothing = \varnothing A = \varnothing$
- $A\{\varepsilon\} = \{\varepsilon\}A = A$
- $(AB)C = A(BC)$
- $(A \subseteq B) \wedge (C \subseteq D) \Rightarrow AC \subseteq BD$
- $A(B \cup C) = AB \cup AC$
- $(B \cup C)A = BA \cup CA$
- $A(B \cap C) \subseteq AB \cap AC$
- $(B \cap C)A \subseteq BA \cap CA$
- $A^* = A^+ \cup \{\varepsilon\}$
- $n ≥ 0 \Rightarrow A^n \subseteq A^*$
- $n ≥ 1 \Rightarrow A^n \subseteq A^+$
- $A \subseteq AB^*$
- $A \subseteq B^*A $
- $A \subseteq B \Rightarrow A^* \subseteq B^*$
- $A \subseteq B \Rightarrow A^+ \subseteq B^+$
- $AA^* = A^*A = A^+$
- $\{\varepsilon\} \in A$ iff $A^+ = A^*$
- $(A^*)^* = A^*A^* = A^*$
- $(A^*)^+ = (A^+)^* = A^*$
- $A^*A^+ = A^+A^* = A^*$
- $(A^*B^*)^* = (A \cup B)^* = (A^* \cup B^*)^*$
- $(C = AC \cup B) \Rightarrow (C = A^*B)$
Language Definition
Formal languages were developed to help us study the foundations of mathematics and computation. It’s true that in this context, languages are just sets, so we can communicate them in set notation, for example:
- $\{ w \mid w \textrm{ is a legal floating point numeral} \}$
But wait, even though that definition used mathematical symbols in part, there was a big informal piece between the curly braces. This can be a problem. Informal definitions lack precision. Like what even are floating point numerals? We can list as many examples as possible to get the idea. Maybe we can list them all, say something like { 0, 8, 3.5, 13.55, 3E8, 3.2E89, 5.111E+2, 21.34E-2, 1e-8, 2.55e+233, ...}. This is also not precise. Let’s try harder, with a definition:
- The set of all strings that begin with a sequence of one or more decimal digits,
- optionally followed by a dot then one or more decimal digits
- optionally followed by:
- an
Eor ane - then, optionally, a
+or- - then a sequence of one or more decimal digits
- an
Better, but still not very satisfying: it is very verbose, kind of confusing, and hard to tell if it is even right. It is “precise” but it is still informal ! We need something better. Something formal. And people have in fact invented many formalisms for language definition in the past! The techniques fall into two main categories:
- Definition by Generation
- We can give a formalized set of rules that systematically generate all and only those strings in the language. The language is then the set of all string generated by the language. The primary mechanism for this is the generative grammar.
- Definition by Recognition
- We can give a formal definition of a process that determines, for a given string, whether or not it is in the language. The language is then the set of all strings recognized by the process. A analytic grammar is common for this approach.
Generative Grammars
A generative grammar is a list of rules for generating all and only the strings in a particular language. The rules have variables that get replaced in order to generate the actual strings of the language. One of the variables is the start variable.
Let’s create a a grammar for our floating point numeral language. Recall the alphabet for this language is $\{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ., E, e, +, – \}$. We’ll use four variables, $\{ \mathit{numeral}, \mathit{fractionalPart}, \mathit{exponentPart}, \mathit{digit} \}$. The rules will be:
$ \begin{array}{lcl} \mathit{numeral} & \longrightarrow & \mathit{digit}^+ \; \mathit{fractionalPart}? \; \mathit{exponentPart}?\\ \mathit{fractionalPart} & \longrightarrow & \texttt{"."} \; \mathit{digit}^+ \\ \mathit{exponentPart} & \longrightarrow & (\texttt{"E"} | \texttt{"e"}) \; (\texttt{"+"} | \texttt{"–"})? \;\mathit{digit}^+ \\ \mathit{digit} & \longrightarrow & \texttt{"0"} .. \texttt{"9"} \end{array} $
There are multiple grammar notations out there; the one used here features the following notation:
→means “can be replaced with”+means “one or more”*means “zero or more”?means “optional”|means “or”- Double quotes delimit the actual symbols in the language you are defining, while variables are unquoted
- Parentheses are for grouping
..makes a range over individual symbols (yeah, it’s kind of shorthand)
If $G$ is a grammar, then $L(G)$ is the language defined by the grammar $G$. A string is in $L(G)$ if it is derivable from $G$’s initial rule, repeatedly replacing instances of a rule’s left hand pattern with its right hand side, until you get completely rid of the variables and are left only with strings in the language’s alphabet. Here is an example derivation:
$ \begin{array}{lcl} \mathit{numeral} & \Longrightarrow & \mathit{digit}^+\;\mathit{fractionalPart}?\;\mathit{exponentPart}? \\ & \Longrightarrow & \texttt{338}\;\mathit{fractionalPart}?\;\mathit{exponentPart}? \\ & \Longrightarrow & \texttt{338.}\;\mathit{digit}^+\;\mathit{exponentPart}? \\ & \Longrightarrow & \texttt{338.253}\;\mathit{exponentPart}? \\ & \Longrightarrow & \texttt{338.253}\;(\texttt{"E"} | \texttt{"e"}) \; (\texttt{"+"} | \texttt{"–"})? \;\mathit{digit}^+ \\ & \Longrightarrow & \texttt{338.253e}\;(\texttt{"+"} | \texttt{"–"})? \;\mathit{digit}^+ \\ & \Longrightarrow & \texttt{338.253e}\;\mathit{digit}^+ \\ & \Longrightarrow & \texttt{338.253e18} \\ \end{array} $- $\mathtt{3}$
- $\mathtt{8.5501e-88}$
- $\mathtt{5E+11}$
and that the following are not in the language:
- $\mathtt{-2.3E1}$
- $\mathtt{55.e+2}$
- $\texttt{^^Dog!}$
By the way, note that there can be many grammars that specify the same language. For example, here’s another grammar for the floating-point numeral language:
$ \begin{array}{lcl} \mathit{numeral} & \longrightarrow & \mathit{digit}^+ \; (\texttt{"."} \; \mathit{digit}^+)? \; ((\texttt{"E"} | \texttt{"e"}) \; (\texttt{"+"} | \texttt{"–"})? \;\mathit{digit}^+)?\\ \mathit{digit} & \longrightarrow & \texttt{"0"} .. \texttt{"9"} \end{array} $
If the first grammar above was called $G_1$ and this grammar was called $G_2$, we would have $L(G_1) = L(G_2)$.
A single language can be defined by multiple distinct grammars.
Time to practice.
Practice with Grammars
If you think about it, coming up with a grammar for a language you have in mind is an endeavor similar to programming: you know what you want to end up with, but you need to create the very formal, precise steps to get you there. How do you get good at coming up with grammars? Certainly it helps to have a mentor and learn tricks of the trade over time with practice. Whether you have a mentor or not, it does help to start with a whole bunch of examples. So with that in mind, here are a handful of grammars for you to study:
Here is a grammar for the language of integer binary numerals divisible by 2:
$\begin{array}{lcl} \mathit{even} & \longrightarrow & \texttt{"–"}?\;(\texttt{"0"}\,|\,\texttt{"1"})^* \; \texttt{"0"} \\ \end{array}$
And one for the language of integer decimal numerals divisible by 5:
$\begin{array}{lcl} \mathit{divisibleByFive} & \longrightarrow & \texttt{"–"}?\;\mathit{digit}^*\;(\texttt{"0"}\,|\,\texttt{"5"}) \\ \mathit{digit} & \longrightarrow & \texttt{"0"} .. \texttt{"9"} \end{array}$
And for the language $\{ \varepsilon, 0, 1, 01, 10, 010, 101, 0101, 1010, \ldots\}$ of alternating zeros and ones:
$\begin{array}{lcl} \mathit{alternatingZerosAndOnes} & \longrightarrow & \mathit{startsWithZero} \;|\; \mathit{startsWithOne} \\ \mathit{startsWithZero} & \longrightarrow & \varepsilon\;|\;\texttt{"0"}\;\mathit{startsWithOne} \\ \mathit{startsWithOne} & \longrightarrow & \varepsilon\;|\;\texttt{"1"}\;\mathit{startsWithZero} \end{array}$
The language $\{0^i1^j \mid i \textrm{ is even} \wedge j \textrm{ is odd} \}$:
$\begin{array}{lcl} \mathit{evenZerosThenOddOnes} & \longrightarrow & (\texttt{"00"})^*\;\texttt{"1"}\;(\texttt{"11"})^* \end{array}$
The language $\{ a^nb^n \mid n \geq 0 \}$ = $\{ \varepsilon, ab, aabb, aaabbb, aaaabbbb, \ldots\}$:
$\begin{array}{lcl} \mathit{anbn} &\longrightarrow & \varepsilon \mid \texttt{"a"}\;\mathit{anbn}\;\texttt{"b"} \end{array}$
A different grammar for that language (it’s good to see multiple perspectives):
$\begin{array}{lcl} \mathit{anbn} &\longrightarrow & (\texttt{"a"}\;\mathit{anbn}\;\texttt{"b"})? \end{array}$
The language of palindromes over $\{a,b\}$:
$\begin{array}{lcl} \mathit{pal} & \longrightarrow & \varepsilon \;|\;\texttt{"a"}\;|\;\texttt{"b"}\;|\;\texttt{"a"}\;\mathit{pal}\;\texttt{"a"}\;|\;\texttt{"b"}\;\mathit{pal}\;\texttt{"b"} \\ \end{array}$
The language of parentheses, curly braces, and square brackets, in which everything is properly balanced and nested, for example ()[{()}[[]]()]:
$\begin{array}{lcl} \mathit{balanced} & \longrightarrow & (\texttt{"("}\;\mathit{balanced}\;\texttt{")"}\mid\texttt{"["}\;\mathit{balanced}\;\texttt{"]"}\mid\texttt{"\{"}\;\mathit{balanced}\;\texttt{"\}"})^*\\ \end{array}$
The language $\{ a^nb^nc^n \mid n \geq 0 \}$:
$\begin{array}{lcll} \mathit{anbncn} & \longrightarrow & (\texttt{"a"}\;anbncn\;x\;\texttt{"c"})? & \\ \texttt{"c"}\;x & \longrightarrow & x\;\texttt{"c"} & \textrm{—move $c$'s to the right of the $x$'s} \\ \texttt{"a"}\;x & \longrightarrow & \texttt{"ab"} & \textrm{—only make a $b$ after an $a$ ...} \\ \texttt{"b"}\;x & \longrightarrow & \texttt{"bb"} & \textrm{—... or after a $b$} \end{array}$
The language $\{ a^{2^n} \mid n \geq 0 \}$:
$\begin{array}{lcll} \mathit{aToTwoToN} & \longrightarrow & \mathit{double}^*\;\texttt{"a"}\;\mathit{right} & \textrm{—mark the end} \\ \mathit{double}\;\texttt{"a"} & \longrightarrow & \texttt{"aa"}\;\mathit{double} & \textrm{—move right, doubling $a$'s as you go} \\ \mathit{double}\;\mathit{right} &\longrightarrow & \mathit{right} & \textrm{—got to end, no more to double} \\ \mathit{right} & \longrightarrow & \varepsilon \\ \end{array}$
The language $\{ww \mid w \in \{a,b\}^* \}$:
$\begin{array}{lcll} \mathit{ww} & \longrightarrow & \texttt{"a"}\;ww\;x \mid \texttt{"b"}\;ww\;y \mid \mathit{middle} & \\ \mathit{middle}\;x & \longrightarrow & \mathit{middle}\;\texttt{"a"} & \textrm{—an $x$ generates an $a$} \\ \mathit{middle}\;y & \longrightarrow & \mathit{middle}\;\texttt{"b"} & \textrm{—a $y$ generates a $b$} \\ \texttt{"a"}\;x & \longrightarrow & x\;\texttt{"a"} & \textrm{—move $a$'s to end} \\ \texttt{"a"}\;y & \longrightarrow & y\;\texttt{"a"} & \\ \texttt{"b"}\;x & \longrightarrow & x\;\texttt{"b"} & \textrm{—move $b$'s to end} \\ \texttt{"b"}\;y & \longrightarrow & y\;\texttt{"b"} & \\ \mathit{middle} & \longrightarrow & \varepsilon & \textrm{—drop midmarker when no longer needed} \\ \end{array}$
Why are we studying such silly languages?
Obviously we need to get to the point where we can design grammars for real programming languages. But studying the fundamentals of language and grammars with bite-size pieces helps us uncover patterns that we can use in designing our large grammars. It also gives insights into what is easy and what is hard. For example: some grammars above looked very straightforward and some required bizarre “marker” symbols that were passed around to...seemingly “compute” something. The scientist in you should wonder if distinctions like that are fundamental in some sense, and if so, how can we capture this state of affairs formally.
We are going to do lots of derivations for many of the grammars above.
Predefined Variables
Let’s get practical and stop repeating ourselves so much. We’re going to take the following variables as being previously defined:
- $\mathit{digit}$, for $\texttt{"0".."9"}$
- $\mathit{hexDigit}$, for $\mathit{digit}\;|\;\texttt{"A".."F"}\;|\;\texttt{"a".."f"}$
- $\mathit{letter}$, for any Unicode letter
- $\mathit{alnum}$, for $\mathit{letter}\;|\;\mathit{digit}$
Now we can define the language of words starting with a letter and containing letters, digits, and underscores only:
$\begin{array}{lcl} \mathit{id} & \longrightarrow & \mathit{letter}\;(\mathit{alnum}\;|\;\texttt{"_"})^* \end{array}$
And the language of simple hex colors in HTML: Hash followed by 3 or 6 hex digits:
$\begin{array}{lcl} \mathit{simpleHexColor} & \longrightarrow & \texttt{"#" }\mathit{threeHexDigits}\;\mathit{threeHexDigits}? \\ \mathit{threeHexDigits} & \longrightarrow & \mathit{hexDigit}\;\mathit{hexDigit}\;\mathit{hexDigit} \end{array}$
When we start getting more sophisticated, it helps to “design” a language by first listing out utterances and non-utterances, to get a feel for how your grammar should look. Let’s create a language for integer expressions with addition, subtraction, multiplication, division, exponentiation, negation, and parentheses. What should and should not be in this language?
| Examples | Non-Examples |
|---|---|
432 24*(31/899+3-0)/(54/-2+(5+2)*3) (2) 8*(((3-6))) |
43 2 24*(31////)/(5+---+)) [fwe]23re31124efr$#%^@ --2-- |
Now, based on what we wrote, let’s try to capture the structure of utterances in prose. Here is a first pass: “An expression is either (1) an integer, (2) a negated expression, (3) two expressions with a binary operator between them, or (4) a parenthesized expression.” This gives us:
$\begin{array}{lcl} \mathit{exp} & \longrightarrow & \mathit{digit}^+ \\ & | & \texttt{"–"} \; \mathit{exp} \\ & | & \mathit{exp} \; (\texttt{"+" | "–" | "*" | "/" | "%" | "**"}) \; \mathit{exp} \\ & | & \texttt{"(" }\mathit{exp}\texttt{ ")"} \end{array}$
How did we do? Let’s see if we can derive something interesting:
$ \begin{array}{lcl} \mathit{exp} & \Longrightarrow & \mathit{exp}\texttt{ + }\mathit{exp} \\ & \Longrightarrow & \texttt{– }\mathit{exp}\texttt{ + }\mathit{exp} \\ & \Longrightarrow & \texttt{– }\mathit{digit}\texttt{ + }\mathit{exp} \\ & \Longrightarrow & \texttt{–8+ }\mathit{exp} \\ & \Longrightarrow & \texttt{–8+ }\mathit{exp}\texttt{ * }\mathit{exp} \\ & \Longrightarrow & \texttt{–8+ }\mathit{digit}\;\mathit{digit}\texttt{ * }\mathit{exp} \\ & \Longrightarrow & \texttt{–8+5}\;\mathit{digit}\texttt{ * }\mathit{exp} \\ & \Longrightarrow & \texttt{–8+55* }\mathit{exp} \\ & \Longrightarrow & \texttt{–8+55* }\mathit{digit} \\ & \Longrightarrow & \texttt{–8+55*3} \\ \end{array}$Derivations can get pretty long. Is there a better way to see how our strings are made?
Derivation Trees
Here’s a better way to “show” the derivation we just performed:
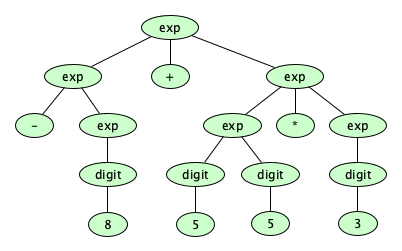
But wait! There can be more than one way to derive a string, and sometimes (but not always) the resulting derivation tree is different for different derivations:
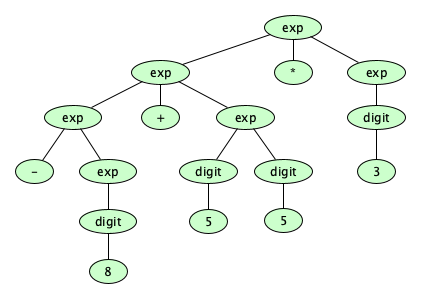
-5*(34/-55+(21-8)+233). How many distinct trees are there for this string?
Is having multiple derivation trees for a given string a big deal?
Ambiguity
A grammar is ambiguous if there exists more than one derivation tree for a given string. Natural language grammars are often ambiguous.
- Lawyers give poor free advice.
- Teacher strikes idle kids.
- Seven foot doctors sue hospital.
- Stolen painting found by tree.
- Enraged cow injures farmer with ax.
- Two sisters reunited after 18 years at checkout counter.
- The train left the station crowded and dirty.
- Landmine claims dog arms company.
- Hershey bars protest.
- They cooked for the first time on the stove.
But for a programming language, we don’t really like ambiguity, since the derivation tree tells us the structure of a program (its syntax) from which we wish to assign a meaning (semantics). Under the widely accepted meanings of decimal integers and arithmetic operations, those two trees we saw earlier suggest meanings of $157$ (multiply-then-add) and $141$ (add-then-multiply). Yikes!
One way to get rid of ambiguity in our language is to force operator precedence and associativity in the grammar itself. The following convention has arisen:
- Expressions are terms separated by left-associative additive operators (
+,-) - Terms are factors separated by left-associative multiplicative operators (
*,/,%) - Factors are primaries separated by right-associative exponentiation operators (
**) - Primaries are numerals, negated primaries, or parenthesized expressions.
Because expressions are made up of terms and terms are made up of factors, the utterance 1+3*2 is made up of two terms, 1 and 3*2. Therefore we say multiplication has higher precedence than addition. This is the only way to make the derivation tree! There is no ambiguity here. Now what about (1+3)*2? This expression has a single term, which has two factors: (1+3) and 2. Note how the parentheses matter!
Work out why all of this is true. Make the derivation trees and show that for the given expression, there is only one possible tree.
But what about the utterance 5-1-3? Should this be structured to do the leftmost subtraction first (yielding 1) or the rightmost first (yielding 7)? This is where associativity comes in. Tradition says subtraction is left-associative, so we want a structure with:
–
/ \
– 3
/ \
5 1
Exponentiation is traditionally right-associative, so 3**2**5 would desire a derivation structure as:
**
/ \
3 **
/ \
2 5
Do you know what else might be ambiguous? Expressions like -2**2. In Python, exponentiation is done before negation, so this expression produces -4. In Elm, negation happens first, so the expression evaluates to 4. JavaScript uses a grammar that prevents the expression from being derived by the grammar! This is a good thing. Let’s do it.
We are now ready to give the non-ambiguous grammar for our integer arithmetic expression language:
$ \begin{array}{lcl} \mathit{exp} &\longrightarrow& \mathit{exp} \;(\texttt{"+"}\,|\,\texttt{"–"})\; \mathit{term} \\ & | & \mathit{term} \\ \mathit{term} &\longrightarrow& \mathit{term} \;(\texttt{"*"}\,|\,\texttt{"/"}\,|\,\texttt{"%"})\; \mathit{factor} \\ & | & \mathit{factor} \\ \mathit{factor} &\longrightarrow& \mathit{primary}\;(\texttt{"**"}\;\mathit{factor})? \\ & | & \texttt{"–"}\;\mathit{primary} \\ \mathit{primary} &\longrightarrow& \mathit{numeral} \\ & | & \texttt{"("} \; \mathit{exp} \; \texttt{")"} \\ \mathit{numeral} & \longrightarrow & \mathit{digit}^+ \end{array} $
We are going to make a long-ish expression and show that it has one and only one derivation tree.
-3**2 cannot be derived from this grammar.
Formal Definition
We’ve seen that we use grammars to formally describe mathematical objects we call languages. But we were kind of hand-wavy in defining what a grammar is and how derivations work. Grammars are mathematical objects themselves and so can be described formally. Here is how:
A grammar (technically, a generative grammar) is a quadruple $(V, \Sigma, R, S)$ where:
- $\Sigma$ is the alphabet of the language being described
- $V$ is a set of variables, such that $\Sigma \cap V = \varnothing$
- $R \subseteq (V \cup \Sigma)^*V(V \cup \Sigma)^* \times (V \cup \Sigma)^*$ is a set of rules
- $S \in V$ is the start variable
The formal definition of $R$ looks complex but it really just says “the left hand side must contain at least one variable.” That is all. Super reasonable too! It’s there so once you get rid of all the variables, you don’t keep going.
Formalisms are pretty minimalThis formal definition has left out our amazing
|,?,*,+,(,),", and..symbols. This is okay because strictly speaking they are not needed: they are just shorthands (“syntactic sugar”) for the simple rules. When formalizing things for a theory, you generally want a very minimal notation. When formalizing, you will need to desugar the convenience symbols:
- $\alpha \to \beta\,?$ becomes $\alpha \to \beta \mid \varepsilon$
- $\alpha \to \beta^*$ becomes $\alpha \to \varepsilon \mid \alpha\beta$
- $\alpha \to \beta^+$ becomes $\alpha \to \beta \mid \alpha\beta$
- $\alpha \to \beta_1 \mid \ldots \mid \beta_n$ becomes multiple rules: $\alpha \to \beta_1, \;\ldots, \;\alpha \to \beta_n$
Then, because all variables in the formalize are required to be symbols, you rename the variables to single symbols, allowing you to get rid of quotation marks.
Let’s do an example. Let’s formalize the grammar for the language $\{ a^nb^nc^n \mid n \geq 0 \}$ given earlier as:
$\begin{array}{lcl} \mathit{anbncn} & \longrightarrow & (\texttt{"a"}\;anbncn\;x\;\texttt{"c"})? \\ \texttt{"c"}\;x & \longrightarrow & x\;\texttt{"c"} \\ \texttt{"a"}\;x & \longrightarrow & \texttt{"ab"} \\ \texttt{"b"}\;x & \longrightarrow & \texttt{"bb"} \end{array}$
We first desugar the convenience symbols, reduce variables to a single symbol, and elide quotation marks:
$\begin{array}{lcl} s & \longrightarrow & \varepsilon \\ s & \longrightarrow & asxc \\ c x & \longrightarrow & x c \\ a x & \longrightarrow & ab \\ b x & \longrightarrow & bb \end{array}$
Now we put the rules into a relation (set of pairs), and call out the variables, alphabet, and start symbol, giving us the formal description of the grammar: $$ (\{s,x\}, \{a,b,c\}, \{(s,\varepsilon), (s,asxc), (cx,xc), (ax,ab), (bx,bb)\}, s) $$
Another example. A grammar for the language $\{ a^nb^n \mid n \geq 0 \}$ is $$(\{s\}, \{a,b\}, \{(s,\varepsilon), (s,asb)\}, s)$$
Derivations can be formalized too:
As can the language defined by a grammar:
This definition says that, for $G = (V,\Sigma,R,S)$, the language $L(G)$ is the set of all strings from $\Sigma^*$ that can be derived from start symbol $S$ using the rules in $R$.
TerminologyWe’ve called $\,V$ the set of variables and $\,\Sigma$ the alphabet. You may encounter folks who call $\,V$ the set of non-terminals and $\,\Sigma$ the set of terminals. No matter what the names, $\,V \cap \Sigma=\varnothing$.
Well...actually...there are still other folks that call $\,V$ a vocabulary and make it the set of all variables plus the alphabet symbols, then consequently tell you now that $\,\Sigma \subset V$ and require $S \in V - \Sigma$.
This is the way of things in logic and mathematics. Different authors describe this stuff differently.
History TimeThe development of formal languages originated with early work by Emil Post, Axel Thue, and others working in the early 20th century on questions related to the foundations of mathematics and computation. Post created a system for transforming strings, called a Post Canonical System. We now know a much simpler formulation of Post’s work, namely a semi-Thue system, a.k.a. string rewriting system. An SRS can rewrite any string into string other; it is nothing more than a tuple $(\Sigma, R)$ where $\Sigma$ is the alphabet of symbols and $R \subseteq \Sigma^* \times \Sigma^*$ is the rewriting relation.
That’s it!
However, despite their simplicity, they are nasty to use to define useful languages. Adding variables makes a special kind of a rewriting system known as a grammar which are useful. Brilliant! This is why all computer scientists encounter grammars and only very few have heard of string rewriting systems.
Can every language be described with a grammar?
Because a grammar can be encoded as a string, there are only a countable number of possible grammars. But the number of languages over a given alphabet, $\mathcal{P}(\Sigma^*)$, is uncountable (remember Cantor’s Theorem?). So there exist languages that cannot be described by any grammar.
Definition time! The set of all languages that can be described by a grammar is called $RE$, the set of recursively enumerable languages.
Now interestingly, there are languages that, while they cannot be described by any grammar, can be (finitely) described by other means. If a language can be (finitely) described somehow, with or without a grammar, it is called a finitely describable language. The set of all finitely describable languages is called $FD$.
Clearly (prove this) $FD$ is countable. So $FD \subset \mathcal{P}(\Sigma^*)$. It’s true that $RE \subset FD$, too, which we will prove later. Visually, we can show these proper set containments like so:
Restricted Grammars
Noam Chomsky did a lot of work with grammars. Here cared about much more than which utterances were in a language—he wanted to be able to uncover the structure of the utterances. We saw above how derivation trees conveyed information! But you can’t always get a derivation tree, can you?
aabbcc using the grammar for $\{ a^nb^nc^n \mid n \geq 0 \}$ shown earlier, the one with rules $s \to \varepsilon$, $s \to asxc$, $cx \to xc$, $ax \to ab$, and $bx \to bb$. Can you do it? Why not?
Chomsky took to restricting the kinds of rules you could have in a grammar, in order to guarantee derivation trees. In his 1959 paper, On Certain Formal Properties of Grammars he wrote:
The weakest condition that can significantly be placed on grammars is that $F$ be included in the class of general, unrestricted Turing machines. The strongest, most limiting condition that has been suggested is that each grammar be a finite Markovian source (finite automaton).The latter condition is known to be too strong; if $F$ is limited in this way it will not contain a grammar for English. The former condition, on the other hand, has no interest. We learn nothing about a natural language from the fact that its sentences can be effectively displayed .... The reason for this is clear. Along with a specification of the class $F$ of grammars, a theory of language must also indicate how, in general, relevant structural information can be obtained for a particular sentence generated by a particular grammar.
Chomsky called the unrestricted grammar a Type-0 grammar, then introduced a restriction that would enable structural information to be gained from a derivation: namely, that every rule must be of the form $\alpha A\beta \to \alpha\gamma\beta$, where $A$ is a variable and $\alpha$, $\gamma\neq \varepsilon$, and $\beta$ are strings of variables and language symbols. Each rule, then, replaces only a single variable—that’s why you always get a derivation tree. 🙌 A grammar with this restriction is called a Type-1 grammar. Because the rewriting of $A$ can only happen when $A$ is prefixed by $\alpha$ and followed by $\beta$, the rewriting of $A$ is context-sensitive.
A second restriction, yielding Type-2 grammars, was that every rule be of the form $A \to \gamma$, where $\gamma \neq \varepsilon$. Each rule replaces a single variable, but free of context—you can replace $A$ with $w$ anywhere in a string.
Because he was exploring the idea of restrictions in general, Chomsky introduced a third restriction to get the correspondence with Markovian sources: requiring every rule be of the form $A \to \sigma$ or $A \to \sigma B$ where $A$ and $B$ are variables and $\sigma$ is a language symbol. This restriction yields a Type-3 grammar.
Chomsky’s grammars don’t produce languages containing the empty string $\varepsilon$. However, in modern computer science, there is no reason to forbid it. To produce modern versions of the Type-1 through Type-3 grammars:
- For Type-2 and Type-3 grammars, we can allow any rule to produce $\varepsilon$.
- For Type-1 grammars, we have to be really careful, allowing the start symbol to be replaced by $\varepsilon$ only when it appears alone on the left-hand side of a rule.
The Chomsky Hierarchy
Chomsky’s restrictions were designed so that, for $i \in \{0,1,2\}$, every Type-($i+1$) grammar is also a Type-$i$ grammar. These relationships hold whether or not the grammars are enhanced, as above, to generate languages with the empty string.
Each family of grammar is capable of generating a certain family of languages (from now on, we are going to assume languages can include empty strings):
- The class of languages generable by a Type-0 grammar is $RE$, the Recursively Enumerable Languages.
- The class of languages generable by a Type-1 grammar is $CS$, the Context-Sensitive Languages.
- The class of languages generable by a Type-2 grammar is $CF$, the Context-Free Languages.
- The class of languages generable by a Type-3 grammar is $REG$, the Regular Languages.
Therefore it follows that:
$$ REG \subseteq CF \subseteq CS \subseteq RE $$But is also turns out the containment is proper!
$$ REG \subset CF \subset CS \subset RE $$As each class is strictly larger than the one before it, we have a hierarchy of expressive power in our grammars. The proper containment relationship is now known as the Chomsky hierarchy, and is visualized like so:
Over time, folks assigned names to the Type-0, Type-1, Type-2, and Type-3 grammars. It’s good to memorize them:
| Language Class | Chomsky’s Name | Generated By |
|---|---|---|
| Recursively Enumerable ($RE$) | Type-0 | Unrestricted Grammar |
| Context-Sensitive ($CS$) | Type-1 | Context-Sensitive Grammar |
| Context-Free ($CF$) | Type-2 | Context-Free Grammar |
| Regular ($REG$) | Type-3 | Regular Grammar |
Other Restricted Grammars
There are so many more kinds of grammars. So many interesting ones. Let‘s just look at a few.
Noncontracting Grammars (NCG)
A Noncontracting Grammar (NCG) is a grammar where $R \subseteq (V \cup \Sigma)^*V(V \cup \Sigma)^* \times (V \cup \Sigma)^*$ such that $\forall(\alpha, \beta) \in R$. $|\alpha| \leq |\beta|$. That is, the right hand side of every rule is at least as long as the left hand side. These capture exactly the same set of languages as Chomsky’s CSGs, the O.G. Type-1 languages (no $\varepsilon$s allowed).
An Essentially Noncontracting Grammar (ENCG) is a Noncontracting grammar that (1) may include the rule $S \to \varepsilon$ and (2) must not include $S$ in any right-hand side of any rule. These capture exactly the same set of languages as modern CSGs—namely, the modern Type-1 languages (empty strings allowed). In most modern (computer science) presentations of language theory, ENCGs are used instead of CSGs.
Why are these interesting? They correspond to computations with bounded memory. We’ll see this when we study automata theory.
Let’s examine the differences and similarities between ENCGs and Context-Sensitive grammars.
Linear Grammars
A linear grammar is a context-free grammar in which the RHS of every rule has at most one variable.
Formally, $R \subseteq V \times (\Sigma^* V\Sigma^* \cup \Sigma^*)$.
Variations on Regular Grammars
Strictly speaking, a regular grammar is a linear grammar in which the sole non-terminal of every rule is at the end (in which case the grammar is right linear, an RLG), OR in which the sole non-terminal of every rule is at the beginning (in which case the grammar is left linear, an LLG).
Although this definition is slightly different from Chomsky’s, we can prove this new definition generates the exact class of languages as Chomsky’s plus the $S \to \varepsilon$ rule—the regular languages $REG$. So in practice, it doesn’t matter much. If you want to be super-specific, you can call the O.G. form “Chomsky Type-3 Grammar” and the new style “Modern Regular Grammar.”
Formally, for right-linear grammars, $R \subseteq V \times (\Sigma^* V \cup \Sigma^*)$.
Formally, for left-linear grammars, $R \subseteq V \times (V \Sigma^* \cup \Sigma^*)$.
And More...
Interested in this stuff? You might want to explore indexed grammars, tree-adjoining grammars, range concatenation grammars, prefix grammars, and yes, even more.
Review
Let’s review these grammars. As a teaser for what’s coming up later in the course, there’s a bonus column.
| Type | Class | Generated By | Corresponds to |
|---|---|---|---|
| 0 | $RE$ | Grammar
| Anything computable |
| 1 | $CS$ | Essentially Noncontracting (ENCG)
| Bounded memory computation |
| 2 | $CF$ | Context-free (CFG)
| Efficient stack-based memory computation |
| 3 | $REG$ | Right Linear (RLG)
| No-memory computation |
Left Linear (LLG)
|
Factoid of the day, which we will give without proof: the class of languages definable by full linear grammars is strictly larger than the class of regular languages and strictly smaller than the class of context-free languages.
“Context Sensitive” is a controversial nameThis is super confusing! Intuitively, a context-sensitive language is any language that is not context-free. But the term context-sensitive got attached to the Type-1 languages. So you will have to suss things out by context.
A Compact Notation for Regular Grammars
Any language generated by a regular grammar can be recast into a single rule that uses |, *, +, and ?, with no variables on the right hand side. (See any theory book for a proof.) For example, the alternating zeros and ones language above can be rewritten as:
$s \longrightarrow \texttt{"0"}?(\texttt{"10"})^*\texttt{"1"}? \mid \texttt{"1"}?(\texttt{"01"})^*\texttt{"0"}?$
Because there is only one variable on the left hand side, we traditionally omit the rule itself and do away with the quotation marks, leaving only a single expression to define the language:
$0?(10)^*1? \mid 1?(01)^*0?$
This form is called a regular expression, which you should not confuse with regular expressions from real programming languages, which are massively more powerful. In the study of language theory, regular expressions are much weaker, as they can only define regular (type-3 with empty strings) languages.
Oh, and it is traditional, in most formal presentations of these things, to replace $a\mid b$ with $a+b$, to replace $a?$ with $a+\varepsilon$, and to replace $a^+$ with $aa^*$.
Examples:
- Even binary numerals: $(\texttt{-} + \varepsilon)(0+1)^*0$
- Nonnegative binary numerals divisible by 4: $0 \mid (0+1)^*00$
- Even number of $a$'s followed by an odd number of $b$'s: $(aa)^*(bb)^*b$
- Nonnegative decimal numerals divisible by 5: $(0+1+2+3+4+5+6+7+8+9)^* (0+5)$
- Strings over $\{a,b,c\}$ containing exactly two $a$’s: $(b+c)^*a(b+c)^*a(b+c)^*$
Analytic Grammars
A generative grammar formally specifies a language by generating all and only those strings in the language. Generative grammars are fine when you only care about what is in the language and what is not. This is good enough for mathematicians and philosophers. But if you are reading these notes, you are probably a computer scientist, and you don’t want to generate all the strings of a language. You want to check whether a string is in the language. And you don’t want ambiguity! You want a single parse tree for each string. We want a grammar that doesn’t generate strings from rules; we want a grammar that matches strings against rules. This idea is extremely powerful when you need to write compilers or interpreters. Such a language definition is called an analytic grammar.
The biggest difference between generative and analytic grammars is in the handling of alternatives. In a generative grammar $G$, $L(G)$ contains all strings that can be generated by applying rules whenever possible. For example, the rule $x \rightarrow y\,|\,z$ means you can replace an $x$ with an $y$ or a $z$, so you can generate both. So the generative grammar:
$s \longrightarrow \texttt{"a"}\;|\;\texttt{"ab"}$
describes the language $\{ a, ab\}$.
In an analytic grammar, the rules are deterministic; you don’t get to pick one or the other. So $A\,/\,B$ means: “Try to match $A$. If you can, the rule matches and you are done. Otherwise (and only otherwise), try to match $B\,$”. So:
$s \longleftarrow \texttt{"a"}\;/\;\texttt{"ab"}$
recognizes the language $\{ a \}$, but:
$s \longleftarrow \texttt{"ab"}\;/\;\texttt{"a"}$
recognizes the language $\{ a, ab \}$.
Unlike generative grammars, analytic grammars feature special lookahead operators, including the negative lookahead operator (~) and the positive lookahead operator (&). This enables the definition of non-context-free languages, despite having only one symbol on the left-hand side! Here’s an analytic grammar for the non-context-free language $\{ a^nb^nc^n \,\mid\, n \geq 0 \}$:
$ \begin{array}{lcl} \mathit{s} &\longleftarrow& \texttt{&} \; (\mathit{x}\texttt{ "c"}) \; \texttt{"a"}^+\;\mathit{y} \\ \mathit{x} &\longleftarrow& \texttt{"a"} \; \mathit{x}? \; \texttt{"b"} \\ \mathit{y} &\longleftarrow& \texttt{"b"} \; \mathit{y}? \; \texttt{"c"} \end{array} $
Analytic grammars are actually awesomeOur notes on Syntax and How To Write a Compiler, and our definitions of the programming languages Astro, Bella, and Carlos are all based on analytic grammars. It’s true that most of the literature focuses on generative grammars, but analytic grammars totally shine in computer science applications and especially in compiler and interpreter writing.
Semantics
Up to now, our only definition of “language” has been a set of strings over some alphabet, and we’ve looked at many ways to describe a set of strings. A description of the set of strings in the language is called a syntax. But you probably have a sense that languages exist to convey meaning. The way meaning is attached to utterances of a language is known as semantics.
For instance, we saw the language of simple arithmetic expressions above. We gave the grammar:
$\begin{array}{lcl} \mathit{exp} & \longrightarrow & \mathit{digit}^+ \\ & | & \texttt{"–"} \; \mathit{exp} \\ & | & \mathit{exp} \; (\texttt{"+" | "–" | "*" | "/" | "%" | "**"}) \; \mathit{exp} \\ & | & \texttt{"(" }\mathit{exp}\texttt{ ")"} \end{array}$
and said the language WAS the set of strings generated by this grammar. To give the utterances meaning, we could define a function mapping every utterance to its meaning, which in this case would be a number.
It’s customary to define the semantics of a language by a set of rules that show how to evaluate syntactic forms of the language. Here’s a pretty straightforward definition:
How do we deal with semantics in formal language theory? Interestingly, semantics tends to live in a different theory—not in “formal” language theory, but rather in a theory affectionately known as PLT.
Programming Language Theory (PLT)
Formal Language Theory, it seems, is only concerned with defining or determining which strings are in a language and which are not. It is not concerned with assigning meaning to those strings. We have to go beyond what we’ve learned so far to deal with questions of meaning. Linguists study semiotics. Computer Scientists study programming language theory, otherwise known as PLT.
In PLT, programming languages are, yes, fundamentally sets of strings, but where each of the members of the language is a program, representing a computation. The concern of the syntactic aspect of the formal (contrived) languages we’ve seen so far is really just to provide a foundation for studying computability and complexity, while the concern of programming languages is for humans to express powerful computations. Programming languages feature extremely rich syntaxes and complex semantics, and introduce us to two worlds: the static and the dynamic.
PLT is a significant and very active branch of computer science that deals with everything about programming languages, including their design, classification, implementation, interpretation, translation, analysis, features, expressiveness, limitations, syntax, semantics, and so on. It is concerned with:
Syntax
How do we formally specify the structure of programs?
Semantics
How do we formally specify the meaning of programs?
Type Theory
How do we classify constructs and entities in our programs (by their structure and behavior)?
Static Analysis
What can we say about a program just by looking at it (without running it)?
Translation
How do we construct compilers (translators) and interpreters (executors)?
Runtime Systems
What do programs look like at runtime, and what do we need to execute them?
Verification
How do we mechanically prove program properties, such as correctness and security?
Metapro-
gramming
How do we write programs that operate on, and generate, other programs?
Classification
On what bases can we rigorously classify PLs in meaningful ways?
Basically, anything in the study of Programming Languages seems to fall under the topic of PLT. But in the popular culture, the PLT community seems to be associated with the most theoretical, the most mathematical, the most foundational. PLT people write papers whose formulas have a lot of Greek letters. Logic and category theory are everywhere. And when it comes to actual programming, the PLT community is all over the most cutting-edge stuff, like dependent types. And they appear to favor functional programming languages. Haskell, Scheme, and the ML Family of Languages show up a lot in current research. So do proof assistants, like Agda, Coq, and Lean.
This is good, though.
PLT is a huge field but there is good news for students: Some one has already built, and is currently maintaining, a most excellent curated portal for PLT. So many great links to books, papers, articles, tutorials, and even to other portals! Browse and lose yourself in the good stuff.
You can also begin a journey at Wikipedia’s PLT article.
Applications
Formal language theory (and programming language theory) are used in:
- Programs that process other programs, such as syntax highlighters, data validators (e.g., for JSON), compilers, interpreters, debuggers, profilers, linters, security analyzers, optimizers, and more.
- Logic, mathematical linguistics, computational linguistics, cryptography, compression.
- The design of domain-specific languages, such as network protocols, information retrieval and search engines, human-computer interaction models, robotics, game development, automated theorem proving systems, hardware and software verification.
- Natural Language Processing (NLP) systems, for modeling and analyzing human languages, speech recognition, machine translation, sentiment analysis, chatbots, and virtual assistants.
- Biology and bioinformatics, for modeling genetic sequences and protein structures.
- Chemistry and computational chemistry, for modeling molecular structures and reactions.
Really, any application that deals a lot with patterns benefits from formal language theory.
You can find a list of application on Wikipedia’s formal language article as well as on this Reddit discussion.
Recall Practice
Here are some questions useful for your spaced repetition learning. Many of the answers are not found on this page. Some will have popped up in lecture. Others will require you to do your own research.
- Why do we need a theory of language? A theory of language allows us to rigorously define exactly how we may express and transmit information.
- What is information and how do we conventionally represent it? Information is that which informs. Technically, it can be defined as a resolution of uncertainty. We represent it with a string of symbols.
- What is an alphabet, in language theory? A finite set of symbols.
- What is a string, in language theory? A finite sequence of symbols over a given alphabet.
- How do we denote the empty string (the string of zero symbols)? $\varepsilon$
- What is $|abbabcb|$? 7
- How do we denote the concatenation of two strings $x$ and $y$? $xy$
- What is $ho^3$? What is $(ho)^3$ $hooo$
$hohoho$ - Why is the traditional representation of concatenation and repetition so annoying? String concatenation is written like multiplication, but it is really a kind of addition. String repetition is written like exponentiation, but it is really a kind of multiplication.
- What are the substrings of $abc$? $\varepsilon$, $a$, $b$, $c$, $ab$, $bc$, $abc$.
- What is a language, in formal language theory? A set of strings over some finite alphabet.
- What do we call a member of a language? An utterance.
- What are the first few strings in the language $\{a^nb^n \mid n \geq 0\}$, ordered by increasing length? $\varepsilon$, $ab$, $aabb$, $aaabbb$, $aaaabbbb$, ...
- What are the first few strings in the language $\{a^ib^j \mid j = 2^i\}$, ordered by increasing length? $b$, $abb$, $aabbbb$, $aaabbbbbbbb$, $aaaabbbbbbbbbbbbbbbb$, ...
- What is the difference between $\varnothing$ and $\{ \varepsilon \}$? The former is the language of zero strings; the latter is a language with one string, namely the empty string.
- How do the Kleene Closure and the Positive Closure of a language differ? The Kleene Closure includes the empty string; the Positive Closure does not.
- How do we denote the concatenation of two languages, $L_1$ and $L_2$? $L_1L_2$
- What is $\{a, b, c \}^2$? The set of all strings of length 2 over the alphabet $\{a, b, c\}$, namely $\{aa, ab, ac, ba, bb, bc, ca, cb, cc\}$.
- If $A$ was the alphabet $\{a, b, c\}$, what is $A^2$? $A^2$ is the set of all 2-letter words that can be formed from $A$, i.e., $\{aa, ab, ac, ba, bb, bc, ca, cb, cc\}$.
- What is $\{1,2\}^*$, assuming this set is NOT an alphabet or language, but just a regular set? $\{(), 1, 2, (1,1), (1,2), (2,1), (2,2), (1,1,1), (1,1,2), (1,2,1), (1,2,2), (2,1,1), \ldots \}$
- For language $L$, what are $L\varnothing$ and $L\{\varepsilon\}$? $\varnothing$ and $L$, respectively.
- What are the two means by which we can formally, but “computationally,” define a language, other than listing all the strings or providing a description with a set comprehension? By generation or recognition.
- What is the primary mechanism for which languages are described by generation? The generative grammar.
- What are variables in a generative grammar? Symbols that are distinct from those symbols in the language that the grammar is defining, that are intended to be replaced by (strings of) symbols in the process of generating strings in the language.
- What do the metacharacters $|$, $*$, $+$, and $?$ mean in a generative grammar? Alternation (OR), repetition (Zero-or-more), positive repetition (One-or-more), and optional (Zero-or-one), respectively.
- In what sense does a generative grammar define a language? It defines the language as the set of all strings that can be derived from the start variable using the production rules.
- How do we denote the language defined by grammar $G$? $L(G)$
- When taking about grammars, we sometimes see the metacharacters $\longrightarrow$ and $\Longrightarrow$. What do they mean? The former is used to denote a rule in a grammar; the latter is used to denote a derivation step.
- When does a derivation in a generative grammar “stop”? When there are no more variables.
- How can we concisely and formally describe the language over the alphabet $\{a,b\}$ whose utterances contain all and only those strings made up of several $a$'s followed by the same number of $b$'s? $\{a^nb^n \mid n \geq 0\}$
- What is the single rule in the generative grammar defining the language of positive odd binary numerals? $odd \rightarrow (\texttt{"0"} \mid \texttt{"1"})^*\;\texttt{"1"}$
- What language is defined by the following generative grammar?
$\;\;s \longrightarrow \texttt{"a"}\;s?\;\texttt{"b"}$
$\{ a^nb^n \mid n \geq 1 \}$ - How do you write a grammar for the language of nested and balanced parentheses? $s \longrightarrow (\texttt{"("}\;s?\;\texttt{")"})^*$
- What language does the grammar
s → s* | "(" s ")" | "[" s "]" | "{" s "}"define?The language of properly nested and balanced brackets. - Why was writing the generative grammar for $\{ a^nb^nc^n \mid n \geq 0 \}$ conceptually harder than writing the grammar for $\{ a^nb^n \mid n \geq 0 \}$? Because the former requires left hand sides with multiple symbols.
- What are some predefined variables that are often used in grammars? $digit$, $hexDigit$, $letter$, $alnum$
- For the grammar
$\;\;s \longrightarrow \texttt{"a"}\;s?\;\texttt{"b"}$
what does the derivation tree for the string $aabb$ look like?s / | \ a s b /|\ a s b | - The grammar
$\;\;s \longrightarrow x \mid y$
defines a language with exactly one utterance, namely $ab$. But there are two possible derivations. Show them.
$\;\;x \longrightarrow a$
$\;\;y \longrightarrow b$- $s \Longrightarrow xy \Longrightarrow ay \Longrightarrow ab$
- $s \Longrightarrow xy \Longrightarrow xb \Longrightarrow ab$
- What does it mean for a grammar $G$ to be ambiguous? There exists a string in $L(G)$ with more than one derivation tree for $G$.
- What are the four components of the mathematical structure representing a formal, generative grammar? The structure is $(V, \Sigma, R, S)$ where $V$ is the set of variables, $\Sigma$ is the alphabet over which the language is defined, $R$ is the set of rules, and $S$ is the start symbol.
- In a generative grammar, $(V, \Sigma, R, S)$, we require $R \subseteq (V \cup \Sigma)^*V(V \cup \Sigma)^* \times (V \cup \Sigma)^*$. Explain this requirement. Rules map over strings of variables and language symbols (that is, strings from $(V \cup \Sigma)^*$), but the left hand side MUST have at least ONE variable.
- Why does the formal definition of a grammar not include $?$, $*$, $+$, or $\mid\,$? Because when doing super theoretical meta-level work, brevity and simplicity are key. We want the smallest possible number of building blocks to simplify discussions about what grammars are. We can define these constructs in terms of the basic constructs.
- How is the derivation relation $\Longrightarrow_{\small R}$ in a generative grammar formally defined? $\{ (xwy, xzy) \mid w R z \}$
- What are alternate terms used by different authors for “variable” and language symbol”? “Nonterminal” and “terminal”
- What do we call the union of variables and language symbols? The vocabulary
- A grammar is a special case of, but far more useful than, a ________________. String Rewriting System
- What do we call a language that can be generated by some generative grammar? A recursively enumerable language.
- Are there languages that we can precisely describe but cannot give a grammar for? Yes.
- Are there languages that cannot even be described? Yes. Descriptions are strings and therefore countable, but the set of all languages, even over a given alphabet, is uncountable.
- Chomsky put a series of three restrictions on grammars. Why? He wanted to make structure things so that the structure of a string as derived by the grammar could be uncovered and analyzed.
- What was the restriction Chomsky placed on a grammar to arrive at a Type-1 Grammar? That a grammar rule specify the replacement of a single variable with a nonempty string of symbols and variables. (The left hand-side of a rule can be arbitrarily complex, but the only difference between the LHS and RHS is in the replacement of a single variable.)
- What was the restriction Chomsky placed on a grammar to arrive at a Type-2 Grammar? That the left hand side of every rule be a single variable.
- How do Chomsky’s formulation of grammars and language classes different from modern formulations? These days we are fine with empty strings being in a language.
- What is a context-free grammar (CFG)? A restricted form of a generative grammar in which the left hand side of every rule is a single variable.
- What is a right-linear grammar (RLG)? A restricted form of a generative grammar in which the right hand side of every rule is a string of zero or more symbols followed by at most one variable.
- What is an essentially noncontracting grammar (ENCG)? A restricted form of a generative grammar in which the right hand side of every rule never has fewer symbols and variables than the left hand side, with one exception: if the language contains the empty string, we can have one rule that maps the start symbol to the empty string.
- What is the Chomsky Hierarchy? The arrangement of language classes in terms of expressive power: $REG \subset CF \subset CS \subset RE$
- Arrange $RE$, $CS$, $CFL$, and $REG$ in subset order. REG $\subset$ CF $\subset$ CS $\subset$ RE
- What is the difference between a generative and an analytic grammar? Generative grammars generate all and only the strings in a language. Analytic grammars define a process to determining whether a candidate string is in the language or not.
- What is the language defined by the analytic grammar $s \longleftarrow \texttt{"a"}\;/\;\texttt{"ab"}$? The language $\{ a \}$. (Importantly $ab$ is not in the language because when presented with that string, the grammar matches the $a$ part and will not backtrack to try the second alternative.)
- Although analytic grammars have only a single variable on the left hand side of each rule, how can they define non-context-free languages? By using lookahead operators.
- What is semantics concerned with? The meaning of utterances in a language.
- What is the difference between a number and a numeral? A number is an abstract concept; a numeral is a representation of a number.
- What are some of the concerns of PLT? Try to name at least five. Syntax, Semantics, Type Theory, Static Analysis, Translation, Runtime Systems, Verification, Metaprogramming, Classification.
- Who is the curator of the GitHub portal for PLT? Steven Shaw
Summary
We’ve covered:
- Symbols, alphabets, and strings
- Formal Languages
- Generative Grammars
- Parse Trees
- Ambiguity
- The formal definition of a grammar
- Context-Free, Right-Linear, and Essentially Noncontracting Grammars
- The Chomsky Hierarchy
- Analytic Grammars
- What Programming Language Theory is concerned with
- Applications